



5.3 领域本体非等级关系获取
5.3.1 基于统计的非等级关系获取方法
基于统计的领域关系获取方法是根据数据挖掘中基本的关联规则挖掘算法原理,从农学语料文本中抽取所有关系密切的概念对为农学领域关系的构建提供参考。由于没有精确的语言模型的支持,得到的概念对之间的关系比较抽象和宽泛,需要人工加以审核和确定,但是这种方法可以获取大量的相关有效概念对,是农学领域概念关系获取的有效来源支持数据之一。
(1)方法原理
关联规则挖掘用于寻找给定数据集众数据项之间的有趣的关联或者相关关系。关联规则揭示了数据项之间的未知依赖关系。关联规则的挖掘通过规则的支持度和置信度进行兴趣度度量,来反映所发现规则的有用性和确定性[31][32]。
关联规则挖掘的基本算法是:给定一个交易集T={ti|i=1,2,…,n},其中,每个交易是一个项目集ti={ai,j|j=1,2,…,n,ai,jC},C是项目名称的集合。关联规则Xk→Yk(Xk,Yk∈C,Xk∩Yk={ })的支持度(support)被定义为交易集中包含Xk∪Yk的交易所占有的百分比,而Xk→Yk的可信度(confidence)被定义为当Xk在交易中出现时,Yk出现的频率,即:
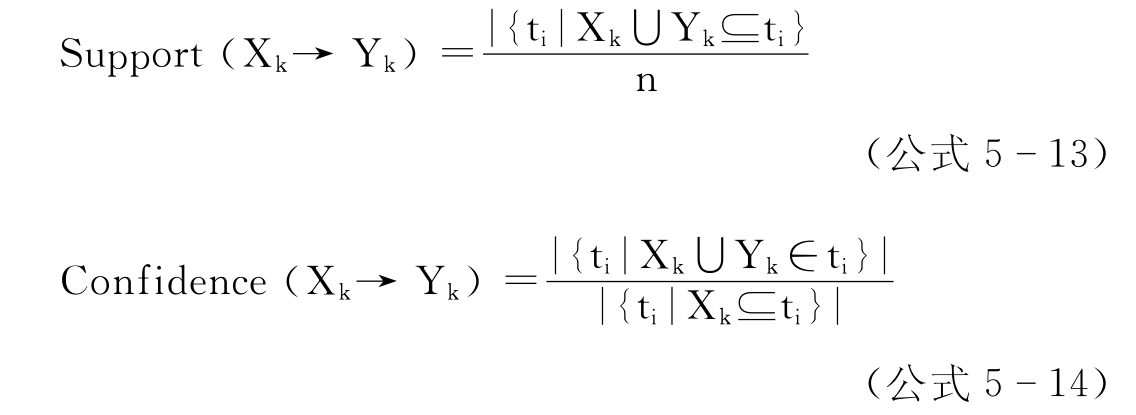
(2)算法流程
根据关联规则挖掘的基本原理,在农学概念对挖掘中,支持度为两概念对同时出现的频次与总频次的比值,而置信度则为两概念对同时出现的频次与后一个概念出现的频次的比值。若想挖掘到的概念对是有趣的,需要满足最小的兴趣度和置信度阈值。整个算法流程如下:
(1)任意选取两个概念c1、c2,使得c1≠H(c2),且c2≠H(c1),若不存在这样的概念,转步骤(5);
(2)按式(8)计算support(c1→c2),若support(c1→c2)<ksupport,转步骤(1);
(3)按公式(9)计算confidence(c1→c2),若confidence(c1→c2)<Kconfidence,转步骤1;
(4)将(c1→c2)加入规则库,转步骤(1);
(5)结束。
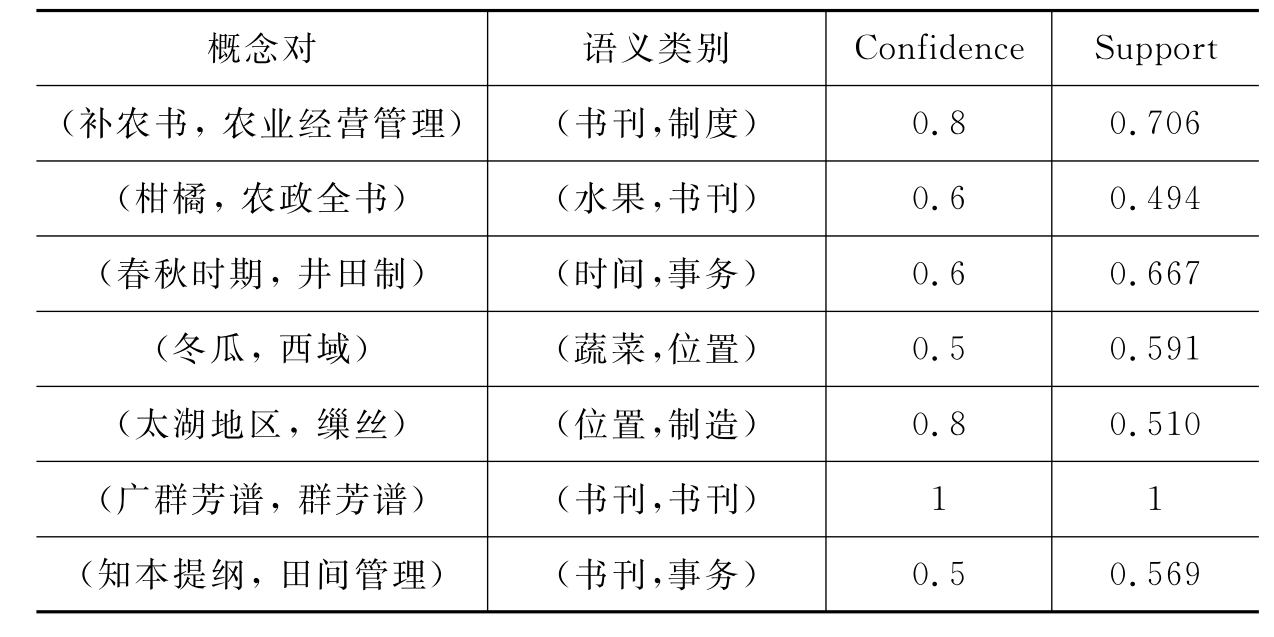
选取了1 642篇农史研究文本,以每篇文本为统计单位,对1 642篇文本进行主题标引(主题标引的方法同领域概念筛选方法一致),抽取权值排在前20位的关键词,进行频次统计,计算支持度和置信度,经过阈值过滤,最后共保留了6 314个概念对。其中抽取的概念对样例如表5-5所示。
表5-5 基于关联规则的概念对获取样例
5.3.2 基于自然语言处理的非等级关系识别方法
基于自然语言处理的识别方法,主要是利用汉语的语法知识从汉语语料中抽取主、谓、宾模式构成三元组为领域关系的构建提供有力的参考[33—35]。识别方法首先利用标注软件对农学文本语料进行词形标注,根据句法规则抽取其中的主谓宾三元组模式,同时对主语和宾语进行语义类别标注。
1 自然语言处理工具——“语言技术平台LTP”介绍[36]
“语言技术平台LTP”是哈尔滨工业大学信息检索研究室向学术界免费共享的自然语言处理工具。整个平台分为中文分词、词性标注、命名实体、词义消歧、句法分析、语义分析、指代消歧、自动文摘以及文本分类九个模块构成。现将本研究中使用的主要模块做简要介绍:
(1)词法分析模块
词法分析系统IRLAS具有分词、时间数词识别、未登录词识别和词性标注等功能,支持多线程,具有良好的可配置性和健壮性。
(2)命名实体模块
命名实体识别系统可识别人名、地名、机构名、专有名词、时间、日期、数量短语等七类实体。
(3)句法分析模块
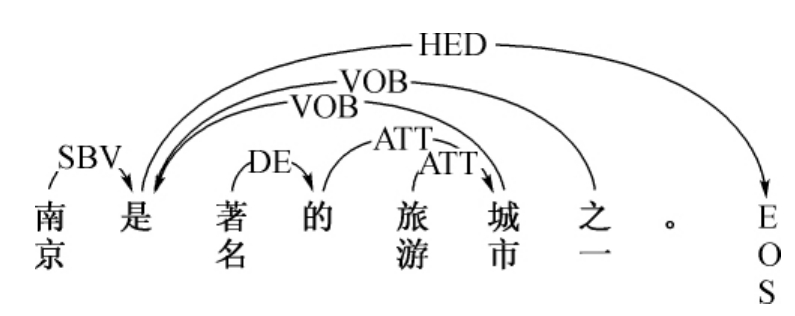
依存句法分析系统用于对汉语进行句法分析,将句子由一个线性序列转化为一棵结构化的依存分析树,通过依存弧反映句子中词汇之间的依存关系,例如:“南京是著名的旅游城市之一”,依存分析的结果如下:
(4)语义分析模块
找到给定输入句子中所有动词的句法成分,并且用一定的语义角色参数来填充这些句法成分,最后输出能在一定程度上反映句子意义的某种表示形式。对于给定的句子,标注所有动词的句法成分为对应的语义角色类型。目前模块只标注7类语义角色:施事,受事,数量词性质的施事和受事,附加成分时间、地点和方位。
(5)指代消歧模块
对文本中出现的第三人称代词单数形式“他”或“她”进行消解,识别出代词所指的人的姓名。指代消解功能举例:
《齐民要术》是一部综合性农书,它成书于北魏。
其中,“它”指的是“齐民要术”。指代消解的工作就是识别出这种指代关系。
2 方法概述
本研究提出的基于自然语言处理的领域概念关系识别方法,基本思想是根据汉语“主谓宾”形式的联合关系,其中主语和宾语作为关系的两个概念,谓语作为语义关系。例如,“贾思勰撰写了《齐民要术》”是一句完整的主谓宾语句。主语“贾思勰”和宾语“齐民要术”是两个农史中的概念,而谓语“撰写”是作者和作品的写作关系,因此可以从这句话中提取出“人物(贾思勰)撰写作品(齐民要术)”关系的一个实例。
提取的方法是首先对农史语料进行标注,包括分词以及浅层次的句法分析。根据汉语的句法规则,从标注后的语料中,提取出可能的“主谓宾”模式的语料存入语料库。然后对谓语(也就是动词以及动词短语)进行聚类分析,将含义相同的动词集中,例如,“记载、阐述、论述、描写”这些动词都表达了相近的含义,用法也基本相同。与此同时对这些动词的用法进行总结,例如“书籍/人物记载主题”,利用《知网》对主语和宾语进行类别标注,例如“贾思勰/人物小麦/农作物”,最后对标注、抽取后的“主谓宾”关系进行筛选归纳得出领域相关关系实例。主要抽取步骤见图5-9。
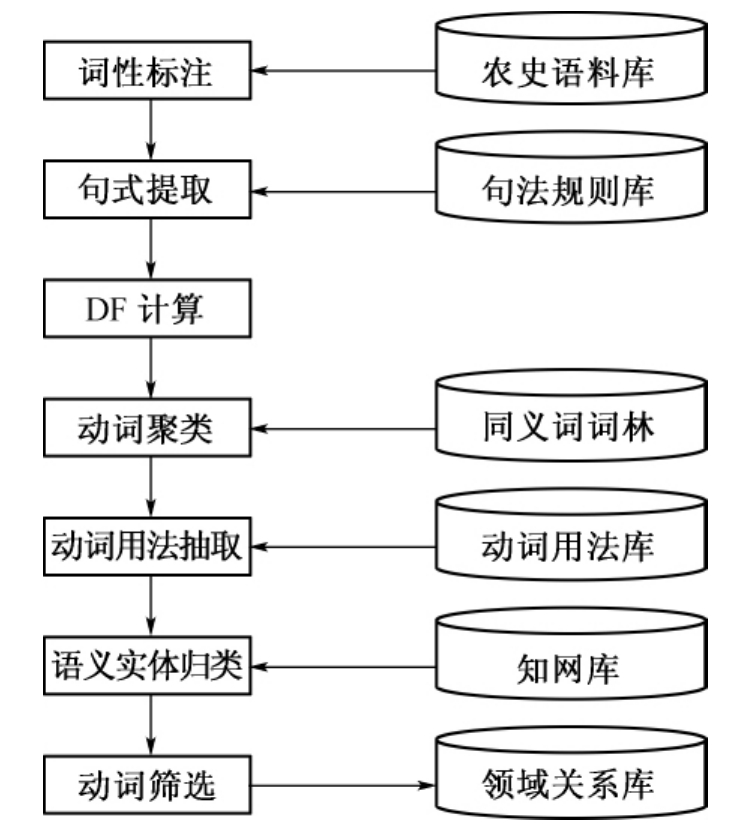
图5-9 基于自然语言处理的领域关系抽取流程图
(1)语料标注
表5-6 词性标注体系符号[37]
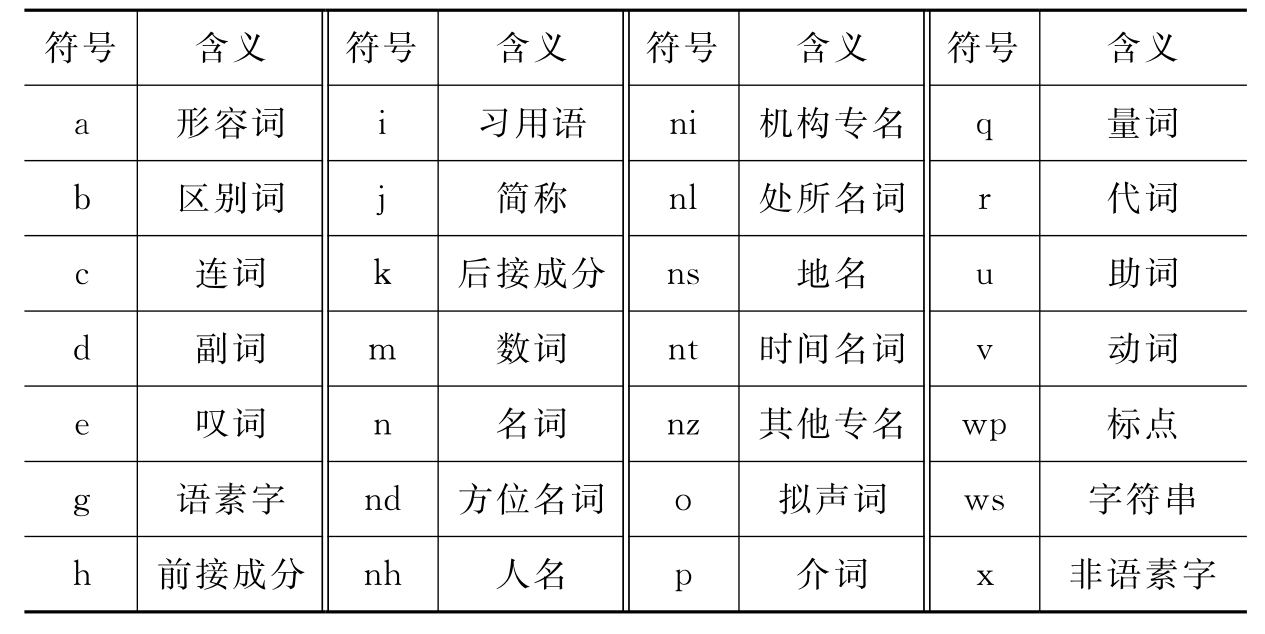
例如,有下段文本:
甘薯自明万历初中期由海外传入我国后,主要局限于南方各地传播种植,北方地区冬季严寒干燥,在当时还没有解决薯种越冬技术的情况下,甘薯始终没有能在北方地区一带扎根落户。
经过LTP标注后的结果如下:
甘/a 薯/n 自/p 明/nt 万历/nt 初/nd 中期/nd 由/p 海外/nl 传入/v 我国/n 后/nd ,/wp主要/d 局限/v 于/p 南方/nl 各地/r 传播/v种植/v ,/wp 北方/nl 地区/n 冬季/nt 严寒/a干燥/a ,/wp 在/p 当时/nt 还/d 没有/d 解决/v 薯/n 种/v 越冬/v 技术/n 的/u 情况/n 下/nd ,/wp 甘/a 薯/n 始终/d 没有/d 能/v 在/p 北方/nl 地区/n 一带/n 扎根/v 落户/v 。/wp
(2)句式提取(抽取框架)
在汉语中,句子主要有主语、谓语和宾语三种主要成分构成,动词是语言中最重要的词汇和句法分类,在句子中占据核心地位,并且起到句子主要组织者的作用,提供了句子的关系和语义框架。由于汉语语言的灵活性,三种成分有不同的灵活组合方式,然而本研究的研究语料是农业史研究论文,属于科技论文范畴,这类文章撰写的风格较为固定,大都采用规范的主语+谓语+宾语的造句方式,因此,在本论文中,主要研究主语+谓语+宾语顺序结构的句子。
根据现代汉语语法功能[38],一般表中的体词的主要语法功能是作主语、宾语,一般不作谓语。谓词的主要功能是作谓语,作主语和宾语的概率很小。其中名词是表示人、事物或概念的词,在句法功能上,名词经常与动词发生施事、受事关系,主要充当主语、宾语和定语。时间名词、处所名词、方位词、方位短语都可以充任主语动词是表示动作、行为、心理活动或出现、变化、消失等的词。动词的主要句法功能是作谓语。
通常充任主语和宾语的主要成分是[37][38]:
①名词/名词短语
②主谓结构
③述宾结构
④述补结构
⑤连谓结构
⑥名动词
⑦名形词
⑧状中结构
⑨定中结构
⑩名动词
 名形词
名形词
充任谓语的主要成分是充当成分动词/动词短语,还可以扩展:
①动词本身可以受“很/极/极其/非常/太”一类程度副词修饰。
②动词能够后接时态助词“着/了/过”。
③动词本身或带上宾语以后可以受副词“在”或“正在”修饰。
在上述句法的基础上,建立了58种正则表达式抽取规则,利用正则表达式从标注文本中抽取句子成分。现抽取部分正则表达式规则做简要解释[39][40]:
规则1:
\s+([\u4e00-\u9fa5]+)/n\s+([\u4e00-\u9fa5]+)/v\s+([\u4e00-\u9fa5]+)/n
这条规则是针对主语是名词,谓语为动词,宾语为名词的情况。
例如:玉米螟/n 危害/v 玉米/n
茶道/n 源于/v 中国/n
规则2:
\s+([\u4e00-\u9fa5]+)/nt\s+([\u4e00-\u9fa5]+)/n\s+([\u4e00-\u9fa5]+)/v\s+([\u4e00-\u9fa5]+)/v\s+([\u4e00-\u9fa5]+)/n
这条规则是以抽取主语为时间名词词组,宾语为动名词组的情况。
例如:西汉/nt 时期/n 发明/v 水稻/n 育秧/v
三国/nt 时期/n 发明/v 稻田/n 养鱼/v
南北朝/nt 时期/n 发明/v 果树/n 嫁接/v
规则3:
\s+([\u4e00-\u9fa5]+)/n\s+([\u4e00-\u9fa5]+)/v\s+([\u4e00-\u9fa5]+)/n\s+([\u4e00-\u9fa5]+)/n
该条规则是以抽取主语为名词,宾语为名词词组的情况。
例如:真宗/n 推广/v 占城/n 稻/n
休耕/n 保持/v 土壤/n 肥力/n
规则4:
\s+([\u4e00-\u9fa5]+)/nh\s+([\u4e00-\u9fa5]+)/v\s+([\u4e00-\u9fa5]+)/vn\s+([\u4e00-\u9fa5]+)/n
该条规则是以抽取主语为人名,宾语为动名词组的情况。
徐光启/nh 记载/v 引种/vn 技术/n
袁隆平/nh 推广/v 杂交/vn 水稻/n
此外,还有其他“主谓宾”句法情况,例如:
夏商时期/出现/青铜工具、桔槔/用于/灌溉农田、木耳丸/治/寒湿性疾病、莆田/引种/番薯、储存设施/有/冷藏地窖、茶叶/防治/心脑血管疾病、茉莉花/用于/制造茶叶等等。
(3)动词聚类
①目的意义
汉语中有许多用法意义相同的动词,即这些动词有着相似的含义,连接着同一类的主语和宾语,因此将这些动词划分成若干个组(类别),将会简化主谓宾的归类提取工作。在语言学的研究中,学者们已经对各种词汇以及用法做了总结,形成了许多工具书。在这些工具书的基础上动词的聚类实现将会容易和精确许多。这里,我们使用了《同义词词林》来实现对动词的聚类。
②《词林》简介
《同义词词林》[41]是一部对汉语词汇按语义全面分类的词典,收录词语近7万,1983年出版了第一版,1996年出版了第二版。《词林》根据汉语的特点和使用原则,确定了词的语义分类原:以词义为主,兼顾词类,并充分注意题材的集中。它将词义分大、中、小类三级,共分12个类,其中A类为人,B类为物,C类为时间与空间,D类为抽象事物,E类为特征,F类为动作,G类为心理活动,H类为活动,I类为现象与状态,J类为关联,K类为助语,L类为敬语。A—D类大多属于名词,数词与量词列入D大类,E大类多属于形容词,F—J类多属动词,K多属虚词,L为难以分到其他类别的客套语。共94个中类,1 428个小类,小类再以同义原则划分词群,每一词群以一标题词立目,共3 925个标题词。
③相似度算法[42]
先将《词林》分类体系对应的语义编码体系进行如下描述:
[语义编码] (大类)(中类)(小类)(小组)
(大类)(中类)(小类)(小组)
大类(大写英文字母)
中类(小写英文字母)
小类(数字)(数字)
小组(数字)
为了方便计算,增加一个虚拟的总结点O,以便可以构成一棵完整的语义体系树。
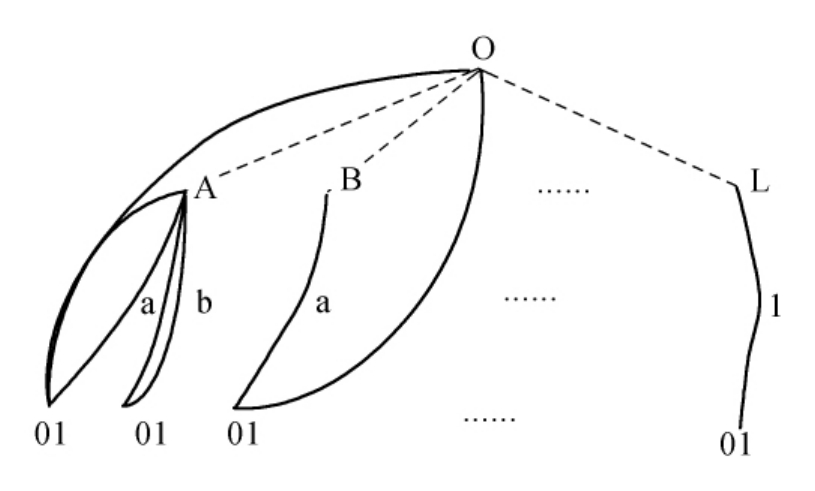
图5-10 《同义词词林》语义计算示意图
定义两语义编码S1和S2间的语义距离D(S1,S2)为在该树形图中,从节点S1到S2的最短路径的长度,则语义编码S1和S2之间的语义相似都可以通过公式5-15计算完成,即认为词汇间的语义相似度与语义距离成反比。
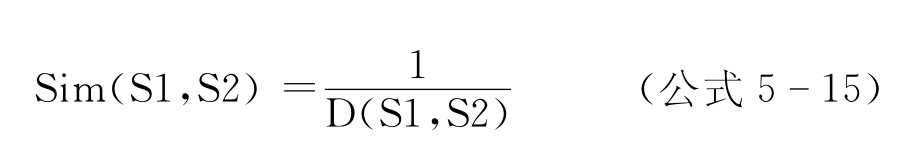
若D(S1,S2)=0,则令Sim(S1,S2)=1
例如,治理的语义代码为Hc01,管理的语义代码为Hc02,则两个词的相似度为:
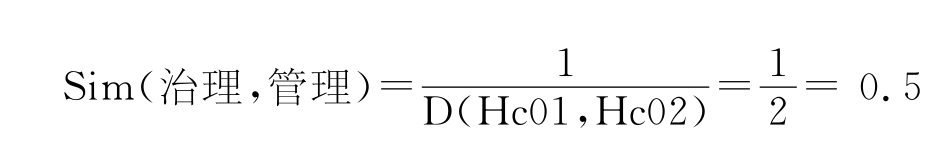
嫁接、压条的语义代码都为Hd22,则两个词的相似度为:
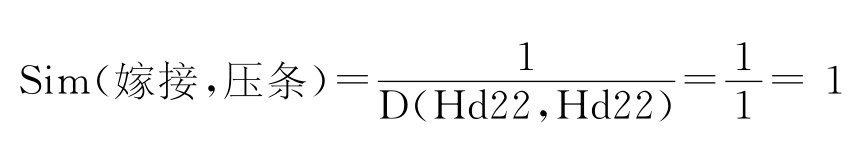
在本研究中我们提取相似度大于0.5的动词作为相似动词。给出部分样例:
1 促使、使得、得以、致使、有利于、促进
2 介绍、提出、记载、阐述、论述、描写、记载、收载、叙述、陈述、阐发
3 栽培、栽植、栽种、种植、移栽
4 搬运、调运、贩运、海运、河运、水运、漕运
(4)动词用法提取
动词一般能带体词性的、谓词性的还是准谓词性的宾语,对于我们来说主要是提取主谓宾形式的语料,因此主要是处理带体词性宾语的动词。体词性宾语可能担任的语义角色“受事、结果、与事、工具、方式、处所、时间、目的、原因、致使”等。
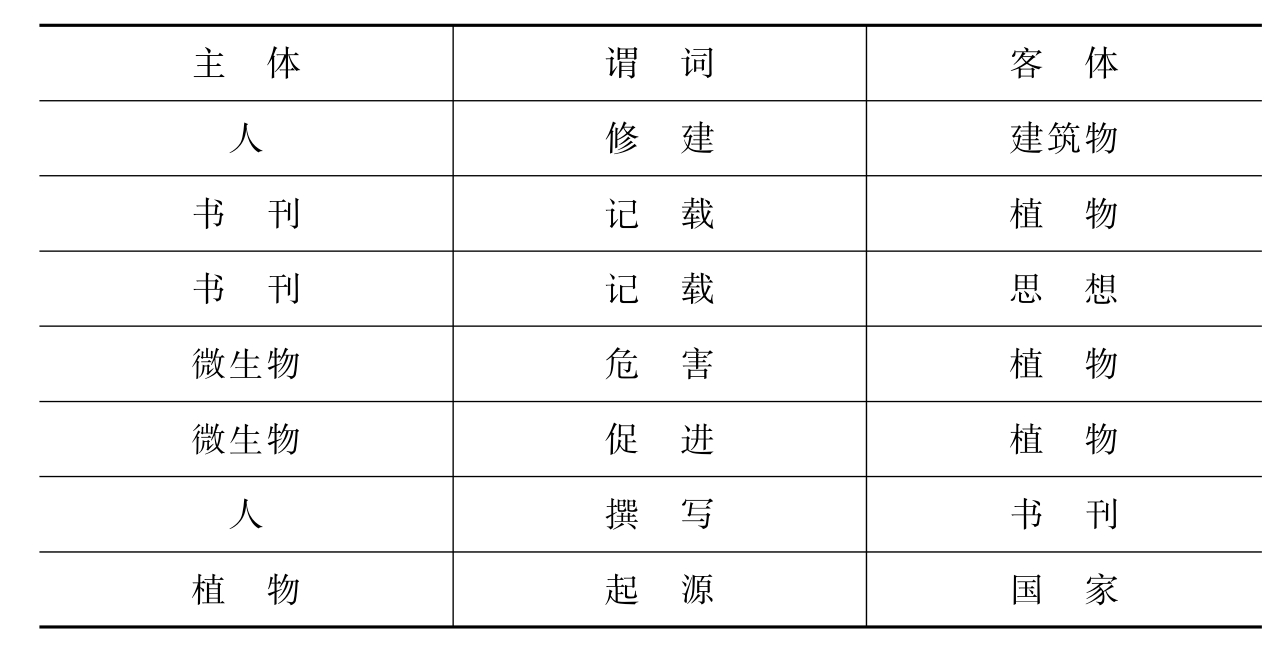
根据[43][44]对带体词性宾语的动词后接词语进行统计归类,总结其所属的语义类。同时,利用《知网》[45]对体词性动词的前后成分进行聚类和归纳。
表5-7 体词性谓词用法示例
(5)动词筛选
汉语中有些经常出现的动词,对于领域来说没有实际意义,因此需要对标注后的语料进行动词筛选,获取对于领域本体构建有意义的动词。筛选的方法一是获取对领域文本主题表达有意义的动词,主要采用动词领域特征值来过滤,二是要获取带体词性谓语的动词。
本文提出用动词领域特征值(Domain Feature,DF)来衡量动词在该领域中的表达能力,即一个动词的领域特征值越大,则该动词在领域中的表达能力越强。DF与两个因素有关:动词的频次之和与该动词一同出现的语义实体(名词)的权值。如果一个动词出现的频次越高,那么它的重要性可能越高;同时与该动词一起出现的语义实体如果都是领域关键词,那么则说明该动词是该领域表达能力强的动词。本文给出DF的计算公式如下:
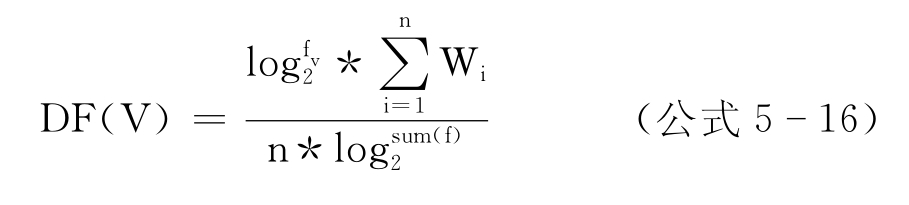
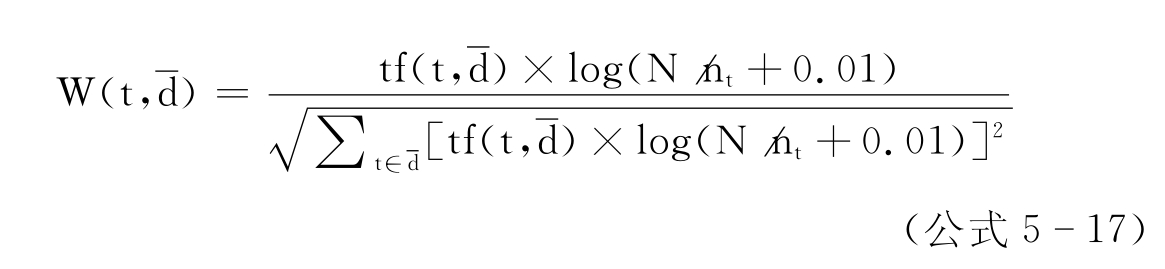
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











