



5.2.2 数据选取和回归方法
5.2.2.1 数据选取
本章对中国31个省(直辖市)[6]在1978—2006年度的工业集聚影响因素进行计量检验。各年度各省(直辖市)工业产值占当年全国总的工业GDP的比重(Yit)的数据来源为:(1)1978年至1986年和1999年至2006年的数据取自《中国统计年鉴》。(2)1987年至1998年的数据如未经指明均取自《新中国五十年统计资料汇编》。
解释变量中的区位因素Ri,本书和大多数研究中国地区差异的文献一样,使用了沿海(C)或内地(I)的虚拟变量。考虑到经济政策因素Pi,t-1中的时间因素,对相应变量作了滞后一期的处理,以减少模型的联立性偏误。具体数据来源为:(1)各省进出口数据T经过当年人民币与美元的比价的中间价折算为人民币,折算时所用的各年汇率取自相应年份的《中国统计年鉴》。(2)各省政府支出(扣除科教文卫支出)在GDP中的比重与全国均值之比(G)的数据来自相应年份的《中国统计年鉴》。
5.2.2.2 回归方法
本章采用的是31个省(直辖市)1978—2006年的面板数据。面板数据中包含着时间序列因素,因此需要考虑自变量和因变量的非平稳性及其协整关系。如果变量是非平稳的,对这些变量进行简单的回归会产生伪回归,使得检验结果并不可靠。本章采用一种相对较简单的非平稳数据序列处理方法,即直接对式(5.5)中的各项作一阶差分[7],然后再进行回归检验。此时的检验方程为:
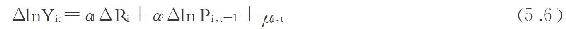
式(5.6)即为本章实际进行检验的方程。对面板数据的回归分析,通常采用混合数据普通最小二乘估计(pooled OLS)、固定效应模型(fixed effect)和随机效应模型(random effect)等三种模型来同时进行估计,然后再根据估计结果进行比较和取舍,从而得出最终的结果。这三个模型的差异在于:混合数据普通最小二乘估计假定所有的省份数据都是同质的,即不考虑省份之间的差异;固定效应模型和随机效应模型都考虑到了不同省份数据之间的差异,二者的区别在于,随机效应模型假定省份数据之间的差异服从某一随机分布,可以用一个随机变量来表示,而固定效应模型则假定这种差异是固定不变的,可以用一系列省份数据的常数来表示。
面板数据同时包含了时间序列因素和横截面因素,因此,参数的估计值可能会同时受到两种不同因素的影响。一种是不同组别数据之间的差异,通常被称为组间效应(between effect),在本章的研究中就是指不同省际间的差异;另一种是同一组别内部在不同时间点上数据之间的差异,通常被称为组内效应(within effect),在本章的研究中就是指同一省份在不同年份之间的差异。由于上述三个模型在估计时使用了不同的原假设,因此采用三种模型分别估计出来的α1和α2值所包含的影响因素也有所不同。混合数据普通最小二乘估计因为没有考虑省际间差异的存在,所以估计出来的α1和α2值由组间效应和组内效应共同决定。在固定效应模型的回归过程中,所有的组间效应都通过固定影响被消除掉了,因此,估计出来的α1和α2值只受到组内效应的影响,即每一省份在不同年份是否有差异。而随机效应模型在回归的过程中虽然考虑到了省际间差异的存在,但只有当省际间的差异服从正态分布时,估计出来的α1和α2值才会完全不受这种组间效应的影响,一旦这个条件不成立,α1和α2值也可能会同时受到组间效应和组内效应的影响。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










