



11.2 单变量描述分析
一般而言,现代科学的主要目标就是发现事物间的因果关系。也只有发现了不同变量之间存在的因果关系,才能预测事物变化趋势,才能指导人们的日常行为与活动。探索事物的因果关系可以说是自然科学的核心议题,但是对社会科学而言,由于影响事物变化的外部变量实在太多,无法像自然科学如生物学实验那样能够严格控制外界环境因素,因此,除了探索社会现象中的因果关系之外,社会科学另一个研究中心就是发现现象之间的相关关系,即两个现象之间存在某种统计学上的关联性。无论是探索因果关系还是发现相关关系,都需要借助于变量手段进行分析。当前,多变量分析是大多数社会科学分析都在使用的量化分析技术。这种技术主要是同时检验数个变量之间的关系,如人们分析收入与年龄、文化程度以及性别之间的关联性等。当前,多变量分析并非特指某种具体的量化分析技术,而是一个概括性名词,包括了因素分析、复相关分析、多元回归分析、路径分析等多种分析技术。但是,多变量分析的基本逻辑来自于列联表或交叉表技术。如果不了解一些最基本的分析模式,如单变量分析与双变量分析技术,那么,就无法完全了解多变量分析。因此,我们首先介绍最基本的单变量分析技术。
11.2.1 单变量统计分析
描述统计的主要目的在于用最简单的概括形式来反映大量数据资料容纳的基本信息,总结数据资料及表征数据的简要特性,主要包括集中趋势分析和离中趋势分析等内容。
1.集中趋势分析
从根本上看,主要的统计技术处理的实质问题就是发现相关变量数据的集中趋势和离散趋势这一对对立统一的概念。在统计学中,集中趋势指的是一组数据向某一中心值靠拢的程度,它反映了一组数据中心点的位置所在,集中趋势分析就是寻找数据水平的代表值或中心值,最常见的集中趋势分析主要包括平均数、众数和中位数等统计指标。它们都是描述一组数据集中趋势的统计量,但描述的角度和适用范围有所不同,在具体的问题中究竟采用哪种统计量来描述一组数据的集中趋势,要根据数据的特点及我们所关心的问题来确定。
(1)平均数(Mean)
在集中趋势分析工具中,平均数是运用最多的集中量数,用它作为一组数据的代表,比较可靠和稳定。由于它与这组数据中的每个数据都有关系,因此,能够最为充分地反映这组数据所包含的信息。具体而言,平均数指的是“总体各单位数值之和除以总体单位数目之商”。(4)在统计分析中,习惯用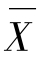 表示,其公式为:
表示,其公式为:
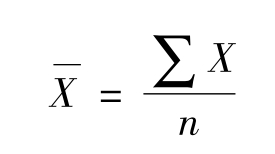
如果是单值分组数据,那么,计算平均数时需要将每一个变量值乘以其所对应的频数f,得出各组的数值之和,然后将各组的数值之和全部相加,最后除以各组频数之和。其计算公式为:
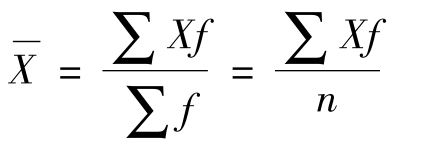
假设有一组青少年分组数据,其年龄情况如下:

那么,根据公式,这一组青少年的平均年龄为:
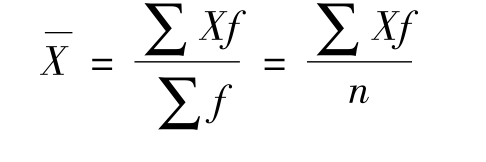
![]()
用平均数表示一组数据的情况,有直观、简明的特点,因此,在日常生活中人们经常用到各种各样的平均数,如平均速度、平均身高、平均产量、平均成绩等。在此,我们对平均数的相关性质做一个简要汇总:
其一,平均数不一定是这一组数据的中间数。
其二,所有数据都要参与平均数的计算,包括0。
其三,平均数易受极端数据影响,特别是极端数据越远离平均数,其对平均数的影响就越大。
其四,所有的数据在平均数上下波动,它们的偏差之和等于0。
其五,平均数反映的是一组数据的特征,而非某个数据的特征。
(2)众数(Mode)
众数是另一个反映集中趋势点的统计指标,主要与各个数据出现的频数密切相关。在统计意义上,众数代表数据的一般水平或大众水平。可以这样说,众数就是一组数据中出现次数最多的那个数值,或者说,众数就是一组数据中占比例最多的那个数。与平均数相比,用众数代表一组数据,可靠性相对较差,但是,作为一个反映集中趋势的基本指标,众数克服了平均数易受极端数值影响的弊端,因此,如果在一组数据中个别数据差异悬殊,那么,选择众数表示这组数据的“集中趋势”就比平均数更为恰当。众数的另一个优点是对非数值性资料特别有用,如在{鸡、鸭、鱼、鱼、鸡、鱼}这样的一组陈述中,人们无法使用平均数或者中位数,但是,可以发现在这组数据中,出现频次最多的是“鱼”,即这组数据的众数,体现了这组数据的一般水平。
一般来说,在一组数据中,出现次数最多的数就叫这组数据的众数。例如:1,2,3,3,4的众数是3。但是,如果有两个或两个以上个数出现次数都是最多的,那么这几个数都是这组数据的众数。例如:1,2,2,3,3,4的众数是2和3。此外,另一种情况是,如果所有数据出现的频次都一样,那么这组数据没有众数。例如:1,2,3,4,5没有众数。
(3)中位数(Median)
尽管平均数是最常用的集中趋势指标,但是,平均数有其弱点,即容易受到极端数值影响。这种影响体现在日常生活中,由于掩盖了很多问题而有时候会显得特别荒谬。如有这样的打油诗:“张村有个张千万,隔壁住着九个穷光蛋,平均起来算一算,人人都是张百万。”
解决平均数不足之处的方法就是计算“中位数”。以一家51人的企业为例,把所有人员年收入从大到小排列,正中间的一位,即第26位的年收入就是这家企业年收入的中位数。打油诗里的“张村”个人财产中位数就是“零”。由于处于一组数据的中间位置,不容易受偏大或偏小等极端数据的影响,中位数在统计学分析中也常常扮演着“分水岭”的角色,人们可以只对事物的大体趋势进行判断和掌控。精确地说,把一组数据按从小到大的数序排列,在中间的一个数字(或两个数字的平均值)叫做这组数据的中位数。中位数将数据分成两部分,一部分大于该数值,一部分小于该数值。
关于中位数的位置:当样本数为奇数时,中位数=第(n+1)/2个数据;当样本数为偶数时,中位数为第n/2个数据与第(1+n)/2个数据的算术平均值。就统计意义而言,中位数可以避免极端数据,代表着数据总体的中等情况。
2.离散趋势分析
集中趋势指标描述的是一组变量值的平均水平或中心位置,要想全面描述资料的数量特征,仅有集中趋势指标是不够的,还要计算离散趋势指标。离散趋势指标指的是社会现象某一数量标识的各项数值距离它的中心值(或代表值)的差异程度,它所体现的是资料内部的变异程度,主要指标包括极差、标准差、异众比率、四分位差、变异系数。离散趋势指标值越大,说明资料内部变异度越大。最常用的指标是标准差。
(1)极差(Range)
极差也称为全距,是一组数据中最大数据与最小数据的差,在统计中常用极差来刻画一组数据的离散程度。极差反映的是变量分布的变异范围和离散幅度,在总体中任何两个单位的标准值之差都不能超过极差。同时,它能体现一组数据波动的范围。其计算方法是:R=max-min。如:
121213141621
这组数的极差就是21-12=9。
极差只指明了测定值的最大离散范围,而未能利用全部测量值的信息,不能细致地反映测量值彼此相符合的程度,极差是总体标准偏差的有偏估计值,当乘以校正系数之后,可以作为总体标准偏差的无偏估计值,它的优点是计算简单,含义直观,运用方便,故在数据统计处理中仍有着相当广泛的应用。但是,它仅仅取决于两个极端值的水平,不能反映其间的变量分布情况,同时易受极端值的影响。
(2)标准差(Standard Deviation)
标准差也称为均方差(Mean Square Error),是运用最为广泛的、最为重要的离散趋势指标。标准差与集中趋势中的平均数是一对对立范畴,从某种意义上可以说,它也是一种平均数。具体而言,标准差指的是:一组数据对其平均数的偏差的平方的算术平均数的平方根。标准差反映了一个数据集的离散程度,可以更好地识别不同组别数据之间的内部差异,如两组数据集平均数相同,但是各个数据集内部的差异可能会非常之大,而用平均数无法体现数据内部的结构差异,只能通过标准差来判断。例如,A、B两组各有六位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差为17.08分,B组的标准差为2.16分,说明A组学生之间的差距要比B组学生之间的差距大得多。
一般来说,用S表示标准差,其计算公式可以表达如下:
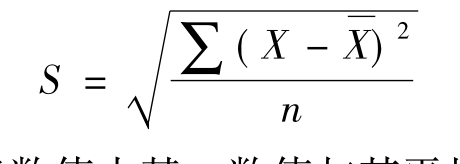
标准差主要是衡量一组数值中某一数值与其平均值差异程度的指标,是一组数值自平均值分散开来的程度的一种测量观念。一个较大的标准差,代表大部分的数值和其平均值之间差异较大;而一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0,5,9,14}和{5,6,8,9}其平均值都是7,但后一个集合具有较小的标准差。
标准差可以作为量度稳定性的指标。例如,用标准差来研究股票价格的稳定性。当标准差数值越大时,其代表的含义就是某支股票远离平均数值,稳定性较差,这意味着该支股票风险与收益都相对较高;反之,当标准差较小时,意味着其稳定性较高,风险较小,但收益同样较小。
(3)异众比率(Variation Ratio)
异众比率是与集中趋势中众数指标相对应的一个离散趋势分析指标,指的是非众数组的频数占总频数的比例。以VR表示异众比率,其计算公式可以表达为:
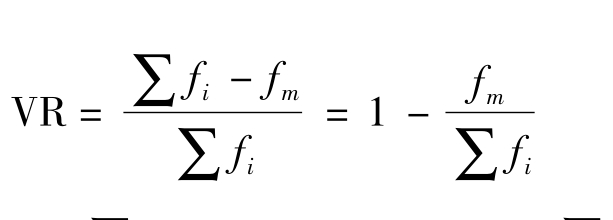
其中,VR表示异众比率,∑fi为变量值的总频数;∑fm为众数组的频数。异众比率主要用于衡量众数对一组数据的代表程度。异众比率越大,说明非众数组的频数占总频数的比重越大,众数的代表性就越差;异众比率越小,说明非众数组的频数占总频数的比重越小,众数的代表性越好。如我们通过计算求出一项50人调查中,购买其他品牌饮料(指除可口可乐之外的品牌)的人数达到70%的异众比率,异众比率比较大,那么,说明用“可口可乐”来代表消费者购买饮料品牌的状况,其代表性比较差,其众数代表性就不是很明显。
在具体的使用中,异众比率主要适用于定类数据的离散程度,当然,可以通过降低使用层级而适用于定序数据或定距数据。
(4)四分位差(Inter-quartile Range)
四分位差是分位差的一种(其他分位差有八分位差、十分位差、十六分位差、三十二分位差以及百分位差等),这是对极差指标的一种改进,主要是从变量数列中剔除了一部分极端值之后重新计算的类似于极差的指标。四分位差是最常用的分位差。就计算程序而言,首先要对数据按照从小到大的顺序排序;其次将其四等分;再次去掉序列中最高的1/4和最低的1/4;最后计算中间的一半数值之间的极差。四分位差常用Q表示,而Q1和Q3则被用来表示第一个四分位点和第三个四分位点对应的数值。
假设有数组:{0,10,20,30,40,50,60,70,80,90,100,110}。
共12个元素,由小到大排列。
则第一个四分位点Q1的值为数组中第三位和第四位的中位数,即:Q1=(20+30)/2=25;同理,第三个四分位点Q3对应的数值为第九位和第十位的中位数,即:Q3=(80+90)/2=85。
四分位差Q=Q3-Q1=85-26=59
如果该数组表示12个学生的成绩,Q表示学生得分的分散情形,那么,Q值越大,则表示学生得分越参差不齐。
(5)离散系数(Coefficient of Variation)
离散系数又称变异系数或“标准差率”,是衡量资料中各观测值变异程度的一个统计量。当进行两个或多个资料离散程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果度量单位和(或)平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。离散系数可以消除度量单位和(或)平均数不同对两个或多个资料变异程度比较的影响。标准离散系数是一组数据的变异指标与其平均指标之比,它是一个相对离散指标。离散系数是标准差与平均数的比值,用百分比表示,记为CV,其计算方法为:
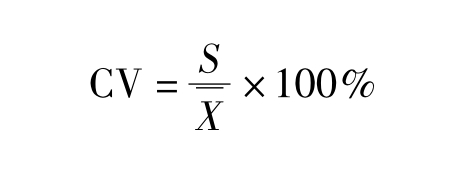
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









