



10.3 数据检测子系统
数据检测子系统负责检测网络上词汇的变化,利用爬虫技术建立资源下载器抓取指定信息源的网络资源,为新词分析和关系分析作准备。在第6章已经分析过了中国期刊网的文献描述页面对于提取新词汇以及新关系是一种极其重要的资源。因此我们的系统主要是要爬取中国期刊网中描述文献的网页。
10.3.1 功能分析
通过分析中国期刊网的网址,我们发现针对不同的期刊以及不同的日期,网址有不同的参数filename以及dbname。如图书馆建设2008年8月第33篇文章,其网址为http://epub.cnki.net/grid2008/ detail.aspx? filename= TSGJ 200808033&dbname= CJFDT2008。因此,我们只需要对特定网页进行抓取即可,而无需通过网页的超级链接再进行深度的爬取。图10-5为爬虫系统的流程图。
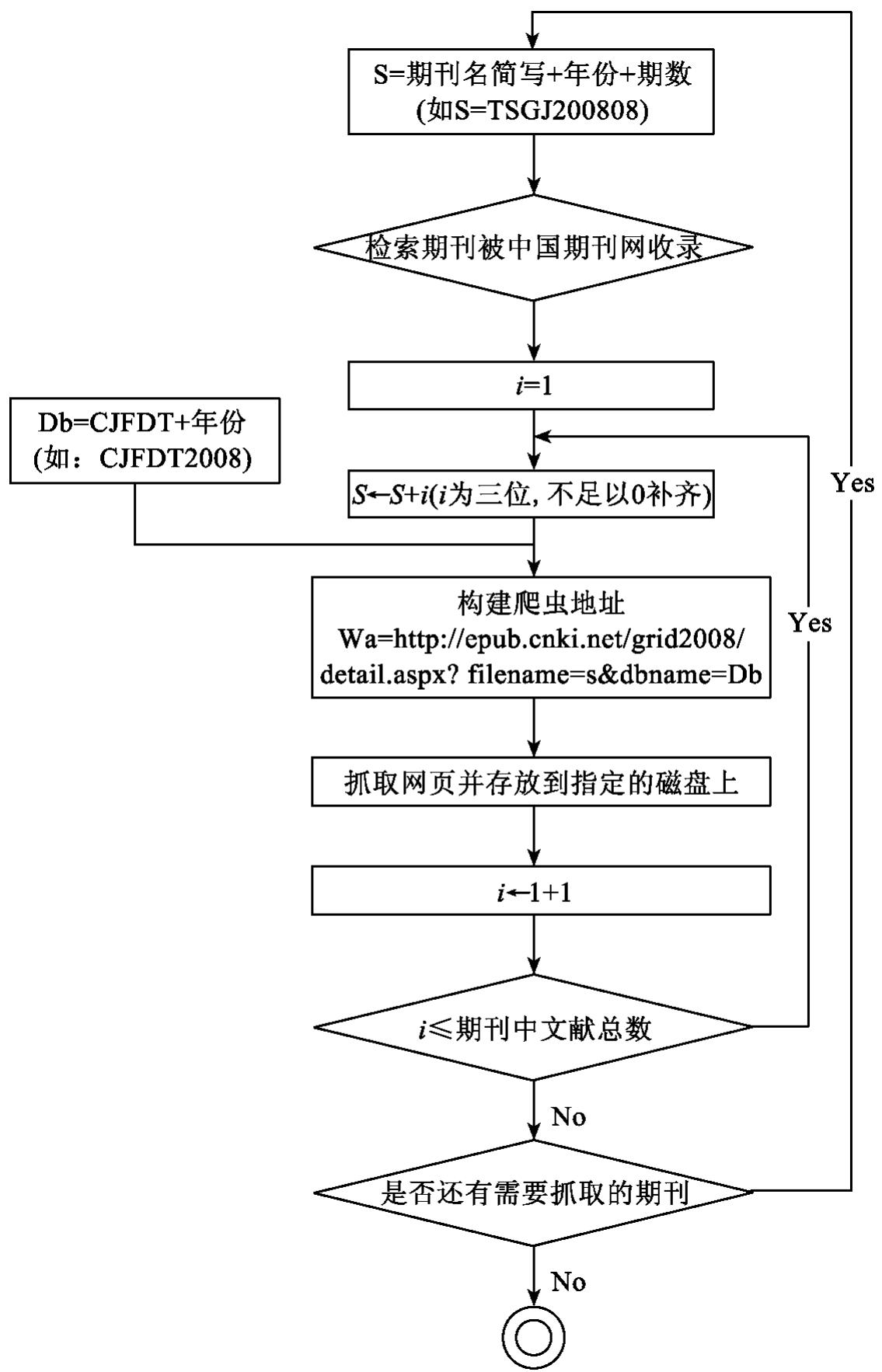
图10-5 爬虫程序的流程图
如流程图所示,爬虫系统中有两次循环,一是对中国期刊网中所有需要爬取的期刊进行循环,另一是每一种期刊还要对每一篇文章进行循环。对于哪些杂志需要抓取,则需要工作人员根据需要更新的领域以及该领域所存在的期刊进行界定,同时也需要对期刊的期数进行界定。如果系统需要每个月对叙词本体更新,那么只需要抓取最近一个月的文献即可,而如果系统是每两个月或者更长时间对叙词本体进行更新,那么则需要对期数也进行一次循环(图中没有画出)。为了减少工作人员的工作的复杂度,我们建议每个月抓取中国期刊网上的文献描述网页。
10.3.2 问题域分析
采用用例驱动的分析方法分析需求的主要任务是识别出系统中的参与者和用例,并建立用例模型。对爬虫系统所具有的功能进行分析,可识别出参与者和用例。
1.识别参与者
爬虫系统的核心部分是抓取网页并存放在指定的磁盘上。这部分是按照固定周期T执行。系统默认是一个月执行一次,抓取中国期刊网上本体所需更新的领域的期刊文献。但工作人员可根据具体需求对周期进行设置,对所需更新的领域和领域所存在的期刊进行界定,同时也需要对期刊的期数进行界定。并且系统存在一个监听器,用来监听时间,当前次爬取后等待的时间到达周期T时,要能使系统自动进行再次爬取。故Staff(工作人员),Listener(监听器)是爬虫系统的参与者。
参与者的描述如下:
(1) Staff
描述: Staff可以设置系统执行的周期,界定所需爬取资源的领域、领域所存在的期刊和期刊的期数。
(2) Listener
描述: Listener可以用来监听时间,当前次爬取后等待的时间到达周期T时,要能使系统自动进行再次爬取。
2.识别用例
通过对需求的分析,可识别出该系统的用例: setParameters(参数设置)和crawl(爬取网页)。
(1) setParameters(参数设置)
设置系统执行的周期,界定所需爬取资源的领域、领域所存在的期刊和期刊的期数。
(2) crawl(爬取网页)
按照设置的周期执行。在中国期刊网上所界定的领域、领域所存在的期刊和期刊的期数内抓取网页文献资源,并存至指定的磁盘。
爬虫系统的用例图如图10-6所示,参与者“Staff”与用例“setParameters”交互。参与者“Listener”与用例“crawl”交互。
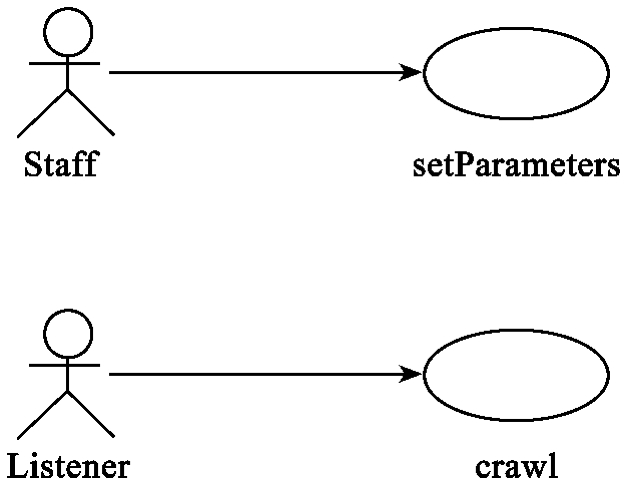
图10-6 爬虫系统用例图
3.用例的事件流描述
对用例的事件流的描述如下。


该用例可以用如图10-7所示的活动图描述,首先系统提示用户输入相关的运行参数,然后Staff输入上述信息后提交,系统验证各参数的合法性和有效性。如果正确,则将相关参数保存并覆盖原有参数;否则,显示错误提示信息,并提示用户重新输入各参数。

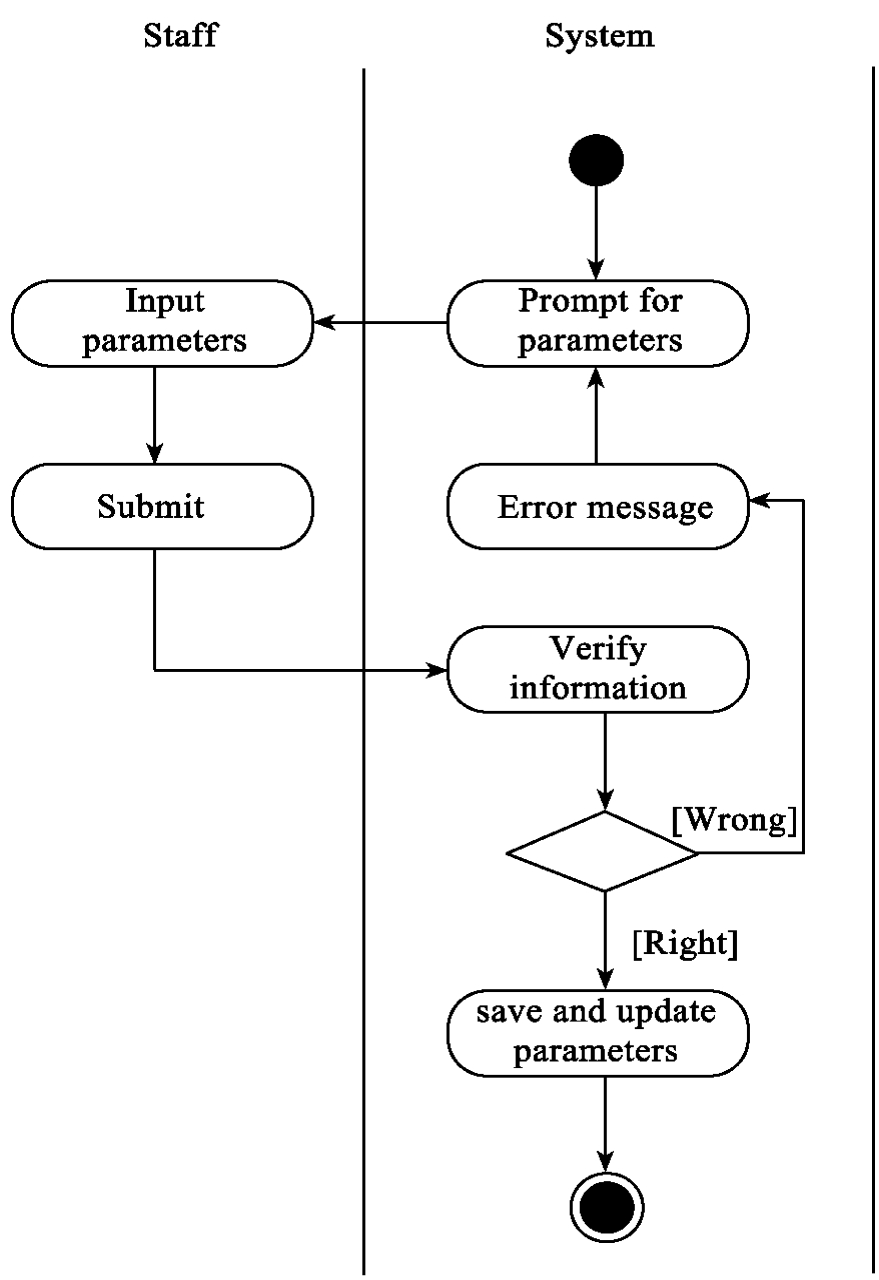
图10-7 “setParameters”(设置参数)的活动图
该用例可以用如图10-8的活动图描述。首先获取工作人员设置的数据源参数,然后验证该指定的数据源是否存在。如果存在,则使用网页爬取算法抓取指定的信息资源,然后将其以HTML的形式保存至指定文件夹。如果不存在,则结束用例。
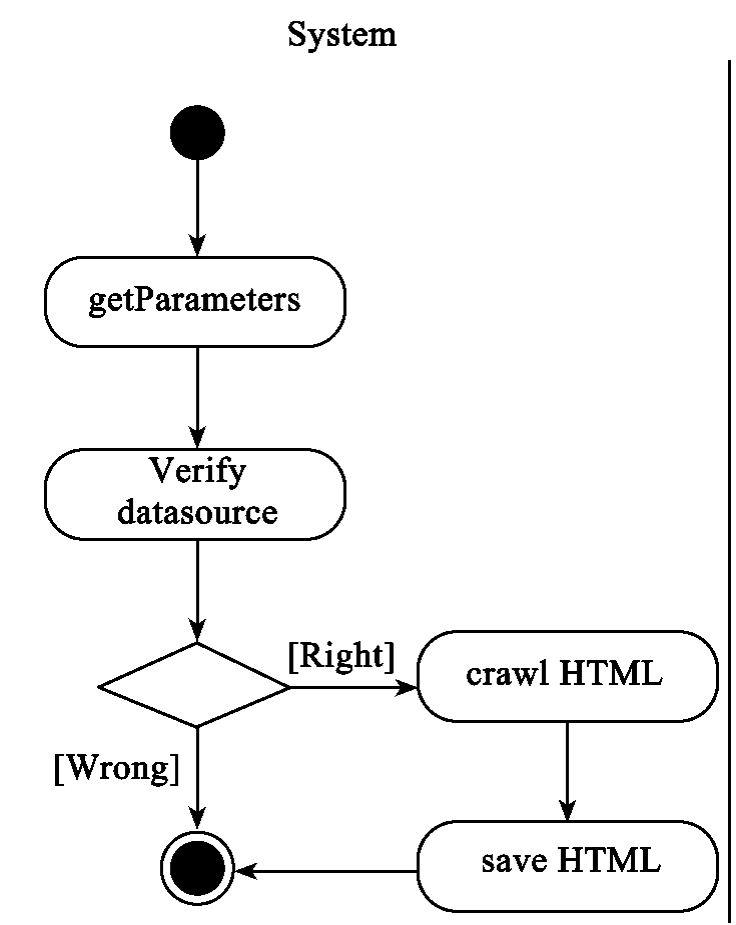
10-8 “crawl”(抓取信息资源)的活动图
10.3.3 静态结构模型
进一步分析系统需求,识别出类以及类之间的关系,确定它们的静态结构和动态行为。系统的静态结构模型主要用类图或对象图描述。
1.定义系统对象类
爬虫系统主要参与者有Staff(工作人员)和Listener(监听器),主要的用例有setParameters(设置参数)和crawl(爬取网页信息资源)。Staff在系统中不具有行为,但具有身份,故可以将其看成为类,具有一定的属性。Listener用来监听时间,以保证系统按一定周期自动抓取信息资源。故Listener应具有listen(监听),runCrawl(执行爬取)的行为,并需有cycleTime(运行周期)的属性。setParameters用来实现参数的设置,封装了各参数作为属性,并应包含updateParameters(更新参数)的行为,故可从中识别出对象类Parameters。Crawl是描述抓取网页资源的用例。它涉及资源相关参数的获取、网络资源抓取和网络资源保存。可从中识别出类Crawl,包括getParameters(),WebPageDownload()和save-Html()三个行为,资源相关参数等属性。
(1)类StaffClass
类StaffClass代表工作人员。类Staff应该具有下列私有属性:
staffCode: String
name: String
role: String
(2)类ListenerClass
类Listener代表监听器。类Listener应该具有下列私有属性:
cycleTime: Number
类Listener应该具有下述方法:
listen()
runCrawl()
(3)类Parameters
类Parameters代表相关参数。相关参数包括runCircle(运行周期),area(信息源的所属领域)、databaseName(信息源的数据库名)。故类Parameters应该具有下列私有属性:
runCircle: Number
area: String
databaseName: String
类Parameters应该具有的方法有:
updateParameters()
(4)类Crawl
类Crawl代表对特定信息资源的抓取。包括getParameters,WebPageDownload和saveHtml三个过程和area(信息源的所属领域)、databaseName(信息源的数据库名)两参数。故类Crawl的属性和方法如下:
area: String
databaseName: String
getParameters()
WebPageDownload()
saveHtm l()
上述各类为了设置和访问对象的私有属性值,类应具有相应的setXX()方法用来设置私有属性值,相应的getXX()方法用来访问私有属性值。
2.定义用户界面类
用例setParameters的实现需有相应的界面提示用户输入需要设置的各参数,并需要相关的ParametersServlet类获取界面上输入的参数,实例化Parameters对象,实现参数设置的过程。而用例crawl是在后台自动运行,不需要相关的界面类。故用户界面类有:
(1)类ParametersGUI
界面类ParametersGUI是用来设置参数所需的对话框,其界面如图10-9所示。当按下确定按钮,则对输入的各参数的格式进行验证,验证成功则提交到ParametersServlet类,由该类获取参数,执行设置参数的操作。
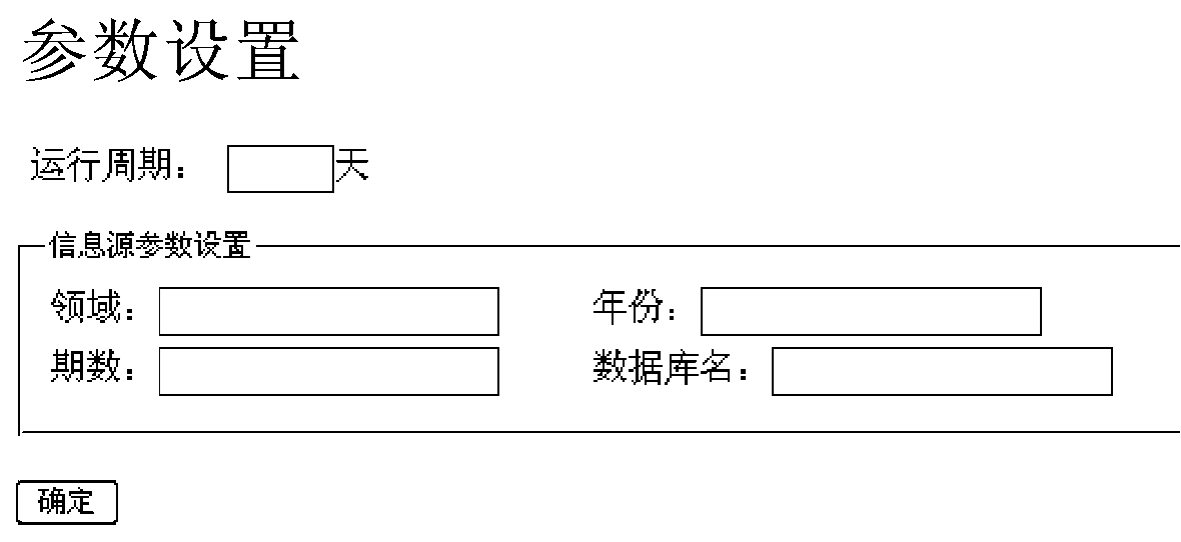
图10-9 “setParameters”(设置参数)的界面图
1)私有属性。
待定。
2)公共方法。
newParametersGUI(): void
创建参数设置界面。
submitParameters(): void
提交参数。
(2)类ParametersServlet
1)私有属性。
待定。
2)公共方法。
newParametersServlet: void
创建newParametersServlet对象。
doGet( request: HttpServletRequest,response: HttpServletResponse): void
由servlet引擎调用处理一个HTTP GET请求
doPost( request: HttpServletRequest,response: HttpServletResponse): void
由servlet引擎调用处理一个HTTP POST请求
3.建立类图
识别出系统的类后,进一步识别出类的关系,建立类图如图10-10所示。类ParametersServlet、类ParametersGUI、类Listener-Class、类Crawl与类Parameters之间是依赖关系。
10.3.4 动态行为模型
系统的动态行为模型可以用交互作用图、状态图和活动图来描述。在前面的小节中已使用活动图描述了用例的场景。活动图强调了从活动到活动的控制流,而交互作用图则强调从对象到对象的控制流,本节采用时序图来描述为完成某个特定功能发生在系统对象之间的信息交换。
描述用例场景的时序图如下:
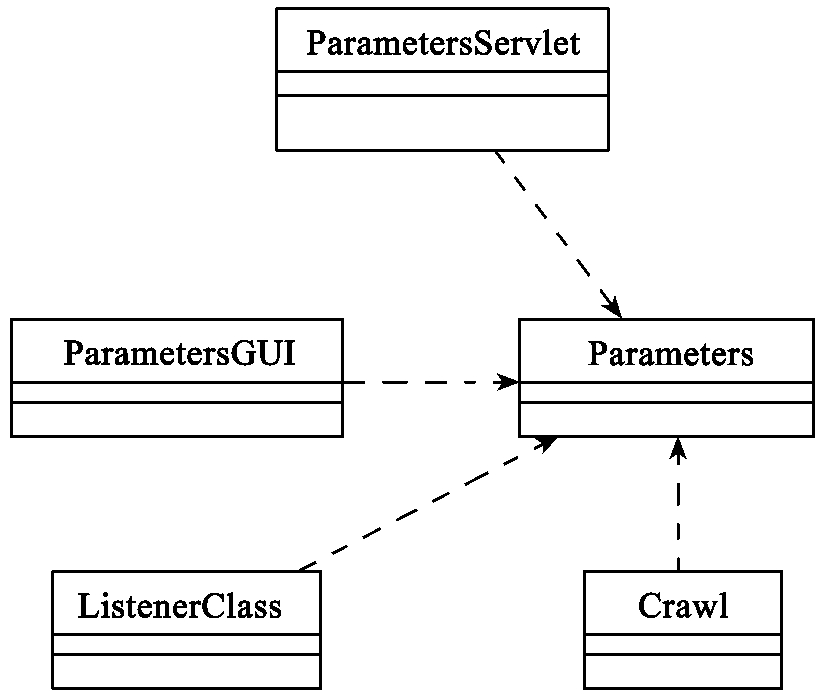
图10-10 爬虫系统的类图
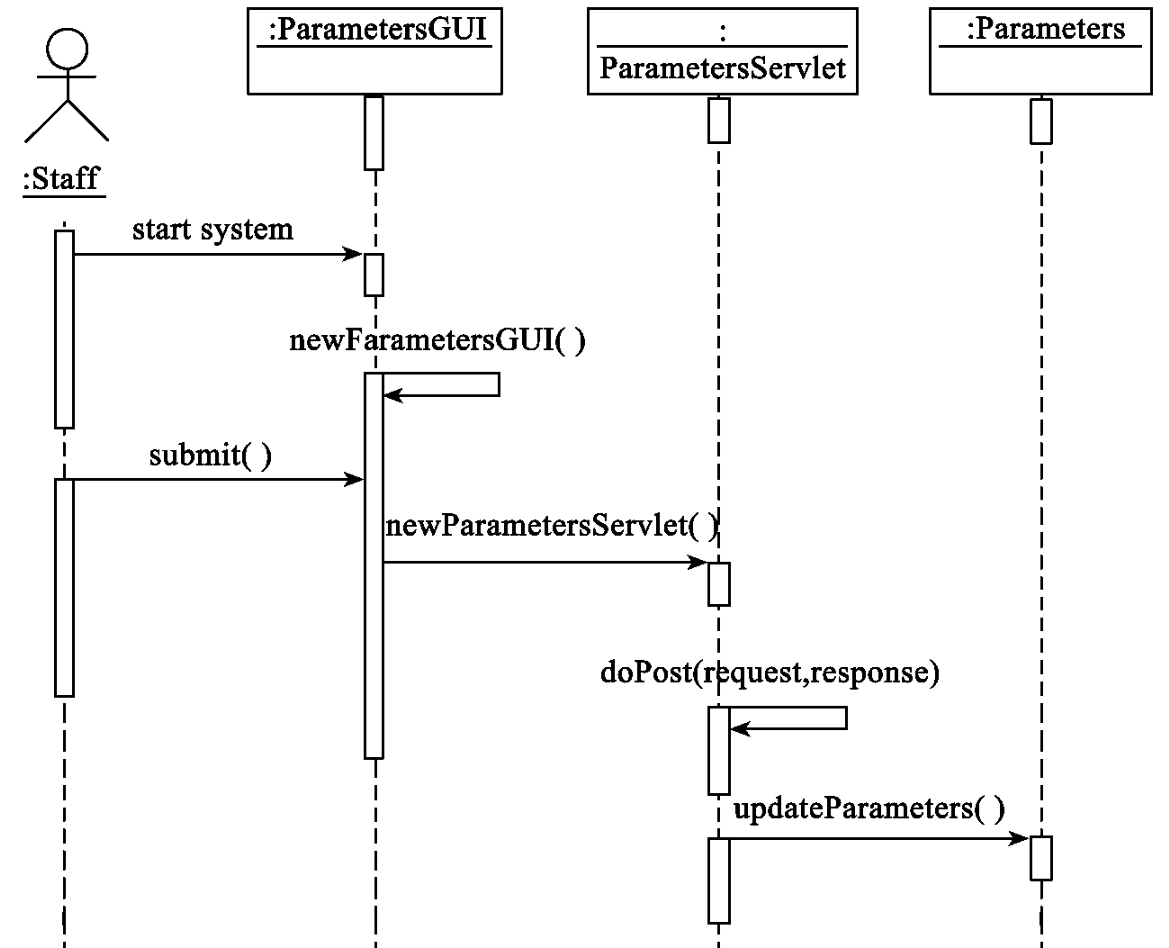
图10-11 “setParameters”(设置参数)的时序图
“setParameters”(设置参数)的顺序图如图10-11所示,Staff启动系统,类ParametersGUI的方法newParametersGUI()被调用,创建用来填写参数的对话框。Staff填写参数后,调用submit(),将参数提交。由servlet引擎调用处理该HTTP POST请求,调用类ParametersServlet的方法newParametersServlet(),创建对象,并将参数提交给创建的对象来处理。该对象调用doPost(request,response)的方法,实现获取界面对象提交的参数信息,创建Parameters对象,并由Parameters对象调用Parameters的updateParameters()方法实现参数的设置。
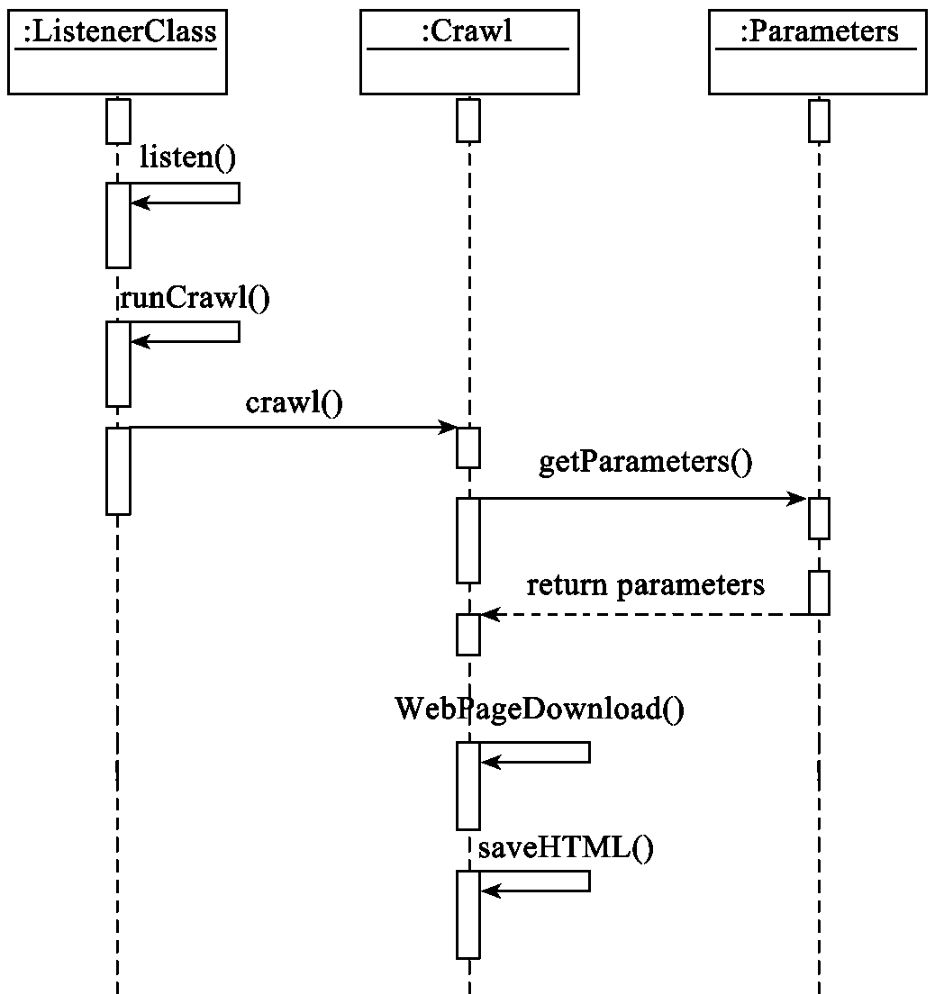
图10-12 “Crawl”(抓取信息资源)的时序图
“Crawl”(抓取信息资源)的时序图如图10-12所示,类ListenerClass调用listen()的方法实时监听时间的变化,判断是否开始运行信息资源抓取。如果当前的时间与前次开始执行时间的间隔达到了系统设置的运行参数的值,则开始执行信息资源抓取的运行。这时,runCrawl()将被调用,同时类Crawl的crawl()将被调用。在crawl()中,调用类Parameters中的getParameters()的方法获取信息源的相关参数信息,这样就为所需抓取的信息源指定了相关的参数信息。然后再调用WebPageDownload()将指定信息源的网页资源信息下载,调用saveHtml()将资源以HTML的形式保存至磁盘。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










