



一、单变量描述统计
单变量描述统计(univariate descriptive statistics)描述某个变量属性值的集中趋势、离散趋势及其分布。
(一)集中趋势分析
描述统计中常用某个指标来描述一组数据的集中趋势。常用的这类指标有三种:众数(mode)、中位数(median)和平均数(mean),它们分别适用于不同的场合。
1.众数
众数是观测数据中出现频率最高的属性值。如观测51位博士研究生的年龄,得出如表5-1所示的数据。面对这组数据,如何用一个简单指标来描述整个样本组的年龄状况,是大还是小,或其多数人的年龄是多少。用众数来表征的话便是27岁,因为出现次数最多,有12人。这种情况下,年龄是变量,25~31岁为属性取值范围。众数不用计算,它可从一组数据中判断出来。众数这个指标有缺陷,一组数据中可能有两个甚至更多的众数,此时便不够简明。如果随机抽取同样大小的样本,两组样本的众数不相同,便在形式上表现出两组样本存在实际上可能并不存在的差异,这就限制众数的应用价值。不过在定类尺度的情况下,众数是唯一适用的指标,如甲A足球联赛球队水平如何,只有选用积分最多的冠军队来代表。
表5-1 集中趋势分析数据
2.中位数
中位数是将观测数据按大小顺序一分为二的变量属性值。只须把观测数据按高低顺序排列,若样本总数是奇数,中间的那个便是中位值,如表5-1,按样本总数和累计人数便可判断出第26号样本居中,中位值即28岁。用算式表示的话,把样本总数N加1后除以2,得出的便是中位值的位置。若为偶数,便算出中间值(N+1)/2,相应的上下属性平均值便是中位值。如表5-1所列数据,假设31岁的人数少一个,成为(4),样本总数随之减到50,中间值(50+1)/2=25.5,上下两数为25,26,则中位值相应为(27+28)/2=27.5(岁)。
管理研究常把变量属性集结成组,如年龄变量按5岁为一组。求中位数时,按5岁的跨距计值未免过于粗糙,可按下式计算。
![]()
式中,Md——中位数;
L——中位数所在属性组的下限;
N——样本总数;
cf——中位数所在组以下的累计数;
f——中位数所在组的样本数;
w——中位数所在组的属性间距。
表5-2表示某企业职工年龄组分布。现以此来说明中位数的计算。
首先找出中位数所在的属性组。由于(1150+1)/2=575.5,中间值位置在575和576之间,年龄变量的中位数便落在30~34年龄组内。然后,根据算式,此中位数为:
30+[(1150/2-350)/270]×4=30+(0.82×4)=33.3(岁)
表5-2 中位数分析数据
中位数最适合于描述定序尺度的数据聚中趋势(central tendency)。对于定比和定距尺度变量,中位数有时也能适当地反映其聚中特征,例如收入的中位数或房价的中位数。Fortune(财富)500家企业的评估中,中位数就是个重要指标,1989年Fortune 500的销售额中位数为1.6172亿美元。第250位和251位的销售额分别为1.618和1.6165亿美元。
3.平均数
定比和定距尺度下,平均数是应用最多的反映聚中趋势的指标。观测值的总和除以观测次数即得出平均数,一般用下式表示:
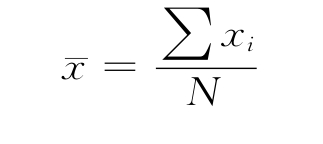
式中,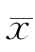 ——平均数;
——平均数;
xi——观测值;
N——观测次数。
平均数是根据数组内的所有数据计算出来的,不像中位数那样具体明确,并且平均数受极端数据影响。譬如,群体中有某个人收入特别高,整个群体收入的平均值就骤然提高,这时倒不如中位数那样能反映聚中的实际情况。然而,人们在定序和定距尺度情况下仍然偏好平均数指标,因为它比众数和中位数更精确和稳定。从同一总体中多次随机抽取同样规模的样本,这些样本的平均数会比较接近,而各样本组的众数和中位数相互之间可能有较大差异。众数一般不适宜用于定距定比尺度下的数据分析,中位数不能“确切”地代表总体,只是总体中的典型。例如一组反映9位工人上周产出的数量为96,96,97,99,100,101,102,104,155,则三种反映聚中趋势的指标分别为:众数=96,中位数=100,平均数=105.6。如果依据这些指标描述总体产出状况,众数显然偏低,而平均值高于除155外的所有产出数,数字显然偏高,中位数较好地反映典型的产出状况。如这些数字用来确定下周生产目标,中位数较适合。企业收入分配中常碰到职工收入总体状况指标的选择问题,如某部门职工收入为:22000,23000,23000,25000,26000,28000,55000,则有众数=23000,中位数=25000,平均数=28857。职工一方往往偏好众数,而管理层则偏好平均数,因为与平均数相比收入较高的管理者超出一般职工收入的额度显得小些。
(二)离散趋势分析
统计中反映聚中趋势的指标固然非常有用,但不够充分,例如以下两组数据:
A:79 79 79 80 81 81 81
B:50 60 70 80 90 100 110
两组数据的中位数和平均数都相同,然而数据差别甚大,数组A较聚中,而数组B较分散,各数据间距大,因此,须选用一个指标来衡量数据的离散趋势(dispersion tendency)。有如下几种可供选择。
1.极差
极差(range)指数组中最高值和最低值的差距。它只适用于定比和定距数据。如数组A的极差为2(即81-79=2),而数据B的极差为60。这种度量方法简便直观,但它由两极端偏异值决定,并不能充分地反映数据的分散程度。
2.四分互差
四分互差(quartile deviation)用于度量定序数据变异的指标。把一组数列等分为四段,各段分界点上的数称为四分位数。具体来说第一个四分位数q1以下包括25%的数据,q2是中位数,q3则包括75%的数据。四分互差即指第三个和第一个四分位数差距之半,即q=(q3-q1)/2。如用来分析Fortune 500家企业的数据,第三个四分位数代表销售额第125名的企业,第一个四分位数代表第376名企业,则四分互差为第125家和第376家企业销售额差距之半。如四分互差较小,说明数据较聚中,同时也说明中位数越有代表性。中位数指标适用的场合,四分互差指标也适用,四分互差计算时涉及的问题与中位数的计算很类似。
3.标准差
标准差(standard deviation)适用于度量定比和定距数据变异的指标,也是统计中最常用的指标。分析离散趋势的标准差和分析聚中趋势的平均数的重要性相当,综合反映了所有数据的影响。将各个数据和平均值的差距平方后相加,除以样本总数后取其平方根,便得出标准差
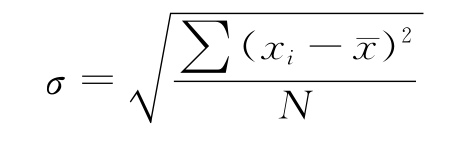
式中,σ——标准差;
xi——样本值;
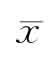 ——平均数;
——平均数;
N——样本总数。
平均数和标准差是统计描述各种数据分布的配套指标,对于一组单独的数据分布来说,标准差的作用还不明显,它主要用来比较各组数据离中的总体状况。
(三)频数和频率分布
面临一组变量的观测数据,研究者往往需要直观地感受它的分布状况,为此,通常采用频数分布和频率分布(frequency distribution)。频数分布描述变量观测值中各属性值出现的次数。一个班级男生50人,女生25人,如以性别作为变量,这就是最简单的频数分布。频率分布则是用比率的形式表示,属性值出现的频数除以个案总数(在上例中男生为67%,女生为33%),这便是频率分布。
变量的频率分布可以分成对称分布和不对称分布两类。正态分布(normal distribution)是应用最广泛的一种对称分布,适用于描述管理研究中许多变量的属性分布,如销售量、生产周期和工时等。正态分布的众数、中位数和平均数三者相同。对称分布的极端数据在高低两端出现的频率都是相同的,而不对称分布通常总有一端的极端数据比另一端要多。如果极端数据出现在高端,则称为正偏态分布;如出现在低端,则称为负偏态分布(图5-1)。
在不对称分布中,由于极端数据的“拉动”,平均值总向极端值的某一方偏移,负偏态分布的平均数往低偏移,小于中位数,而正偏态分布的平均数则往高偏移,大于中位数。当观测数据或样本值无重复值时,中位数则总是将频率分布分为两半,平均数、中位数、众数三者之间的关系可概括为:
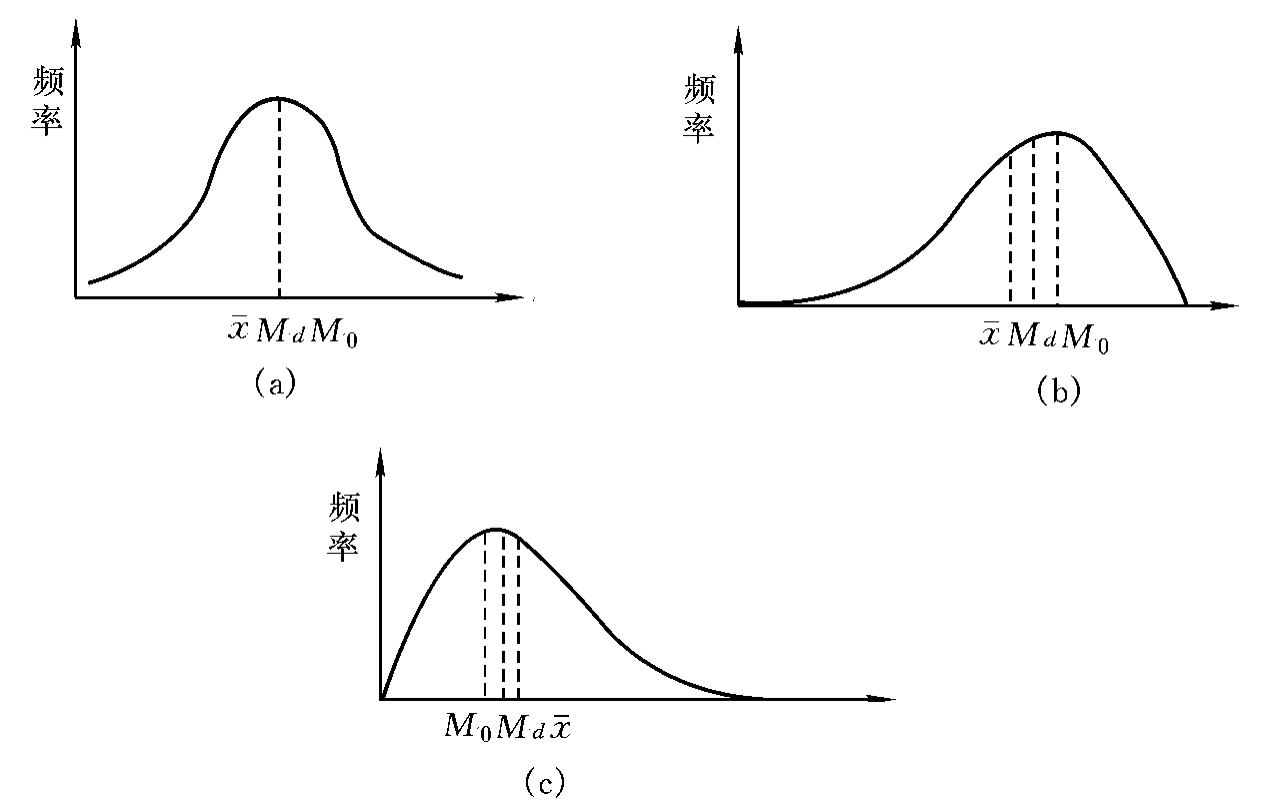
图5-1 频率分布
(a)正态分布;(b)负偏态分布; (c)正偏态分布
正态分布 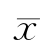 =Md=M0;
=Md=M0;
负偏态分布 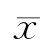 <Md<M0;
<Md<M0;
正偏态分布 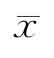 >Md>M0。
>Md>M0。
一旦知道某组数据三种指标相等或接近的话,则往往可以推测该组数据属于或接近正态分布。如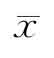 大于或小于Md则为正偏态或负偏态,这时,正态分布的一些假设就不适用于这组数据。
大于或小于Md则为正偏态或负偏态,这时,正态分布的一些假设就不适用于这组数据。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









