



一、研究数据的收集对象和收集过程
(一)样本的确定
研究对象,必须是微博客的长期(至少6个月)使用者。为了满足这一要求,本研究采用非概率抽样中的滚雪球抽样方法[1],抽样者为在校就读学生(大学一年级到博士三年级),共得到样本560位[2],其基本人口特征如图3-2所示,并由此得到了符合本研究目标研究对象的样本(即使用微博客6个月以上的个人)为560位。
样本性别结构:
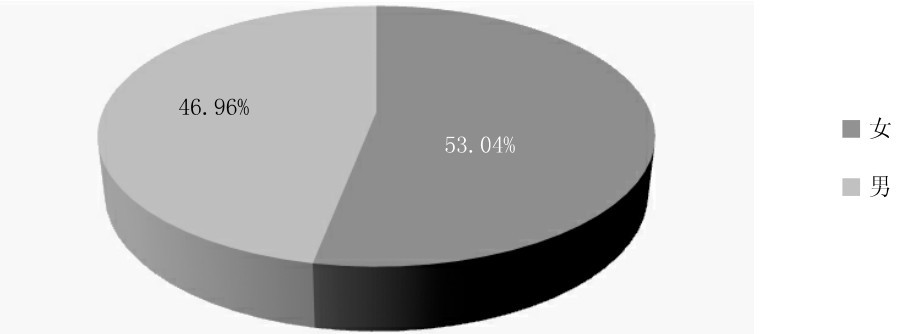
图3-2 研究样本性别结构
样本教育程度结构如下:

图3-3 研究样本教育程度结构
样本职业结构如下:
图3-4 研究样本职业程度结构
(二)样本的使用
本书对以上样本发放了问卷560份,共回收560份,其中543份有效,收集了样本在涵化作用效果方面的认知心理数据。对于有效样本,以15人为培训单位分别进行编码培训[3],并针对每一位样本发放了编码表和需要编码的微博客信息文本资料[4],20日后回收编码数据得到了该样本接收到的微博客公益行为相关信息涵化影响因素的数据。
对于以上两种方式收集到的数据按照其所对应的变量测量指标进行整理,统计预处理,删除缺失值样本和异常值样本,最终得到可以用于进一步数据分析的指标数据。最终进入微博客涵化作用结构方程分析的有效样本543人,有效回收率为96.9%。
二、研究数据的分析方法和过程
(一)结构方程模型
结构方程模型(structural equation modeling,SEM)。“是一种建立、估计和检验变量关系模型的方法。模型中既包含有可直接观测的显在变量,也可能包含无法直接观测的潜在变量。”“属于高级统计学范畴,属于多变量统计(multivariate statistic),它整合了因子分析(factor analysis)与路径分析(path analysis)两种统计方法,同时检验模型中包含的显性变量、潜在变量、干扰变量(disturbance variables)、误差变量(error varia-ble)间的关系,进而获得自变量对因变量影响的直接效果(direct effects)、间接效果(indirect effects)或总效果(total effects)。SEM模型分析的基本假定与多变量总体统计法相同;样本数据要符合多变量正态性(multivariate normality)假定,测量指标变量呈现线性关系。”(吴明隆2009)
结构方程的优点主要体现在“能够处理多个原因与多个结果之间复杂的变量关系,尤其是能够有效地估计包含有不能直接观测到的潜变量的变量结构中,变量之间各种直接和间接的因果关系的具体水平”(荣泰生,2009)
具体优点:第一,同时处理多个因变量;第二,容许自变量和因变量含有测量误差;第三,同时估计因子结构和因子关系;第四,容许更大的弹性测量模型;第五,估计整个模型的拟合度。
总之,结构方程模型分析方法结合传统的一般线性模型与共同因素分析的技术,已经被广泛应用于经济、社会问题的相关研究之中,用于量化验证、描述多个变量之间的复杂结构关系。Amos(Analysis of Moment Structures)矩阵结构分析和LISREL(linear structural relationships)线性结构关系是两种最为常用的实务应用处理结构方程模型的分析软件。
鉴于本书所关注的微博客公益行为相关信息涵化作用复杂的影响关系,本书通过结构方程模型分析方法,将如上收集到的相关指标数据代入到构建好的微博客公益行为相关信息涵化作用结构方程模型之中,实现了对于微博客公益行为相关信息涵化作用影响关系概念模型的量化拟合,并通过对于结构方程模型中各个变量间关系路径显著性验证变量间关系水平的估计,实现了对于该理论模型所表示的微博客公益行为相关信息涵化影响因素和效果内容之间复杂关系的实际验证和量化描述,进而直观而全面地展示微博客涵化作用影响关系和过程机制。
当然,为深入说明其他与微博客涵化作用效果相关的理论内容,本书还采取其他的数据分析方法:如基本的数据统计描述等等,在此不做特别介绍。
(二)数据分析使用工具
结构方程数据分析工具:AMOS18.0用于结构方程模型拟合和路径系数估计,SPSS18.0,EXCEL2003用以指标数据预处理,协方差矩阵计算,剔除控制变量影响的偏相关协方差矩阵计算。
问卷效度、信度、编码表信度分析使用工具:SPSS18.0。
其他数据分析方法使用工具:SPSS18.0、EXCEL 2003。
[1] 本研究所采用的滚雪球抽样,实际上是立足于样本的社会交际网络而进行的滚雪球方式抽样,即随机选择20个起始发放者,由他们向自己的社会交际网络中的全部成员发放问卷,之后由被发放者自行填答,在被试填答后再将问卷发放给自己社会交际网络中的全部成员,这样,沿着被试的社交网络进行问卷的传递、样本的获取和数据的回收。所以该抽样方式也是结合滚雪球抽样和方便抽样于一体的,且基于全新的社交网络媒介的全新抽样方式。可以快速、有效地收集具有特殊属性的样本信息,虽然由于非概率特征不能代表样本总体,但是通过对于问卷发放起始点的随机选择,也可以在一定程度上增加抽取样本的代表性。关于该抽样方式,笔者的另一篇文章《样本网络对社交网络的拟合——基于SNS媒介的滚雪球式方便抽样调查填答率的提升方法》中有更加详细的介绍,在此不作展开。
[2] 实际获得被试量(以回收的问卷数量为准)为657份,但是由于其中有97个被试不属于本研究的对象即在校大学生、研究生,因此被剔除。
[3] 培训时,为使用即时通讯软件qq和skype,建立了专属的讨论小组,定时进行集体交流。
[4] 该微博客信息文本资料的来源如前所述,就是该研究者在微博客上可能接收到的所有与公益行为相关的微博客信息,包括微博客信息内容以及发布者,依次的转发内容以及转发者,评论数量、评论内容以及评论者,这些信息以原微博客信息链接的形式,一起呈递给研究者,由其按照链接地址点击进入该微博客信息页面,获得该微博客信息,以其作为编码文本对象,按照各个编码表进行编码,进而给出相关信息属性指标的数据。这些微博客公益信息是由笔者领导的信息筛选小组人员筛选该研究样本在微博客上所关注的人所发布的公益行为相关的微博客信息所得到,筛选小组成员将这些微博客的链接地址整理到以该研究样本名称为标题的word文档中,作为编码分析文本材料,在对研究样本编码培训完后分别呈交给研究样本(实际编码者),之后由研究样本也就是实际编码者自己根据链接地址点击浏览这些微博客公益行为相关信息,按照编码标准进行编码。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










