



四、描述性统计
数据分析中有单变量分析、双变量分析和多变量分析的区分,这种分析方法的分类标准主要就是需要分析的数据中包含的变量的个数。一般来说,单变量分析是所有的数据分析中最基本也是最简单的分析,由于这种数据分析的特点就是描述一个变量的分布情况,所以也叫作描述性统计分析。而双变量分析和多变量分析,更多的是要研究变量与变量之间的关系,这两种分析方法也可以统称解释性统计分析。
这里就从最基本的分析单变量的逻辑和格式入手,简单介绍一些描述性统计中的单变量分布、集中趋势、离散趋势。
1.分布
分布是表示单变量最基本的形式,主要的方法就是将所有的单个样本全部都列出来,也就是根据问题中的变量,列出每一个样本的属性。这里说的分布是指频次的分布。
表3.3是一次关于某个街区居民的媒体接触情况调查中,关于每天读报的时间的统计表。
表3.3 每天读报时间分类统计
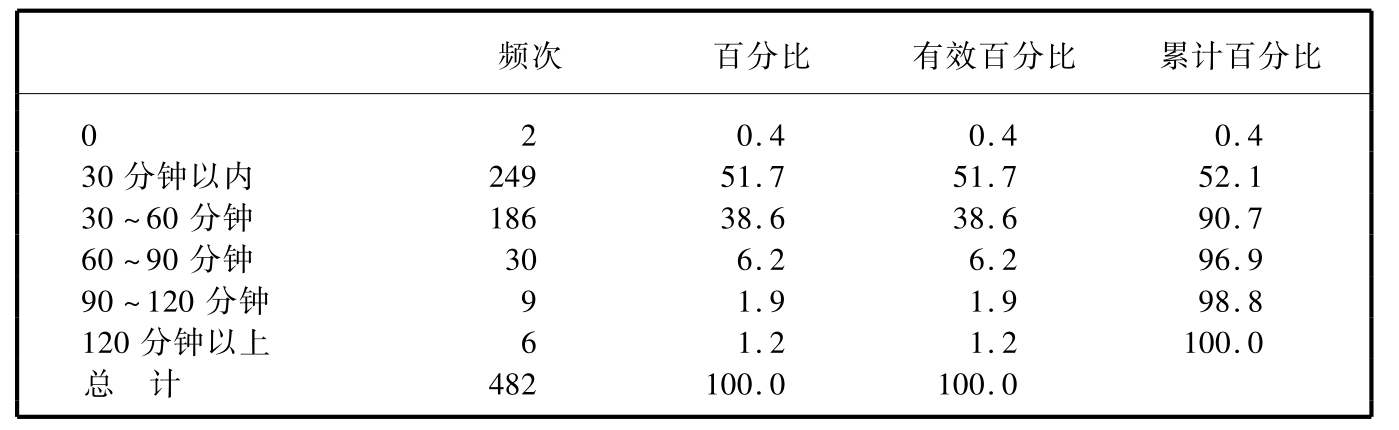
在这个表格中,就可以看到调查者一共分析了482个样本,所有的受访者都给出了相应的答案,其中有249人回答他们每天看报纸的时间在30分钟以内,而且可以通过表中的统计看出这些人占全部受访者的比例为51.7%,也就是说有超过半数的人每天看报纸的时间在30分钟以内。
2.集中趋势
描述集中趋势有三种计量刻度:算术平均值、中位数和众数;其中,以算术平均值来描述数据的平均水平最为直观、明了,也容易被理解,但它容易受调查数据中异常值的影响,例如一个明显偏大的观测值会使整批数据的算术平均值倾向于偏大,而中位数与众数对异常值不敏感,但描述数据整体水平时不如算术平均值精确。
算术平均值是对问卷中的等比或等距量表类问题的数据进行计算得出的,就是将某一个变量的所有观察值加起来,再除以观察的次数,最后得出的数值就是这个变量的算术平均值。算术平均值的大小与该变量的每个观察数据均有关系,其中任何数据的变动都会相应引起算术平均值的变动。计算算术平均值的公式如下:
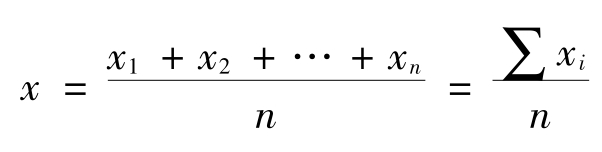
式中:x为多次测定值的算术平均值;
xi为各次测定值,i=1,2,…,n;
n为测定次数。
中位数是一组按大小顺序排列的观察值中位次居中的数值,用M表示。它常用于描述偏态分布资料的集中趋势。中位数不受个别特小或特大观察值的影响,特别是某些变量分布末端无确定数据不能求算术平均数,但可求中位数。中位数则仅与数据的排列位置有关,即应当将一组数据按从小到大的顺序排列后,最中间的数据即为中位数,因此某些数据的变动对它的中位数没有影响。当一组数据中的个别数据变动较大时,可用它来描述其集中趋势。
在一组数据中,出现次数最多的数据叫做这组数据的众数。众数可以运用各种类型的数据进行计算。需要注意的是,同一个变量可能不只有一个众数。众数着眼于对各数据出现的频数的考察,其大小只与这组数据中的部分数据有关。当一组数据中有不少数据多次重复出现时,其众数往往是我们关心的一种统计量。
3.离散趋势
对于两个集中趋势相同的变量,他们的数据的分布并不一定完全相同,所以仅仅用集中趋势来描述一个变量是不完整的,甚至有时会发生错误。对于变量的描述性统计,除集中趋势以外,离散趋势也是一个主要的统计方法。集中趋势的计量指明了一个变量的典型的值,而离散趋势则指出了数据的离散程度。经常用来计算变量的离散趋势的计量方法有:全距、标准差和方差。
全距是变量值中最大值和最小值的差数。确定全距,主要是确定变量值的变动范围和变动幅度[11]。
标准差是最重要、最常用的差异量指标,主要用来考察全组数据与平均数的平均离散水平。标准差的计算公式为:
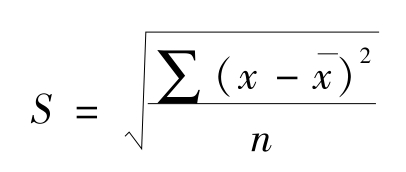
式中:S为样本标准差;
x为某一个观察值;
x为算术平均值;
n为样本容量。
标准差的用途有:
①定量描述数据的离散程度。
②平均数的代表性依赖于标准差,标准差大,平均数代表性就小;标准差小,平均数的代表性就大。
方差从数值上来讲,就是标准差的平方。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












