



【摘要】:对于社会调查中最为常见的两个定类变量之间关系,交叉分析是一种重要的方法。从表中可知:性别与血型的相依系数为0.193,二者属于低相关。其他复选框社会调查中不常用,略去不讲。对话框中的“显著性检验”框,是用于变量间相关的显著性检验。从表中可以看出,身高与体重的相关系数是0.773,而且具有统计学意义。
相关分析_现代社会调查方法
一、相关分析
探索变量之间的相互关系,是社会学研究的一个重要方面。根据变量的不同层次,统计学中有各种不同的相关系数来描述这种相关关系。对于社会调查中最为常见的两个定类变量(或者一个定类、一个定序变量)之间关系,交叉分析是一种重要的方法。在SPSS中,这种交叉分析可以按下列步骤进行。
进入数据视图后,在菜单栏中选择:

![]()
![]()
打开后得到如图11-11所示的对话框。我们以student.sav数据中的性别(sex)和血型(blood_t)变量为例来演示。
在对话框左边的变量栏中选择sex和blood_d两个变量,把变量sex放入中间标有“行(s)”的方框中,而把blood_d变量放在上面标有“列()”的方框中。然后单击该对话框右边的“统计量)”钮,得到如图11-12所示的对话框。由于性别和血型都是定类变量,所以我们选择对话框中“名义”复选框组的“相依系数”。单击“继续”钮,返回图11-11,单击“确定”钮即可(见表11-3和表11-4)。从表中可知:性别与血型的相依系数为0.193,二者属于低相关。
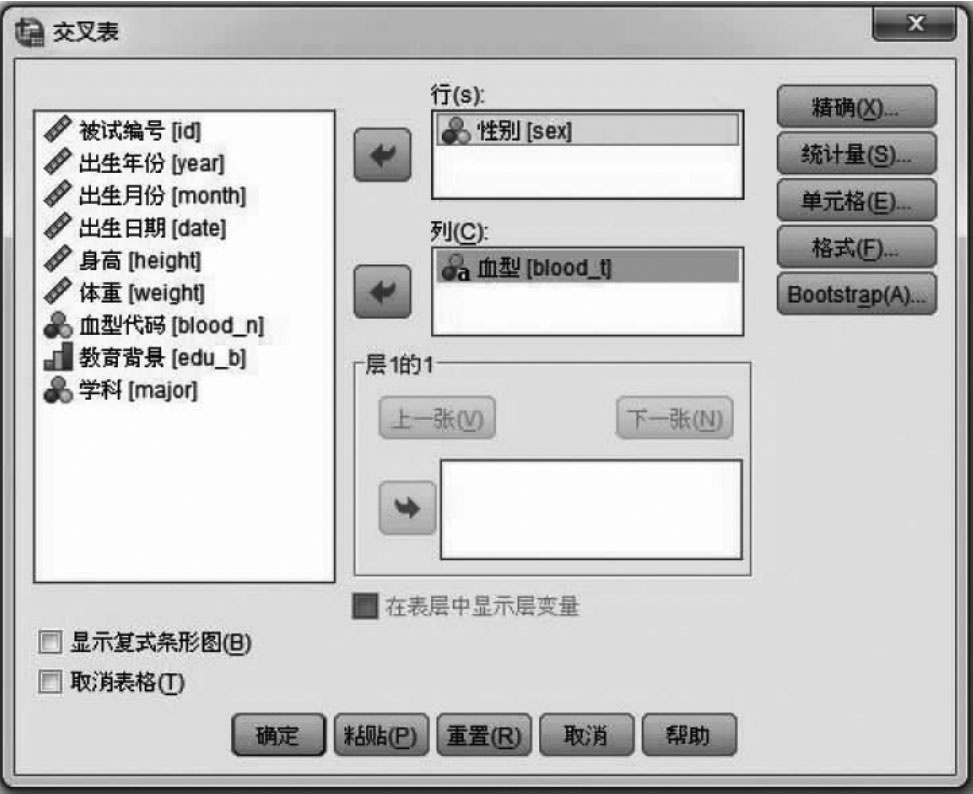
图11-11 交叉表对话框
表11-3 性别、血型交叉表
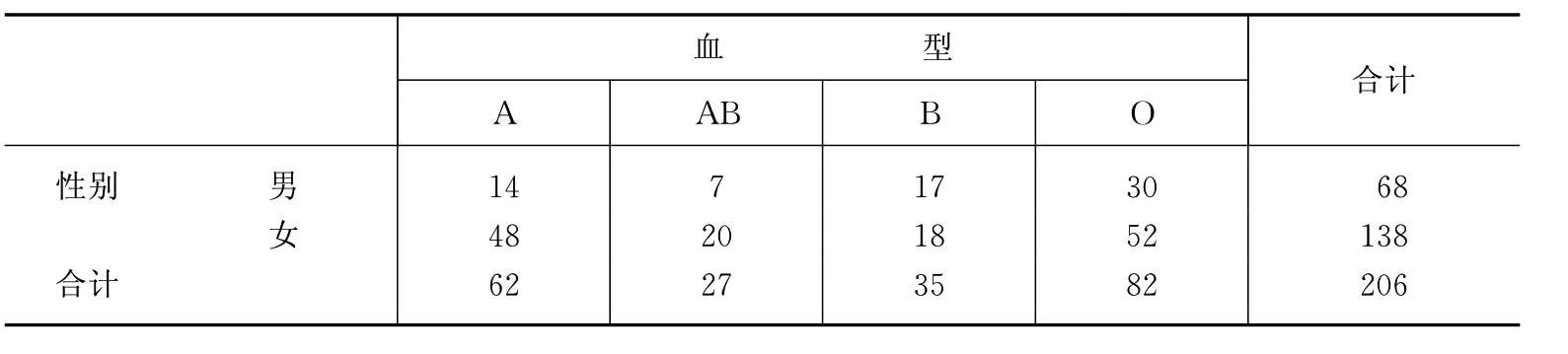
表11-4 性别、血型相依系数表


图11-12 交叉表:统计量对话框
打开后得到如图11-13所示的对话框。
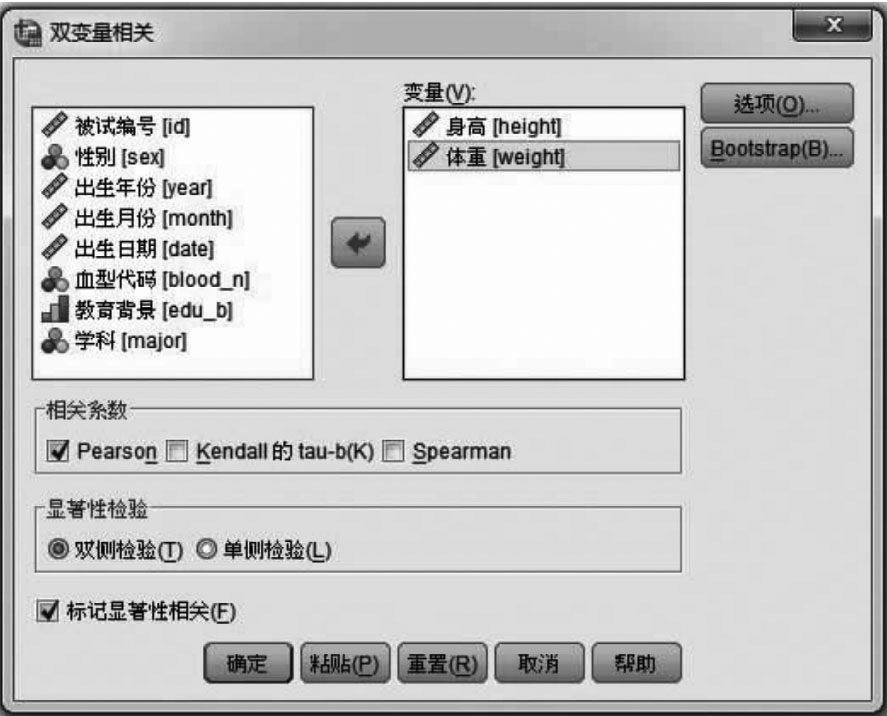
图11-13 双变量相关对话框
对话框中的“标记显著性相关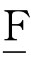 )”框,是要求在结果中用星号标记有统计学意义的相关系数,是系统默认选项,一般都要选择。
)”框,是要求在结果中用星号标记有统计学意义的相关系数,是系统默认选项,一般都要选择。
我们默认对话框中的“选项 )…”钮,单击“确定”钮,输出结果如下。(见表11-5)从表中可以看出,身高与体重的相关系数是0.773,而且具有统计学意义。
)…”钮,单击“确定”钮,输出结果如下。(见表11-5)从表中可以看出,身高与体重的相关系数是0.773,而且具有统计学意义。
表11-5 相关性表
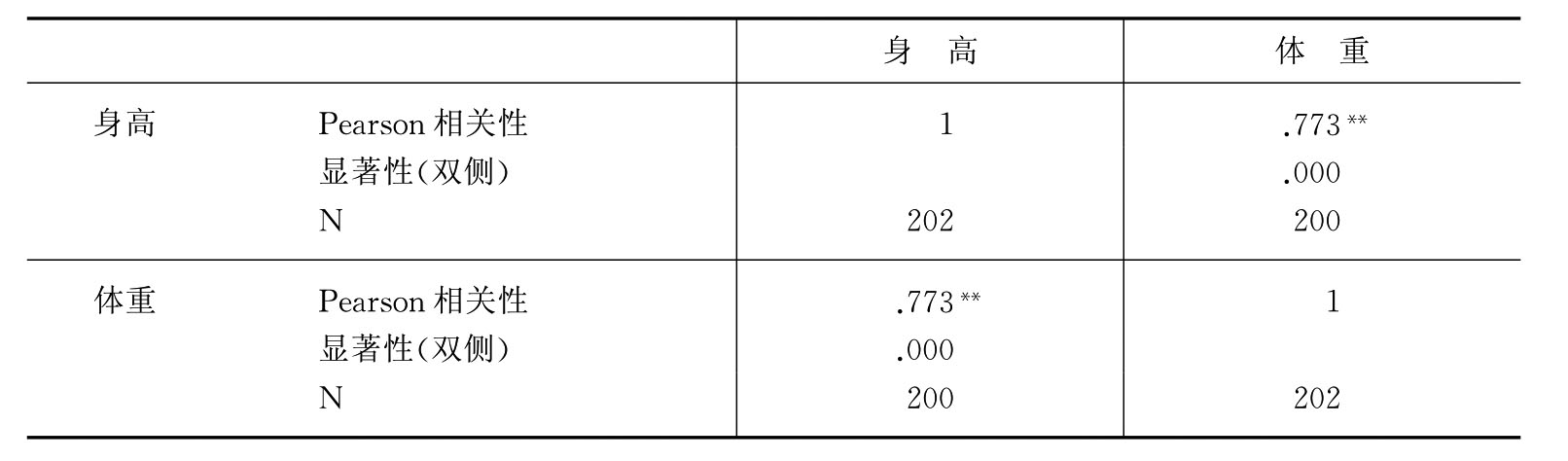
**在.01水平(双侧)上显著相关
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











