



8.4 电子病历的数据处理
电子病历包含了数量巨大、形式多样、纷繁复杂的信息:患者个人一般信息、疾病演变信息、医务人员的个人信息、医疗行为信息、医学知识库、费用支付信息、仪器设备信息、医学伦理信息……对于如此庞大的信息或数据的处理是电子病历系统最核心的部分。
对于电子病历的数据处理,我们将从以下5个方面予以阐述:数据的描述、数据的建模、数据的结构化、数据的录入、数据的显示。关于数据存储主要是依托于使用的数据库平台,大都以XML形式实现。关于数据的集成在下一节专项介绍。
8.4.1 数据描述
在这一节里主要讨论病历数据的特点、描述病历数据有何要求。
纸质病历是一系列有序的文件,其中包含病人在治疗过程中使用的所有药物和收集的相关数据。纸质病历是按特定方式组织的,包括病人姓名、身份和医疗保险等管理性数据;性别、血型和过敏等永久性医学数据(只出现一次);还有一些其他可变性医学数据(多次出现的数据和随时间变化的数据)。
可变性的数据可以进一步分为不同的亚类,比如病史、体格检查和随访检查、实验室检查结果、药物处方、图片(如X线片和闪烁扫描图)、生理信号(如心电图、肺活量)等,如表8-2所示。
表8-2 病历内容中变量的类型

由于病历数据的复杂性,在考虑病历数据的描述方法时必须注重以下处理原则:
1)数据结构基本要求
EMR的各种应用都是以系统中保存的数据为基础的。如果数据不能利用,数据的价值也就体现不出来了,所以保存的数据能否被处理就显得非常重要。
病历的描述方法不仅要满足现阶段的数据处理要求;还要尽量满足今后一段时间内的数据处理要求。病历的描述方法不仅要满足一个部门、一所医院的数据处理要求;还要尽量满足不同部门、不同医院,乃至不同地区的数据处理要求。例如要做流行性感冒的疾病调研,就需要不同地区、不同年份的相关病历信息进行分析。
2)完整性和可靠性
计算机记录数据的一个重要问题是保证上述四种不同类型数据的完整性和可靠性。例如,人工测量的血压是否和传感器测量的血压一样可靠?一个医生使用的代码和另一个医生是否一致?
不完整的数据可以导致不确定性。例如在病历中,医师通常只记录异常信息,而省略、默认正常信息,这样收集在计算机中的病人信息就会缺失,却无法判断这些缺失的信息究竟属于正常的,还是因遗漏没有采集的。不完整的数据会影响电子病历的作用,甚至导致错误的理解。
3)时间的表示
在医疗保健中,时间起着重要的作用。病人的病程随着时间而演变,医生对疾病的认识也随着时间逐步加深,医疗行为都是在特定的时间执行,因此,标记时间是很重要的,病历本身就是按时间顺序的记录。一个EMR系统应允许对一个事件有关的数据使用三个时间标记来标注,即:①数据录入时间;②获得理解的时间;③该理解被应用的时间。
时间表达存在于医疗事件中,它可以是绝对或相对的,在精确度方面相差也很大。在EMR系统中,有关时间的处理是件很复杂的事情。因此,EMR系统首先要能识别出病历记录中哪些信息是“时间”,其次要能对不同形式的时间根据需要进行换算,以满足数据处理的需要。
4)描述方法的规范性和开放性
病历数据的处理必须解决两个重要问题:共享和集成。在异构系统之间进行数据交换必须遵循一定的标准,没有这样的“共同语言”,两个系统之间就不能进行有效沟通。因此,病历数据的描述方法必须实现规范性,同时也要实现开放性,以便于对当前通用的各种数据规范提供良好的支持。
病历数据结构的复杂性和多样性是其特点之一。随着临床工作的不断发展,还会有更多类型的数据出现在病历中。这就需要描述方法具有开放性,能够不做修改或少做修改就可满足新数据描述的需要。例如目前常用的基于XML的描述方法。
8.4.2 数据的建模
我们了解了描述病历数据的要求后,就可以进一步研究电子病历数据的整体模型。HL7V3提出了参考信息模型(reference information model,RIM),它以医疗事件对象为枢纽,对整个医疗数据进行概念建模。在RIM中,整个医疗过程由相互联系的若干事件进行表达,所有医疗数据都可以与某个事件相对应,因此可以通过建立事件索引,串联了患者的全部医疗数据,从而对患者整体医疗数据集建立模型,即医疗事件索引信息模型(healthcare act indexing information model,HAIIA)。
HAIIA模型中的事件索引记录了每个事件的关键属性:主体、客体、事件类型与状态、发生时间与地点、数据位置等。而数据位置属性则记录了对应数据的位置和方式。对于数据不同的状态,再分别定义它的数据结构,如数值和文字数据的关系数据结构、标准化文档数据的CDA文件、非标准化文档数据的PDF(portable document format)文件、医学影像数据的DICOM文件、医学波形数据的MFER(medical wave form format encoding rule)文件等。按照该模型,不仅可以将已有医疗数据结构化地、规范化地归入电子病历中,而且可以扩展不断增长的数据模型和事件类别。
常见的建模方式有三种。第一种是“关系型数据库建模”,这种方式主要是用关系型数据库对病历进行建模,原则是“尽量用计算机来保存数据”。第二种是“基于RTF的病历模型”,是针对第一种方式的改进,目标就是对自由文本进行结构化处理。原先自由文本保存到数据库中时都只是普通的文本,不包含字体等格式控制信息。后来为了丰富显示效果、添加特殊字符,一般都采用RTF(rich text format)格式保存文档。实际上还可以通过XML来处理自由文本,可以直接以XML格式保存数据。第三种方式是树形结构的病历模型,基于“不丢失病历数据”的原则,重点考虑的是如何以结构化的方式保存数据(我们将在下一节具体介绍数据结构化)。树形结构中每一个根节点都表示一份病历文件。每一份文件的内容按照描述的重点可以依次分成若干层次的类别,树形结构相当于病历的骨架,树的结构是动态的,用动态的结构来保存数据。
8.4.3 数据的结构化
1)什么是数据的结构化
结构化数据是指能够用数字或统一的数据模型加以描述的数据,具有严格的长度和格式,如存储在关系型数据库里,可以用二维表结构来表达的数据。非结构化数据的数据长度和格式是不固定的,如文本、图片等。
半结构化数据模型是一种基于图的自描述的对象实例模型,其中数据包括原子数据和复杂数据,半结构化数据通常以标记文本的格式存放。
电子病历数据的结构化不仅需要用统一的数据模型来描述病历,还需要根据数据内在概念的序化和原理的序化被准确地分类和编码,并归属于某一医学分类系统中(具体参见第4章)。这种医学分类系统是电子病历结构化数据的预定义词汇表。
2)为什么需要数据结构化
数据结构化可以看作是电子病历的第一要素,我们从以下三方面予以理解。
首先,只有是结构化数据,并且已被标准化地组织成预定义词汇表,并存放在电子病历系统中,才能被计算机所识别、理解和处理。换言之,如果计算机系统要对病历包含的信息进行有意义的处理,就必须要有标准的、规范的术语和分类系统的支撑。
纸质的病历数据主要是自由文本,即自然语言形式,如病史、病程记录等。但自然语言是非标准化的,因此计算机处理非常困难。自由文本可以看作是书写者对所观测现象的个人解释,如果其他人需要使用这些数据,就必须重新阅读它们,然后根据自己的解释在头脑中重构这些医学现象。因此从语义上讲,自由文本因为结构化不够,往往可以有多种解释,这类解释上的误差是不能用计算机处理的方式予以消除的。
其次,电子病历的主要目的是能对患者诊断治疗予以警示、提醒,提高医疗质量,实现临床决策支持功能,而这些都要依赖于计算机能“解读”病历数据的医学含义,再利用一些规则去分析、运算它们。结构化数据在标准化过程中已赋予它们医学原理和医学概念的内涵,并规范了各数据间相互的逻辑关系,所以能实现上述目标。同样的道理,结构化数据为电子病历的数据挖掘、循证医学、科学研究提供了基础。
再次,电子病历的一个极大的优势是共享性。结构化数据,特别是在最大范围内公认且共用的结构化数据才能实现真正的共享,并为跨医院、跨地区的相互转诊、远程会诊提供基础。
3)如何实现数据结构化
数据结构化的原理和方法在不断探索和完善中,目前,电子病历系统中实现数据结构化最有效、便捷的方法之一就是将国际经典的医学分类系统作为电子病历的预定义词汇表,其代表性的有“国际疾病分类”(ICD)、“人类与兽类医学系统术语”(SNOMED)、检测报告逻辑命名与编码系统(LOINC)……可参见第4章。这些分类科学、完整、严密、广泛而深入,基本覆盖了除中医以外电子病历所需要的数据。
8.4.4 数据的录入
准确而及时的数据录入是电子病历系统中难度最大、费时最多的工作,几乎所有的临床医务工作者都必须参与这一日常性工作。数据录入的方式可以分为三种:自由录入或固定表单式录入方法,开放式结构化录入方法和自然语言处理方法。
1)自由录入或固定表单式录入方式
早期的电子病历采用文本格式的录入方法,也可以由医生护士或聘请专职人员采用手工录入方式,将相关数据录入到病历表格中去,形成电子病历文档。另一种方式是采用语音识别系统,由医生护士口授录入,再审查确认,形成电子文档。它们本质都是手工录入。
固定表单式录入方式的优点是,在较低程度上可以实现部分数据的结构化,技术上要求比较简单。其缺点也很明显:首先限制了医生的思路,将诊疗行为变为一种机械的填表过程。其次,不能适应复杂多变的疾病表现,若要面面俱到又会使表格过于复杂庞大。再次,固定僵化的表格不利于系统的维护,例如患者如果同时存在数种疾病,不能灵活配置表格。因此,表单式录入方式只适用病历中内容相对固定,结构相对稳定,非自然语言描述的部分,例如“体格检查”、“实验室检查报告”。
2)开放式结构化录入方式
开放式结构化录入(open structured date entry,Open SDE)是目前最广泛应用、并具有良好前景的录入方法。
(1)Open SDE的基础。Open SDE的基本条件包括:结构化的病历模型、知识驱动性内容、预定义词汇表与合成表达规则。下面我们借用上述朱××劳累性心绞痛病例予以说明。
①结构化的病历模型:我们已经在8.3节中介绍。根据病历书写规范,为了录入朱××的“现病史”信息,首先选择第1层根目录上的“心绞痛”模板,其次选择第2层子目录上“入院记录”,再次选择第3层子目录上的“现病史”……按照树状病历模型,逐层向下录入。
②知识驱动性内容:自第4层开始,将依据临床医学知识的驱动,展开树状结构。录入朱××的“现病史”信息时,在第4层选择“胸痛”;在第5层,分别设置了9个子节点:部位、性质、范围、开始时间、持续时间、放射方向、诱发原因、缓解原因、硝酸甘油疗效。对于每个子节点,第6层又设置叶节点。例如“范围”这个子节点,第6层又设置了“数值”和“单位”两个叶节点。
③预定义词汇表:开放式结构化录入就是在每个节点选择正确的结构化数据予以录入,这些数据均来自于预先定义的词汇表。这些词汇表绝不是医学词汇的累积,而是根据标准化原理,经分类、编码、可扩充和维护的医学术语分类系统,例如SNOMED等。试以胸痛“诱发原因”为例,若以SNOMED为预定义词汇表,可提供“无明显诱因的”、“运动后”、“因饱餐”、“因情绪激动”、“劳累后”等不同含义的词汇。
④合成表达规则:即将这些不同层次、不同节点的内容按预定的规则合成,去表达明确的医学概念,或者描述明晰的医疗事件。为确保这种描述含义的正确性,电子病历系统会对一些有歧义的部分生成提示性的问题,供录入者选择、修改、确认。
(2)Open SDE的录入方法。有了上述的基础,Open SDE的录入方法十分便捷,步骤如下:首先选择相应的病历模板,由于调用模板的同时也提取了结构,所以医生只需要通过简单的鼠标点击,针对具体病例,在对树状结构的各个节点选择正确数据录入即可,如图8-8所示。
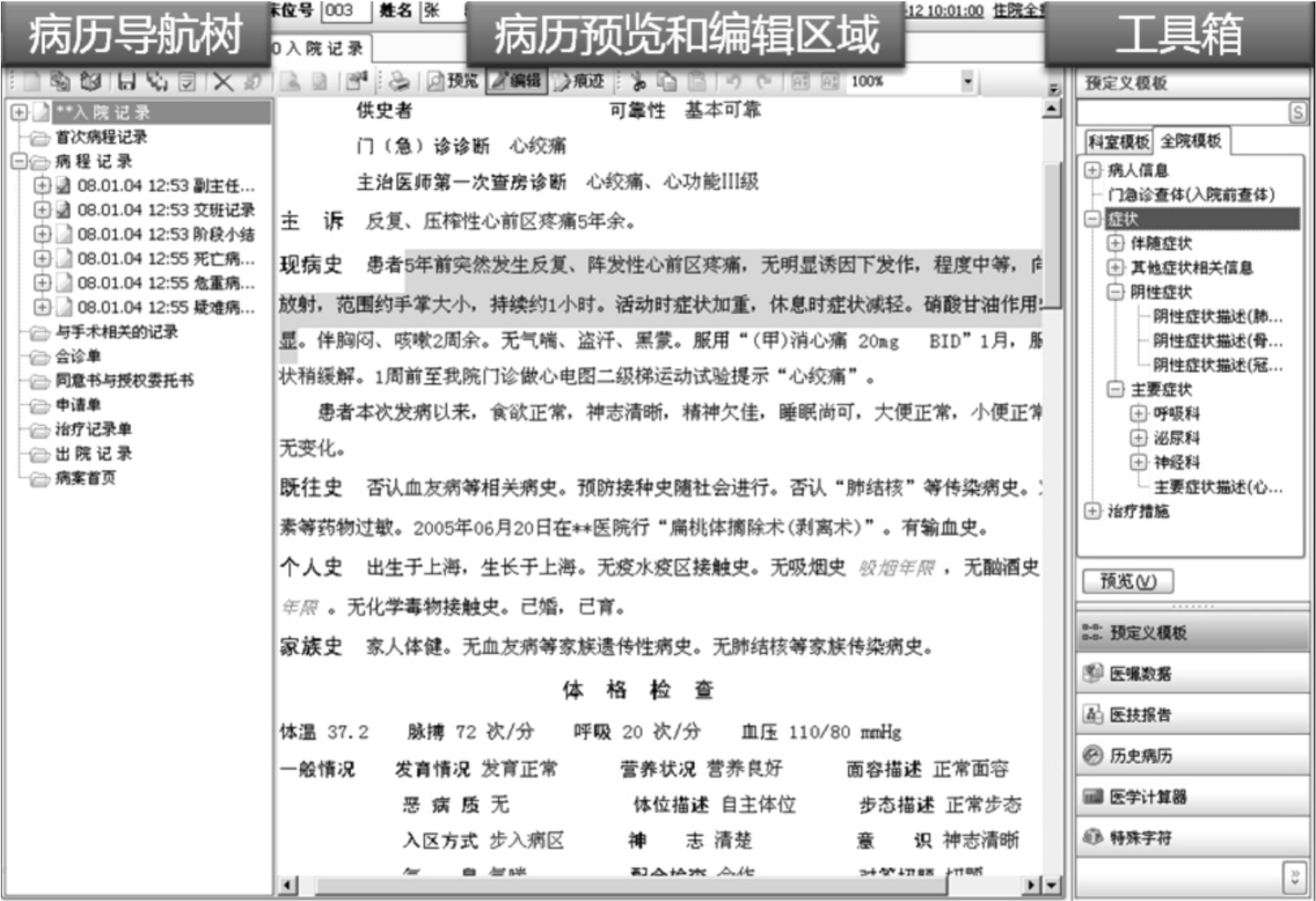
图8-8 开放式的结构化录入
①调用专科或专病病历模板。
②根据患者病情,在通用模板的基础上调整或重组,形成适合于该患者本次就医的病历模型。例如朱××以心绞痛就诊,同时患有“支气管哮喘”病,我们就可以调用与后者相关的病历模板,组装到心绞痛电子病历中。
③菜单驱动用户界面是最常用的录入方法,医生在左侧模型列表中选择项目“入院记录”,即产生下一级若干子项目,再选择“现病史”,于是在界面右侧出现“现病史”录入界面。该界面显示了有心绞痛症状的各节点,选择其中一个的节点,如“发病诱因”,便出现下拉菜单,其中罗列了SNOMED中与此相关的预定义的医学术语,鼠标点击正确术语即可完成,如图8-9所示。
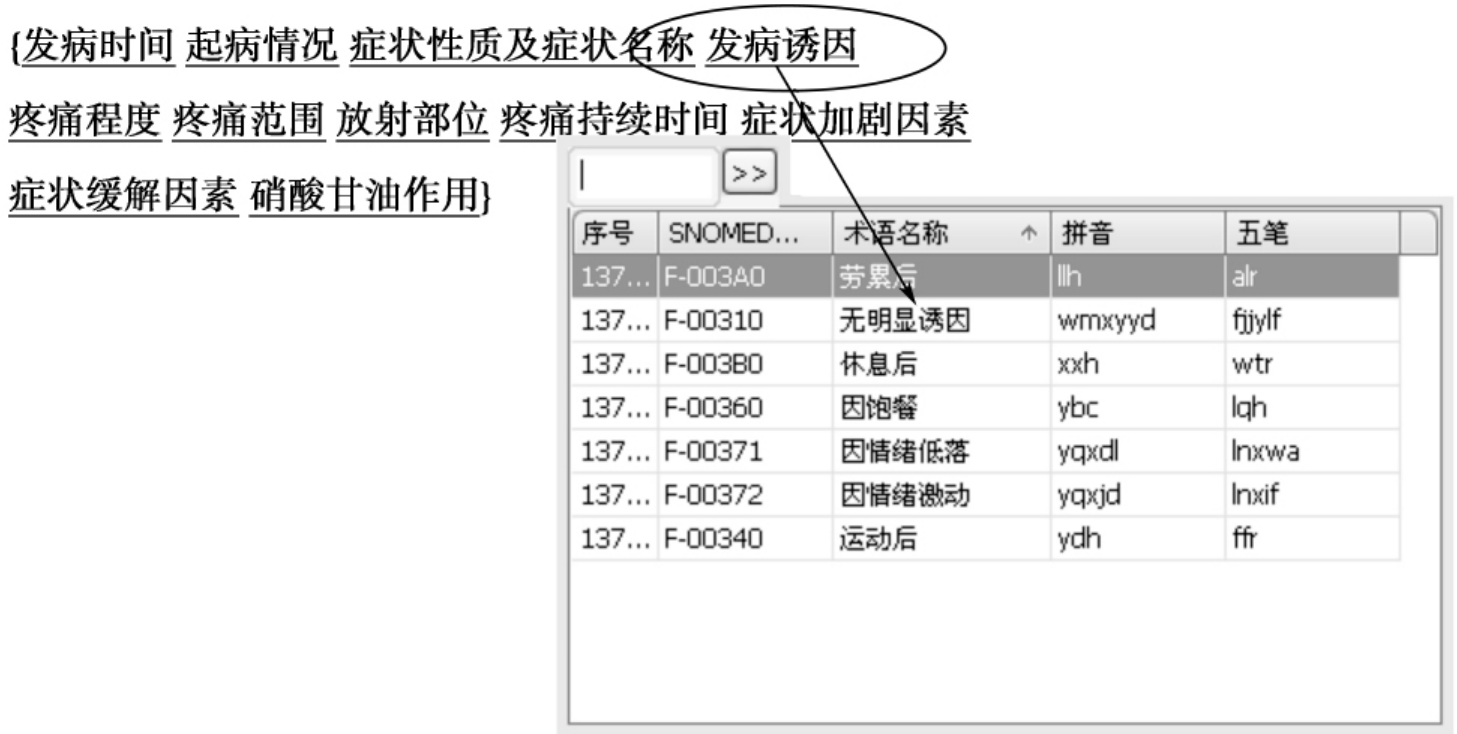
图8-9 Open SDE的菜单驱动的用户界面录入
④表格录入也是常用方法,多见于体格检查、实验室检查的数据录入,也见于症状的录入。例如对于“生命体征”的“体温 ℃、脉搏 次/分、呼吸 次/分、血压 mmHg”则只需直接填入具体数值即可。由于这些表格项目的设置也是预先制定好的结构化医疗概念集合,概念间逻辑关系也预设定了,所以计算机能够理解并自动处理,如图8-10所示。
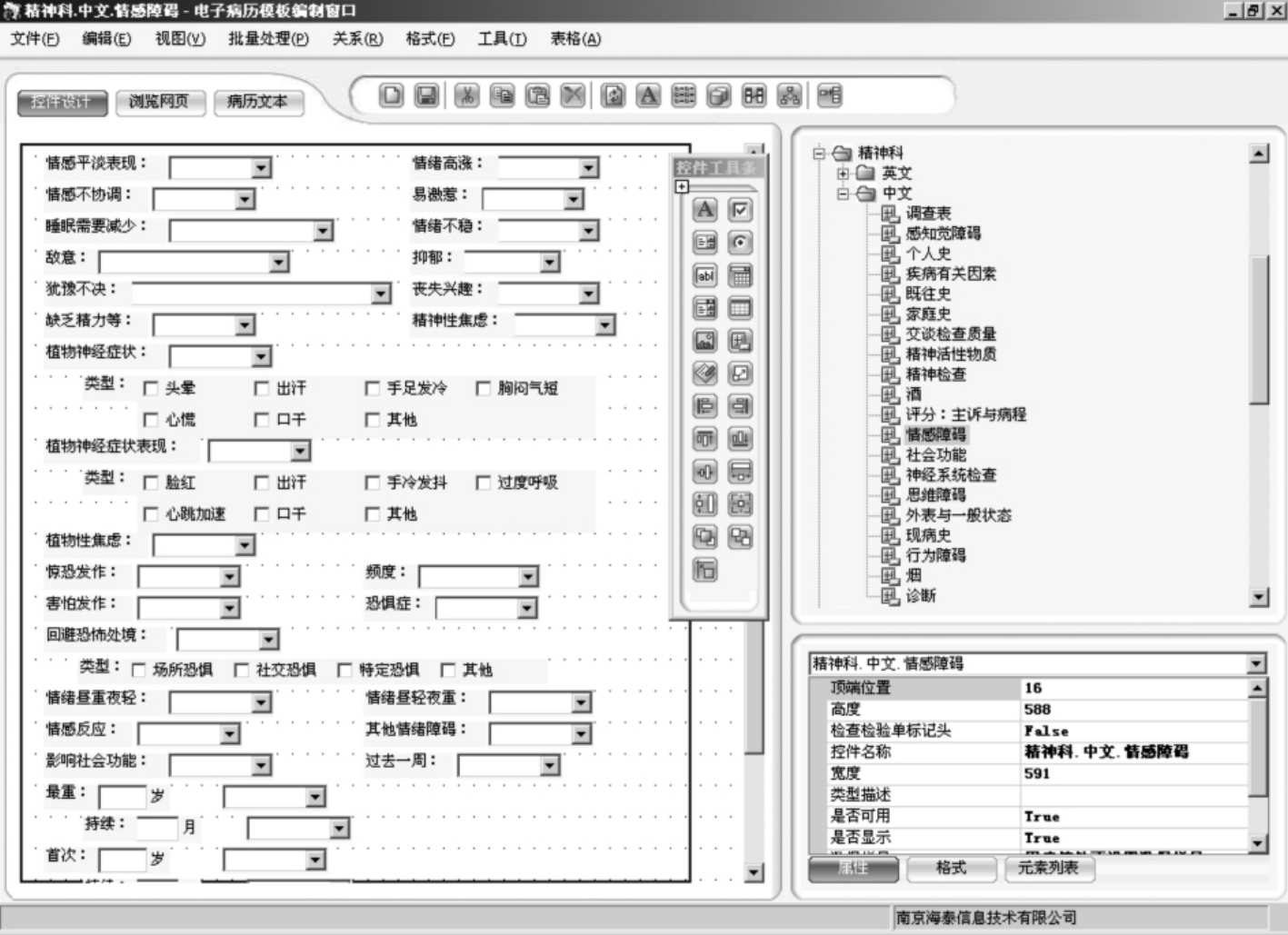
图8-10 表格式录入
⑤其他录入方法。由于电子病历支持多媒体技术的应用,所以具有多种录入方法。例如用图标法来绘制胸部X线病变情况时,可以调用预定义的体表投影图形,在病变的部位作出图形标记,为表示“右上肺空洞”,可以向肺部示意图右上方拖入空心圆圈标记;要表示“左中肺肿瘤”,可以向左中部拖入毛刺样球形标记。
3)高度结构化的录入方式
完全结构化的录入是一个理想的录入方式,然而它存在一些问题。首先医学知识是一个巨大复杂的体系,疾病的诊疗和健康问题是一个庞大深奥的领域。需要用概念粒度较细、严格规范的标准术语建立整个医学概念体系;需要用全面、严谨的逻辑关系表达整体医学概念间关系;这将是一项旷日持久的工程。其次,要医生放弃习惯的文本录入方式采用完全结构化录入是一件既耗费时间又类似机械性的操作,它可能会限制医生的创造性思维。最后,完全性结构化的录入将是一个需要投入巨大物质资源和人力资源的工程。
因此,在完全结构化和自由文本中寻求妥协互补,形成高度结构化的录入方式是现实可行,而且是可以持续发展的。例如在Open SDE方式中允许插入自由文本,以描述那些难以结构化表达的内容,这样的自由文本因为处于结构化的模型中,又尽量采用了结构化的医学词汇,所以也具有一定程度的结构化,便于计算机进一步处理。
4)自然语言处理
自然语言处理(natural language processing,NLP)是指利用信息技术从自由文本上自动提取结构化数据。NLP的优点是医生在书写病历时不必改变他们习惯的记录方式,可以应用自由文本录入,也可以借助语音录入,将结构化的工作交给计算机来处理,NLP可以分析自然语言中的句子,理解其中词汇语义,并自动予以处理,有关NLP我们将在本章第12节阐述。
8.4.5 数据的显示
数据一旦被录入到计算机中,特别是采用Open SDE方式录入,将可以根据不同的目的以不同的形式被呈现出来,而不需要再次录入或手工干预,这是纸质病历所无法实现的,以下是电子病历数据显示的相关问题。
1)数据的可视化
数据显示,首先要解决各种类型数据本身的可视化问题,找出不同类型数据最佳的表达方式,例如对“生命体征参数”数据的可视化表达很简单,如“体温37℃、脉搏80次/分、呼吸20次/分、血压140/90mmHg”;对“医嘱”数据的可视化表达则非常复杂,要制定独特“医嘱范式”。另外,根据不同类型数据的不同需求,有不同的显示方式,如连续滚动、页面扫描、趋势图。
2)数据流程
电子病历中患者数据是根据时间顺序来组织的,数据流程图遵照了“时间—事件”的轴线,形成一个对病历数据综合显示的视图,从而全面、直观、清晰地呈现疾病演变的过程。数据流程图的时间间隔,即时间的粒度,可以根据需要而设置。例如对于重症监护患者的心率、血压监测,时间粒度是以分来设置的;对于门诊慢性病患者的疗效评价,时间粒度可以设置为周或月。
3)数据的概括与摘要
电子病历系统能概括并显示患者的疾病信息,例如对朱×ד心绞痛”现病史,系统可以自动概括出阳性症状(发作性心前区部位疼痛)、阳性体征(早搏、Ⅲ级收缩期杂音)、异常实验室检查结果(心电图S-T段下移,T波倒置)等,最后,自动产生一份简洁明了的病历摘要。
4)动态显示
医师都知道,要从既往纸质病历中查找一个所需的特殊信息有多么困难。美国统计资料表明,在既住纸质病历中,有10%(Fries,1974)到87%(Tang etal,1994)比例的信息,未被医师重新发现。然而,纸质病历无法回答医生的问题,电子病历都可以借助搜寻工具去定位它们,检索出来,并按照医生的意图用设定的格式表达出来。例如对糖尿病人的历次检查的血糖数值,可以用表格呈现,也可以用图形显示,并可以随时更新,动态地反映血糖变化。
5)数据的查询和监测
相对纸质病历而言,数据的查询和监测是电子病历得天独厚的优势。数据查询和监测在原理和方法上相似,医师先设计一个标准,然后利用系统程序去检测、分析病历记录,如果某个或某些记录满足了设定的标准,就可以得到一个恰当的输出——查询结果或者警示信息。
数据检测是防止医疗错误的重要环节,电子病历系统设置了多种类型的数据检测标准。首先是“范围检测”,能发现和预防录入一些超出范围的数值,例如血清钾为50.0mmol/L(正常4.1—5.6mmol/L)肯定是录入错误。其次是“模型检测”,例如患者身份证号码超过18位,肯定为错;处方药品服用剂量是零,肯定为错(参见图8-11)。再次是“一致性检测”,能将录入数据与已有数据进行比对,以检查数据的正确性。例如错误地将女病人性别选择为男性,又记录了既往有输卵管结扎手术史等。
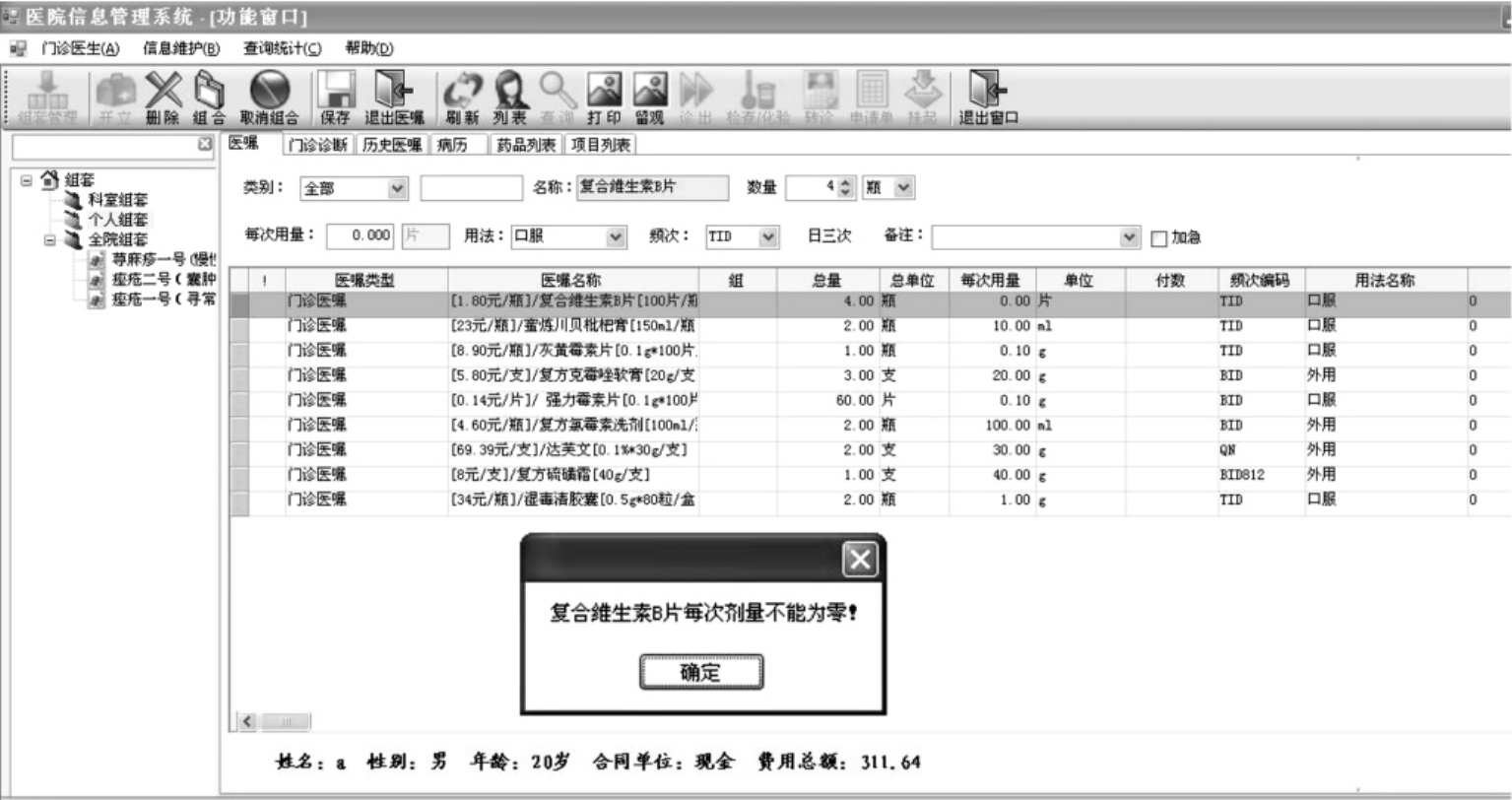
图8-11 电子病历的查询和监测功能
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











