



9.2.1 本体知识组织
作为先进的知识表示手段,本体在知识检索系统中主要用于组织各种检索知识,构建知识库。这些知识库是决定知识检索质量的关键性因素。
一般来说,知识检索领域的知识可以分为三类:
(1)一般性知识:包括语言学知识和常识,它们可以被应用于所有的学科领域。
(2)领域知识:指检索问题的相关知识,包括专业知识、数据事实知识和用户知识。
(3)控制知识:指如何利用上面两类知识实现特定检索目标的知识,包括检索专家的专门知识和检索系统的控制策略知识。
由于知识检索系统涉及的知识数量大、类型复杂,因此一般根据其类型和功能分别存储在不同的知识库中。知识检索系统中的知识库通常可分为语言知识库、专家知识库、领域知识库、事实知识库和用户知识库。在这些知识库的组织与构建过程中,都可以完全或部分地采用本体技术。
1.语言知识库
知识检索系统中的语言知识库用于存放系统所需要的语言学知识,主要包括字典、词典、语法和语义知识,用于支持自然语言处理和自然语言会话。语言知识库在事实数据的解析、领域知识的学习与提取、用户查询式的处理以及用户接口的设计等方面都有着重要的作用。
在基于本体的知识检索系统中,可以将语言知识库的构建考虑为语言本体的构建。语言本体,顾名思义是指反映语言和词汇知识的本体。语言学本体中的概念集合主要包括某种语言的语法要素(如动词、名词、形容词等)和语法关系(如同义词关系、反义关系、语法变形关系等)。
语言学知识属于一类通用的知识,数量庞大且复杂性高,因此在构建语言本体时,首先应考虑是否可以重用已有的本体资源,以便减少工作量,提高效率。目前世界上最著名的语言本体是由普林斯顿大学研制的WordNet。它是一个在线英文词汇参考系统,依据心理语言学的基本理论设计建立。在最新的WordNet2.0中共包含了144 309个英文词汇,115 424个同义词集合,42 000多种名词和动词间的词形链接关系。
WordNet将英文的语言学知识进行逻辑分类组织,形成名词、动词、形容词的同义词集合(Synsets)。每一个Synset代表一个基本的词汇概念,不同的Synset之间具有各种不同的链接关系。另外,依据Synset的类型、区域、用法和注释,将其归于不同的主题领域。下面具体描述WordNet的知识组织结构。
在每一个Synset中都包含一组同义词或词组,以及描述该Synset与其他Synset间关系的指针。一个词和词组可以出现在多个Synset中,位于同一个Synset中的词或词组在文本中可以互相替代。
Synset中的指针所表示的关系可分为两种:词汇关系和语义关系。词汇关系反映词的基本形式和变化形式间的关系,例如,名词的动词变化、动词的形容词变化、形容词的副词变化等。语义关系反映词的意义,主要包括:
(1)上位/下位关系:表示抽象概念与专指概念之间的关系,如果X是Y的一种,则Y是X的上位词,表示X所属的类,而X是Y的下位词,表示该类的一个具体实例。
(2)反义关系:意义相反或相对的两个形容词间的关系。
(3)依赖关系:表示动词间的条件关系。动词X依赖动词Y表明,如果动词Y没有进行,则动词X也不能进行。
(4)半义/全义关系:表示概念间的组成关系,如果X是Y的一部分,则X是Y的半义词,Y是X的全义词。
WordNet中的名词和动词依据Synset间的上下位关系组织为层次结构,其他关系则通过附加指针来指示。具有同一个上位词的词项被称为同位词。
形容词通过族来组织,族围绕反义词对(或反义词三元组)来建立,每个族都由头Synset和Synset群组成。头Synset中包含具有直接反义词的形容词概念,大多数的头Synset还拥有各自的Synset群,Synset群中包含和头Synset中的概念相似但没有自己的直接反义词的形容词。它们与头Synset中概念的直接反义词间具有间接反义关系。
除了上述的反义词结构外,还有一些被称为Pertainym的形容词,它们不具有反义词,只用于描述某个名词所代表的对象的性质。因此,在Pertainym的Synset一般只包含一个形容词或词组,以及一个指向名词的词汇指针,表示该形容词用于描述该名词。如果该形容词是某个动词的分词形式,则还应具有一个指向该动词的词汇指针。
副词一般都从形容词变化而来,有时也具有反义词,因此,副词的Synset通常包含指向它的形容词的指针。
另外,对于那些无法用统一的机器算法处理的词汇的不规则变化形式,WordNet将它们单独记录在特殊项列表中。
通过上述的知识组织结构,WordNet可以比较有效地反映词汇间的各种语言知识关系,并且提供了机器可读的形式化表达。目前在国内虽然也有不少关于中文语言知识表示的研究,但是还没有出现像WordNet这样具有完整语义层次的语言本体,因此这方面的研究还有待进一步加强。
2.专家知识库
知识检索系统中的专家知识库用于存储关于系统控制知识和检索专家的经验知识。这种知识一般是过程型的、动态的,也是影响知识检索系统性能的关键因素。在基于本体的知识检索系统中,可以把专家知识库的构建考虑为检索领域的任务本体的构建。任务本体是一类比较特殊的本体,它以机器可读的形式描述领域专家的行为知识,阐明处理问题的策略、方法和过程,指导计算机自动实现任务目标。
为了便于知识的共享和重用,任务本体应该尽量采用独立于专业领域的结构设计,即专业领域知识的改变只会影响任务的操作对象,而不会影响任务本身的结构定义。
(1)任务本体的结构
行为知识不像一般的领域知识那样具有明确的对象实体,因此对其进行建模的关键问题在于如何对行为知识的要素进行识别。一般来说,任何知识领域内的问题处理任务都可以分为原子任务和一般任务两种。原子任务用于解决最简单、最原始的领域问题,逻辑上不可再分。而一般任务可以分解为若干个原子任务,其结果也由这些原子任务的结果共同决定。不论是哪一种类型的任务,都包括一些基本的任务要素,如执行条件、数据流、功能函数、控制逻辑等。因此,任务本体中必须同时包含对任务要素、原子任务和一般任务的描述。图9-1显示了任务本体的基本结构。
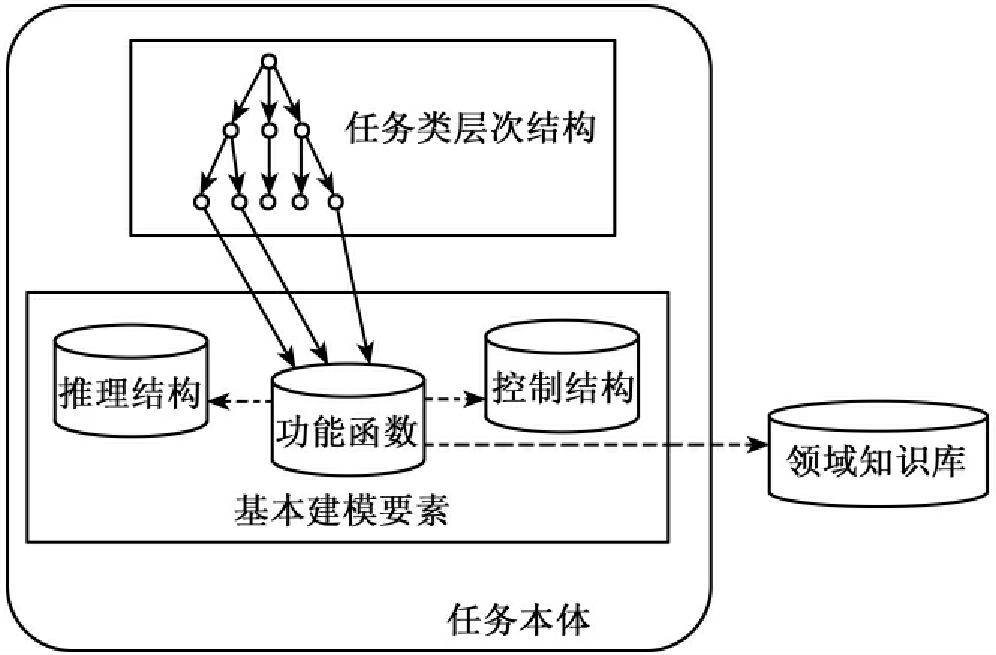
图9-1 任务本体的基本结构图
由图9-1中可以看出任务本体由两部分组成:一是基本任务建模要素部分,包括功能函数、推理结构和控制结构三类建模要素,它们是表示任务的最小实体;二是任务类层次结构部分,包括原子任务和一般任务。原子任务位于类层次结构的底层,由基本建模要素通过结构关系(图中用虚线显示)组合而成。一般任务位于类层次结构的高层,由原子任务组合而成。由此可见,任务本体中的每一个任务都具有其规范的结构。
(2)任务建模要素的表示
每一个任务建模要素都代表了任务的一个维度,彼此互不相交,可以被灵活地组合成各种子任务。
①功能函数。功能函数用于描述任务的数据流。其结构定义如下:
Function-name<功能函数名称>
Class-name<功能函数>
Sub-type-of<功能函数>
Input<数据模型>
Output<数据模型>
Goal-description<功能文本描述>
Assumption<假设条件值>
其中,Function-name槽表示该功能函数的名称,Class-name槽表示该功能函数的类,Sub-type-of槽连接该功能函数的子类。Goaldescription描述该功能函数要实现的目标。Assumption槽说明应用该功能函数时的条件限制。Input槽和Output槽分别描述输入和输出的数据模型。
下面是一个关于用户项查询的功能函数的示例:
Function-name:用户项查询功能#1
Class-name:用户项查询功能
Sub-type-of:检索功能
Input:用户查询项、待查询的本体
Output:本体中与用户查询项匹配的概念类及其子类
Goal-description:“本函数的功能是在本体中检索和用户查询项相关的概念类”
Assumption:用户查询项不为空
②推理结构。功能函数给出了对任务的数据、条件和执行功能的描述性说明,但没有说明其执行功能的具体实现。事实上,功能函数也有高级和低级之分,高级的功能函数可以被逐层地分解为低级的功能函数,直到可以被直接实现为止。推理结构就用来描述功能函数间的这种组合关系,说明一个高级的功能函数推理结构将被分解为哪些较低层次的功能函数,其结构定义如下:
Name<推理结构名称>
Function<功能函数>
Constituents<功能函数集合>
Input-output-dependencies<数据模型集合>
Description<功能文本描述>
其中,Name槽表示该推理结构的名称,Function槽指明被分解的高级功能函数的名称,Input-output-dependencies指明被分解的功能函数的输入/输出数据模型。Constituents槽指明分解所得的成分功能函数的集合。Description槽是对该推理结构功能的文本描述。
对于上面示例中描述的功能函数——用户项查询功能,可以应用下面的推理结构:
Name:查询推理结构
Function:用户项查询功能
Constituents:查找名称匹配的类、查找属性匹配的类、获取子类
Input-output-depenencies:用户查询项、本体中的概念名称与查询项匹配的类集合
用户查询项、本体中的属性值与查询项匹配的类集合
匹配的类集合、本体中的各类及其子类的集合
Description:“该推理结构将用户项查询功能分为查找名称匹配的类、查找属性匹配的类和获取子类三个子功能”
③控制结构。推理结构说明了功能函数的结构组成,而控制结构则将控制逻辑应用于功能函数,说明各组成函数如何按照一定的逻辑顺序协调工作,其结构定义如下:
Name<控制结构名称>
Function<功能函数>
Input-role<数据模型集合>
Working-role<数据模型集合>
Output-role<数据模型集合>
Control-logic<控制逻辑伪代码>
其中,Name槽说明该控制结构的名称。Function槽说明应用该控制结构的功能函数。Input-role、Working-role和Output-role分别用于存储控制结构中可能的起始数据、中间数据和结果数据。Control-logic槽描述各成分函数间的逻辑控制信息。
对于上面示例中的“用户项查询功能”,可以应用下面的控制结构指导其成分函数的执行:
Name:查询控制结构
Function:用户项查询功能
Input-role:用户查询项、本体
Working-role:匹配的类集合
Output-role:相关的类和子类集合
Control-logic:Init(匹配的类集合)
查找名称匹配的类(用户查询项,本体,匹配的类集合)
查找属性匹配的类(用户查询项,本体,匹配的类集合)
Repeat
获取子类(匹配的类集合,相关类和子类的集合)
Until(匹配的类集合为)
Control-logic槽说明了各个成分函数的执行关系,首先是执行两个查找匹配类的功能函数,然后以循环的方式执行获取子类的功能函数,直到所有匹配类的子类都被获取为止。
(3)任务的表示
任务本体中的任务通过分类层次结构组织,不论是原子任务还是一般任务,都具有统一的类结构定义:
Method-name<任务名称>
Class-name<类任务>
Sub-type-of<子任务>
Input<数据模型>
Output<数据模型>
Goal-description<功能文本描述>
Has-inference-knowledge<功能函数>
Has-control-knowledge<控制结构>
Has-domain-knowledge<领域知识模型>
其中,Method-name槽表示该任务的名称。Class-name槽表示该任务所属的类。Sub-type-of槽连接该任务的子类。Goaldescription描述该任务要实现的任务目标。Input槽和Output槽分别描述该任务的输入和输出数据模型。Has-inference-knowledge描述实现该任务所需执行的功能函数。Has-control-knowledge槽描述用于控制功能函数的控制结构。Has-domain-knowledge描述任务执行过程中需要使用的领域模型(来源于领域知识库)。
任务本体中的每一个任务在结构形式上都是完整的,但是内容可以不完整。如有些任务可能没有输入数据,则其Input槽的内容可以为空。
3.领域知识库
知识检索系统中的领域知识库用于存储待检索领域的专业知识,包括专业领域中的各类知识对象及其关系和不同抽象层次的分类概念、主题概念及其关系。在信息检索系统中,专业领域知识一般通过该领域的叙词表来描述。叙词表一般只能实现对浅层知识和显性知识的表示,因而也只能支持简单的基于标引词的检索算法。而在本体的知识检索系统中,通过本体技术抽象和描述专业领域中各层次知识对象及其关系,尤其是对深层知识和隐性知识的描述,多种关联及优化的知识模型的构建,可以支持复杂的相关度计算和推理检索。
(1)概念本体知识库
领域概念知识库的实现过程就是概念知识本体的实现过程,即利用本体的知识要素对概念知识进行建模。建模的过程主要包括类的定义和实例的定义两大步骤。
①类的定义。由于领域概念知识库中的主要实体为领域概念,因此需要定义一个描述其性质的基本类——Topic类,作为基本的概念模型,它是Daml+Oil语言中通用类的子类。
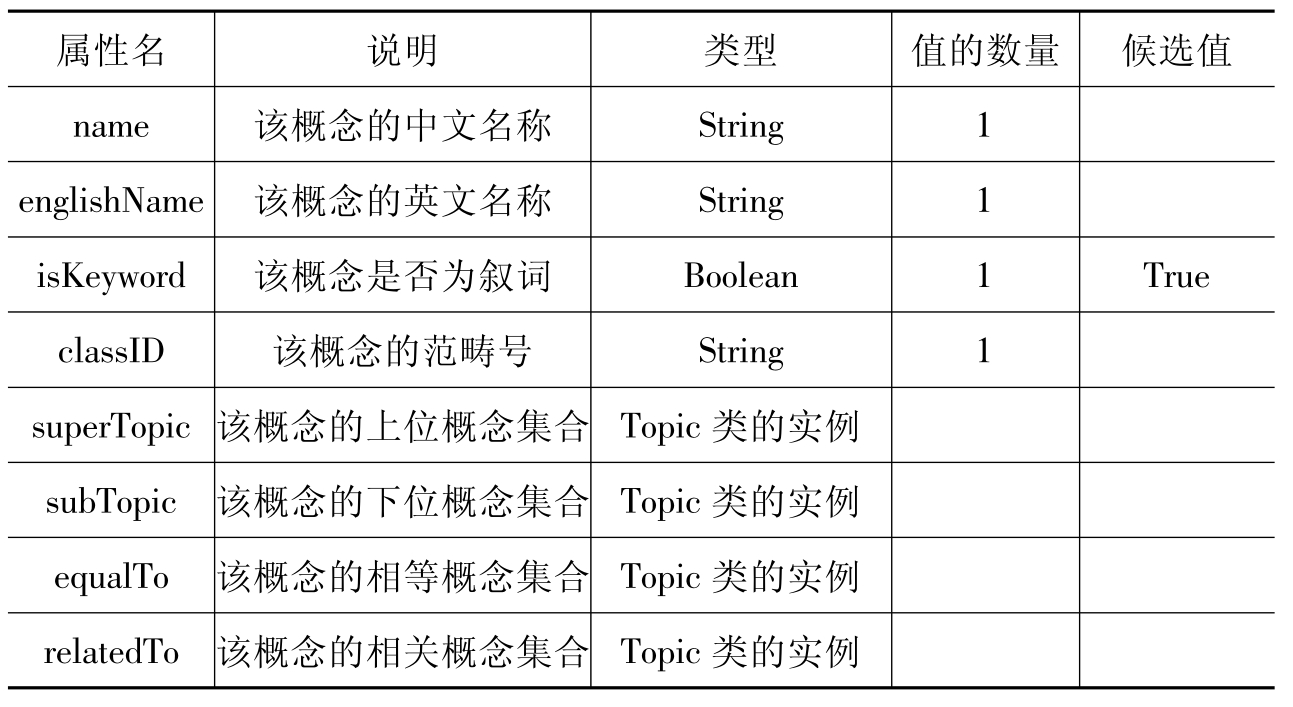
对类的属性和关系的定义主要根据具体的知识检索需求来确定,既要方便对检索算法的执行,有利于检索效率的提高,还要注意简洁易操作。Topic类的各属性槽设置见表9-1。
表9-1Topic类的属性设置
下面是利用Daml+Oil语言对Topic类进行定义的部分示例:
<!--defining class-->
<daml:Class rdf:ID="Topics">
<rdfs:comment>
This class is able to illutrate the relation of words
</rdfs:comment>
<!--限定属性retrieNum的值的数目不能多于1-->
<rdfs:subClassOf>
<daml:Restriction daml:cardinality="1">
<daml:onProperty rdf:resource="#retrieNum"/>
</daml:Restriction>
</rdfs:subClassOf>
<!--限定属性isKeyword的值的数目不能多于1-->
<rdfs:subClassOf>
<daml:Restriction daml:cardinality="1">
<daml:onProperty rdf:resource="#isKeyword"/>
</daml:Restriction>
</rdfs:subClassOf>
<!--限定属性classID的值的数目不能少于1-->
<rdfs:subClassOf>
<daml:Restriction>
<daml:onProperty rdf:resource="#classID"/>
<daml:minCardinality>1</daml:minCardinality>
</daml:Restriction>
</rdfs:subClassOf>
</daml:Class>
<!--defining property-->
<daml:DatatypeProperty rdf:ID="englishName">
<rdfs:comment>
主题概念的英文名称
</rdfs:comment>
<rdfs:domain rdf:resource="#Topics"/>
<rdfs:range
rdf:resource="http://www.w3.org/2000/10/ XMLSchema#string"/>
</daml:DatatypeProperty>
<daml:DatatypeProperty rdf:ID="isKeyword">,……
<daml:DatatypeProperty rdf:ID="classID">,……
<daml:DatatypeProperty rdf:ID="retrieNum">,……
<daml:ObjectProperty rdf:ID="superTopic">,……
<daml:ObjectProperty rdf:ID="subTopic">,……
<daml:ObjectProperty rdf:ID="equalTo">,……
<daml:ObjectProperty rdf:ID="relatedTo">.
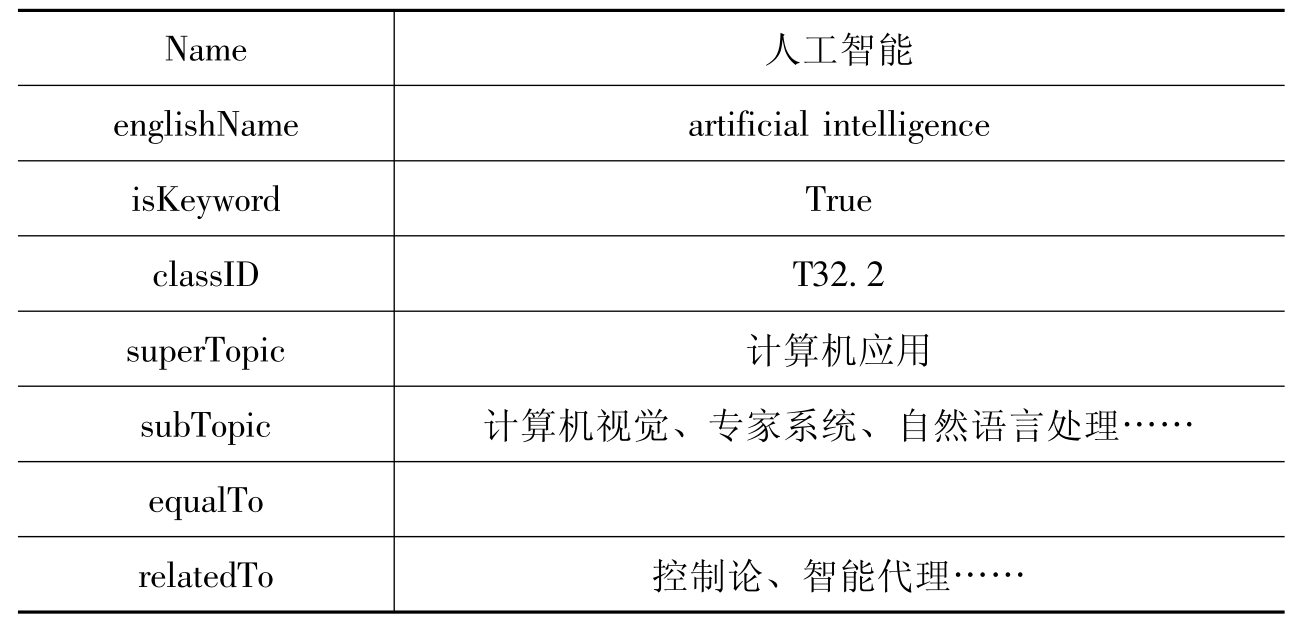
②实例的定义。Topic类只描述了领域概念的框架,不涉及具体的领域概念,只有在本体中加入表示具体概念的Topic类的实例,才能真正形成概念知识库。将Topic类实例化的过程就是将具体的领域概念的性质内容填充到Topic类的各个属性槽中的过程。例如,对于“人工智能”这个概念,其各个属性的值设置见表9-2。
表9-2“人工智能”概念的属性值
实例和实例属性的定义也是通过Daml+Oil语言实现的,例如上面的“人工智能”概念在知识库中的表述是:
<Topics rdf:ID="人工智能">
<englishName>
<xsd:string rdf:value="artifical intelligence"/>
</englishName>
<isKeyword>
<xsd:string rdf:value="T"/>
</isKeyword>
<classID>
<xsd:string rdf:value="T32.2"/>
</classID>
<retrieNum>
<xsd:integer rdf:value="0"/>
</retrieNum>
<superTopic rdf:resource="#计算机应用"/>
<subTopic rdf:resource="#神经网络"/>
<subTopic rdf:resource="#自然语言处理"/>
<subTopic rdf:resource="#专家系统"/>
<subTopic rdf:resource="#机器学习"/>
<subTopic rdf:resource="#计算机视觉"/>
<relatedTo rdf:resource="#控制论"/>
<relatedTo rdf:resource="#智能代理"/>
<relatedTo rdf:resource="#智能接口"/>
<relatedTo rdf:resource="#知识库"/>
</Topics>
(2)本体实例知识库
本体实例知识库包含知识对象、对象属性及其关系的知识,其中还存储了根据领域本体学习的知识。具体概念的实例表达领域中各类实体对象。概念本体的实例化就是在领域概念知识的引导下,描述具体的实体对象的性质内容。领域本体的主题内容、描述方式和详略程度由知识检索系统的应用环境、涉及的专业领域以及检索需求决定。
知识检索系统中的知识对象是对各类实体对象的抽象与描述,包括各种类型事实数据的主题、来源、作者、主要内容等。它既为领域知识库提供基本事实依据,也为检索用户提供最终的事实数据结果。随着计算机技术、多媒体技术和网络技术的发展,可用于知识检索的事实数据的类型和存在形式也大大丰富,例如文本型(如E-mail、电子新闻组、电子书等)、多媒体型(如图像、声音、视频、动画等)、超文本型(Html页、Xml等)的各类事实数据。
下面介绍文献对象类及其实例的描述。
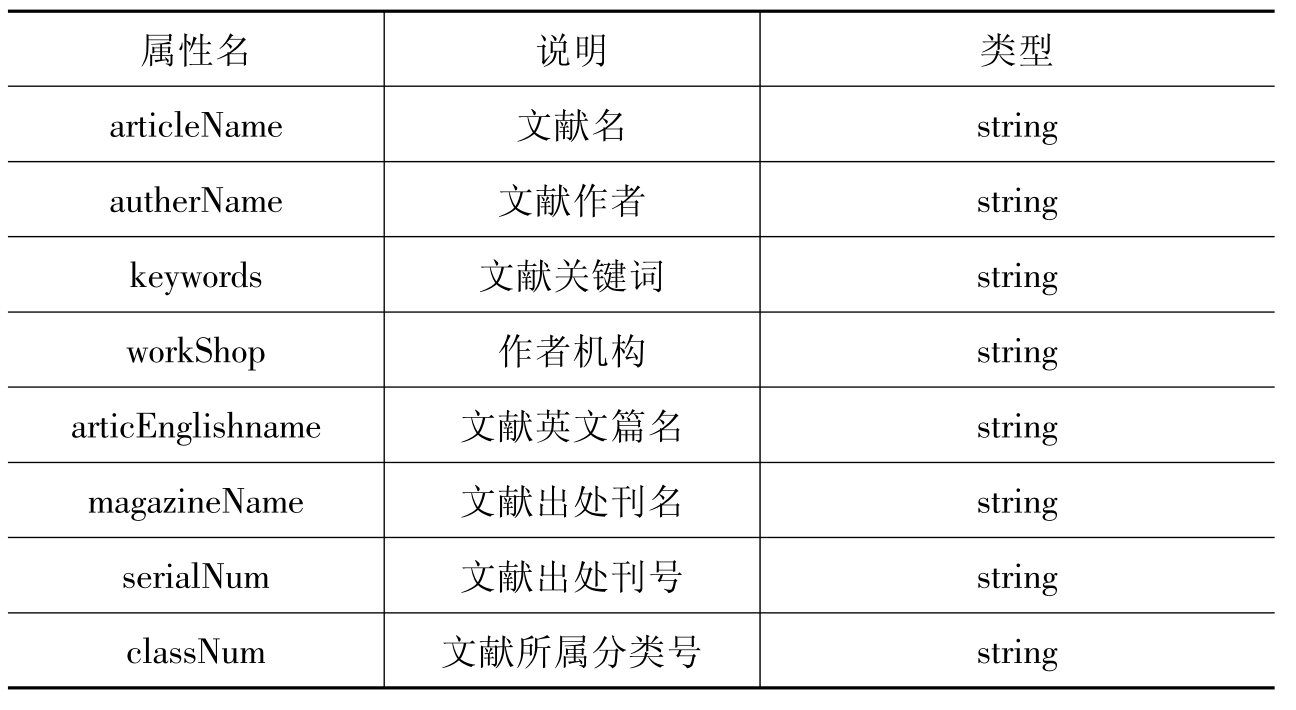
文献对象类的基本模型表示为Article类,该类的属性设置见表9-3。
表9-3Article类的属性设置
Artilces类的所有文献实例的集合就构成了实例知识库。一篇实例文献的知识信息的描述如下:
<Articles rdf:ID="论人工智能对人类认识的影响">
<articleName>
<xsd:string rdf:value="论人工智能对人类认识的影响"/>
</articleName>
<autherName><xsd:string rdf:value="刘枚莲"/></ autherName>
<autherName><xsd:string rdf:value="刘海波"/></ autherName>
<keyWords><xsd:string rdf:value="人工智能"/></ keyWords>
<keyWords><xsd:string rdf:value="认识论"/></ keyWords>
<keyWords><xsd:string rdf:value="智能理论"/></keyWords>
<keyWords><xsd:string rdf:value="语言哲学"/></ keyWords>
<workShop>
<xsd:string rdf:value="桂林电子工业学院管理系广西桂林541004"/>
</workShop>
<workShop>
<xsd:string rdf:value="桂林电子工业学院基建处广西桂林541004"/>
</workShop>
<articEnglishname>
<xsd:string rdf:value="A Study on the Influence of Artificial Intelligence on Human Cognition"/>
</articEnglishname>
<magazineName>
<xsd:string rdf:value="桂林电子工业学院学报"/>
</magazineName>
<serialNum><xsd:string rdf:value="2002.02"/></ serialNum>
<classNum><xsd:string rdf:value="T32.2"/></ classNum>
</Articles>
4.用户知识库
在8.3节中曾经讨论过用户兴趣知识和用户模型,而用户知识库则是知识检索系统中用户模型的集合。在本节中,将研究基于本体技术的用户知识库。
(1)基于本体的用户模型
基于本体的用户模型与其他用户模型不同,它采用分类技术来创建和修改用户模型。每个用户兴趣自然落入其中的某一类。比如在信息系统领域,可以分为行为研究、技术研究和数学研究。进一步细分,技术研究领域可以划分为多个子类,如数据库、决策支持系统、专家系统、人工智能和电子商务系统。这样通过多级分类,有助于准确定位用户兴趣。
用户模型由两部分组成:静态模型、动态模型。静态模型由用户的一些个人信息构成。静态模型一次性生成,类似于“My Yahoo!”的兴趣模型,它的某些部分(如用户偏好)用于系统形成动态模型的初始根据。动态模型是用户模型的重点,也是体现用户个性的所在。动态模型通过分析用户的检索行为,对用户访问的页面进行概念分析,并在领域本体中查找相关类目,修改动态模型,通过不断学习、修改,最终形成能够反映用户特点的模型。
用户模型描述用户的基本知识,主要包括用户的姓名、年龄、学历、专业、爱好等。这种模型的特点是结构稳定,容易建立和操作,而且在用户对系统的使用过程中很少改变。
在基于本体的用户知识库中,用户模型可以用类来定义。一个类代表一种类型的用户,类中的槽用于描述该类用户的特征知识。每一个具体的用户都是类的一个实例。下面是对用户模型类的一般结构的描述:
类名——User(用户)
槽——ID(用户标识号)
Name(姓名)
Age(年龄)
Degree(学历)
Vocation(职业)
Domain(领域知识)
Experience(系统经验)
Others(其他知识)
一个用户知识库中可以包含多种类型的用户模型,每一种类型都描述了一类特定系统用户的公有知识,最常用的类型是专家用户和普通用户。多个用户模型可以采用层次结构进行组织。下面用本体方法描述用户模型的层次结构。
(2)用户模型本体的结构
Daml+Oil语言是在RDFS的基础上扩展而来的专门用于表示本体论的语言,功能很强,可以用于用户模型本体的设计。本体中的分类可以参考主题词表或者网上现有的主题分类结构,如“Yahoo!”。用户模型本体中的每一个分类都是User类的一个实例。下面是用户模型本体中一个实例:
<User rdf:ID="用户标识号">
<englishName><xsd:string rdf:value="专家用户"/></ englishName>
<isKeyword><xsd:string rdf:value="T"/></isKeyword>
<classID><xsd:string rdf:value="T32.2"/></classID>
<retrieNum><xsd:integer rdf:value="0"/></retrieNum>
<super-user rdf:resource="用户"/>
<sub-user rdf:resource="专家用户-A"/>
<sub-user rdf:resource="专家用户-B"/>
<relatedTo rdf:resource="普通用户"/>
</User>
在本例中“用户”是“专家用户”的上位类,而“专家用户-A”和“专家用户-B”是“专家用户”的下位类。与“专家用户”相关的概念有“普通用户”。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










