



5.4 传统知识组织系统的整合
前文对网络环境中知识组织系统定义时曾表明,从传统的情报检索语言发展到网络环境下的知识组织系统,其显著的变化在于由传统环境下各种知识组织工具独立使用发展到将各种不同类型的知识组织工具集成起来综合运用,形成一个知识组织的系统化工具,多角度揭示信息的主题内容,提供多种检索途径。这既是网络环境为信息组织创造的条件,也是网络环境中信息组织的必然要求。其实,早在情报检索语言发展初期,20世纪60年代到70年代初期就已经提出要实现分类主题一体化,即构建分类主题一体化词表[18]。
5.4.1 传统知识组织系统的分类主题一体化
各种类型知识组织工具,无论是术语表、分类表还是主题词表,虽然在标识和组织方式上各不相同,但在本质上是一样的,都是一种概念标识系统,都可用来表示某一信息的主题概念,存在着隐含的概念对应关系,即兼容关系。传统环境中,分类法和主题法的应用最为普遍,所以,分类主题一体化主要是建立分类表和主题词表之间的一种兼容关系,主要的形式有分面叙词表、分类主题词表和综合词表三种形式。其中分面叙词表是编制一部新词表,采用的是一种自顶向下的构建方式在编制词表时就考虑建立分面分类结构,并根据需要对分类表和叙词表实施统一的词汇控制;分类主题词表是在两部已有的分类表和叙词表之间建立兼容关系,不允许对两部源知识组织系统进行大的改动;综合词表是将特定领域的多部分类表和叙词表汇编而成,往往是以一部分类表或叙词表为主干,列出与其对应的其他分类表中的类号或叙词表中的叙词[19]。本节将主要论述分类主题词表的建立,基于集成词表的构建将在第6章论述。
分类主题词表实际是分类法和叙词表之间的互操作,以前,对于分类表与叙词表之间的兼容关系主要是基于图情人员和领域专家的智慧,采用手工方式建立的。如我国最大的分类主题一体化词表———《中分表》,是在《中图法》和《汉表》基础上人工对应编制而成的分类主题一体化知识组织系统,也是两种不同类型的知识组织工具整合、集成的一个优秀范例。其第1版从1986年发起编制,到1994年正式出版,历时8年,投入了40个单位、160多位专家学者和编辑人员来进行人工对应[20];而到2000年4月发起增补修订第2版,在计算机辅助的基础上进行人工对应,投入100余人,仍耗时5年有余,可见其工程之艰巨之浩大。因此,必须充分考虑计算机自动构建或辅助构建的可能。
5.4.2 基于标引经验的分类主题一体化系统
分类主题词表主要是建立分类号与叙词以及叙词词串之间的兼容互换关系,这种关系既包含等值兼容,也包含一定程度的兼容,甚至会出现无法兼容的问题。它主要用作信息标引中查词选类的工具,便于分类标引和主题标引数据之间的转换。而随着标引自动化的实现,这种分类主题一体化工具可以作为实现自动标引和自动分类的知识库,借助于关键词(串)→主题词(串)→分类号的兼容关系来实现抽词标引、赋词标引和自动赋号的功能。但这三者之间关系的建立如果仍是依赖人工完成,那将无法实现高质量的自动标引和自动分类。从目前基于《中分表》的自动标引实验结果可知,效率并不高,因为《中分表》(2版)入口率(非正式叙词与正式叙词比值)为0.32[17],而分类号与主题词(串)之间的对应关系最多一组不足20个,平均为3.63,即一个类目对应3.63个叙词或词串[21],根本无法满足自动标引和自动分类的需要。
分类法和主题词表是两种类型的知识组织工具,在许多书目数据库中,文献信息的标引都会从分类和主题两个方面来入手。因此,对于一条文献,其标引记录一般会同时包括分类信息和主题信息(关键词或主题词)。为了强调这样的标引记录对文献资源内容特征的揭示,王军称其为“语义元数据”[22],也称为标引经验。在传统环境和联机时代,标引人员的智力劳动积累下了大量的对图书、论文甚至多媒体信息资源的主题内容标引记录。这些标引记录仅仅被用来提供信息资源的分类检索和主题词检索,而没有充分挖掘其用来构建分类主题一体化知识组织系统的潜力。因此,本文提出一种基于标引记录的分类类目、主题词(串)和关键词(串)的自动映射方案,形成一个分类主题一体化知识组织系统,用于信息自动标引和自动分类。图5-4简单揭示了基于标引经验的分类主题一体化知识组织系统构建过程。
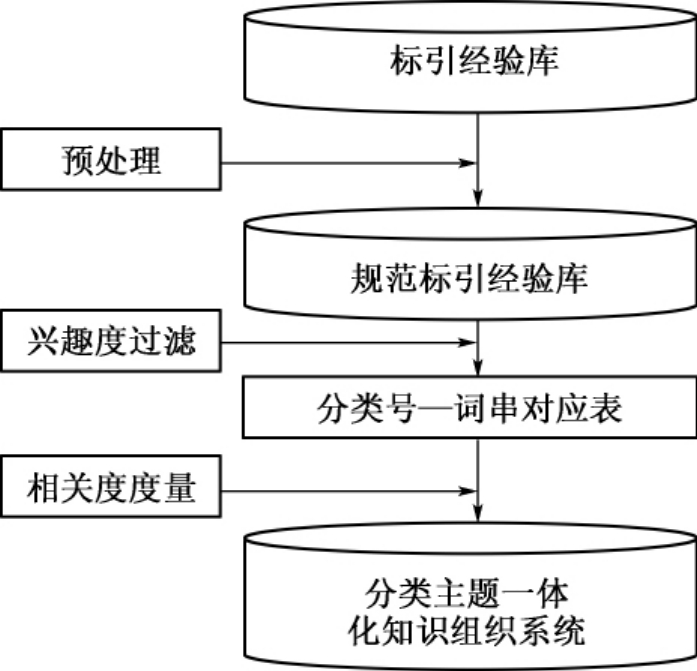
图5-4 基于标引经验的分类主题一体化知识组织系统构建
笔者所在的项目组曾通过搜集大量人工标引记录,建立了《中图法》分类号与关键词(串)、主题词(串)的对应关系,生成了一个可用于自动标引和自动分类的分类主题一体化知识组织系统,称为“《中图法》知识库”,并在上海图书馆《全国报刊索引数据库》中投入使用,达到了实用化。知识库的详细构建情况以及基于知识库的自动分类和自动标引可参见本项目组发表的相关论文。
5.4.3 农史知识组织系统的整合
前面我们分别构建了农史的专业分类表、领域词表、地名表和时代表。专业分类表是农史学科领域的一个知识组织框架,仅仅一个类目及其上下类层级关系并不能反映这个类目的所有主题,而术语及其概念组配后形成的词串,恰恰能深入地揭示出类目的主题。因此,将这两者结合起来,建立映射兼容关系是解决问题之道,这也是分类主题一体化发展对知识组织系统的必然要求。
这里,我们采用上述方法建立这几个农史知识组织工具之间的关系,主要是专业分类表和领域词表之间的对应关系,从而为后面的农史资源库的分类主题一体化浏览、检索及自动标引和自动分类做准备。
本研究将利用农史资源库中的标引记录,挖掘农史专业分类表类目体系与农史领域词表中语词及语词的组配词串之间的概念对应关系,来构建一个分类主题一体化的农史知识组织系统。具体方案设计如下:
(1)农史信息资源标引记录加工与收集
同时具有分类号和标引词串的标引记录,是基于统计构建分类主题一体化农史知识组织系统的数据保障。本文中的农史信息资源标引记录来自两个方面:一是人工标引记录。在构建农史论文全文数据库的过程中,我们采用农史专业分类表和领域词表,对论文数据进行人工分类和主题标引,共形成10 098条人工标引记录。一是来自农业博物馆《中国农史论文目录索引》和犁播的《中国农学遗产文献综录》的题录数据。这部分数据都采用各自的分类体系进行人工分类,通过这些分类体系的类目与构建好的农史专业分类表类目之间的映射,将这些文献统一到农史专业分类表的类目下,然后采用领域词表中的术语词汇对这些题录数据进行抽词标引。这样,题录库中的每一条文献记录,都有一个分类号和一个揭示其主题的标引词或标引词串。合并这两个库中的标引记录,构建出一个拥有约35 000条、同时具有农史专业分类表分类号和农史领域词表词汇的农史文献标引记录数据库。最后,通过统计分析标引记录库中类目与词串的共现情况,可以确定类目和词串概念上的对应关系。
(2)类目与词串关联度度量
要确立农史专业分类表类目与词串的概念对应关系,必须先计算出类目与词串之间的关联度。关联度亦称为相关度,是衡量类目与词串之间概念关系的一个重要参数。影响两者关联度的因素,包括类目的频次、词串的频次和两者同现于一条标引记录的频次。支持度和置信度是数据挖掘中发现关联规则的两个重要参数,同时满足这两个参数阈值的规则称为强规则,即关联性越强。本研究采用这两个参数来评价类目与词串的关联程度[23]。
所谓支持度,表示两者在数据库中的同现概率,一般用类目与词串的共现频次表示,同现频次越大,两者之间的概念关系越成立,可采用公式5-4计算。
![]()
所谓置信度,表示在该类目出现的前提下出现该词串的概率,计算公式如公式5-5所示。
![]()
公式5-4,公式5-5中:
P(class,strings)表示在标引记录库中类目与词串的同现概率,用同现频次co_freq表示;
P(strings)表示该词串在整个标引记录库中的出现频率,用其在整个标引记录库中的出现总频次freq_strings表示。
当某一类目与词串之间的支持度和置信度分别超过设定的阈值,则认为这两者之间有很强的关联,即概念上的对应关系,从而建立其类目与词串的概念对应。
通过试验,本实验中支持度阈值为2,置信度阈值为0.5,生成7 417对对应关系,通过人工审核和少量增补,最后形成7 620对对应关系。农史专业分类表共有504个类目,每条类目至少对应一个词串,最多对应37个,平均每条类目对应15个词串,基本上实现了农史专业分类表与农史领域词表的对应。
图5-5为实现分类主题一体化整合后的农史知识组织系统,左栏为农史专业分类表的树状显示,点击其中任一条目,在右上栏显示其对应的词串,以揭示该类目的主题概念。
图5-5显示出类目“井田制”及其对应的8个词串,分别为:
井田制-田制
井田制-土地制度
井田制-井田-土地制度
井田制-土地制度-春秋时期
井田制-土地国有制-土地私有制
井田制-公田-私田-初税亩
井田制-公私二重性-村社封建制
井田制-土地制度-贡-助-彻-西周
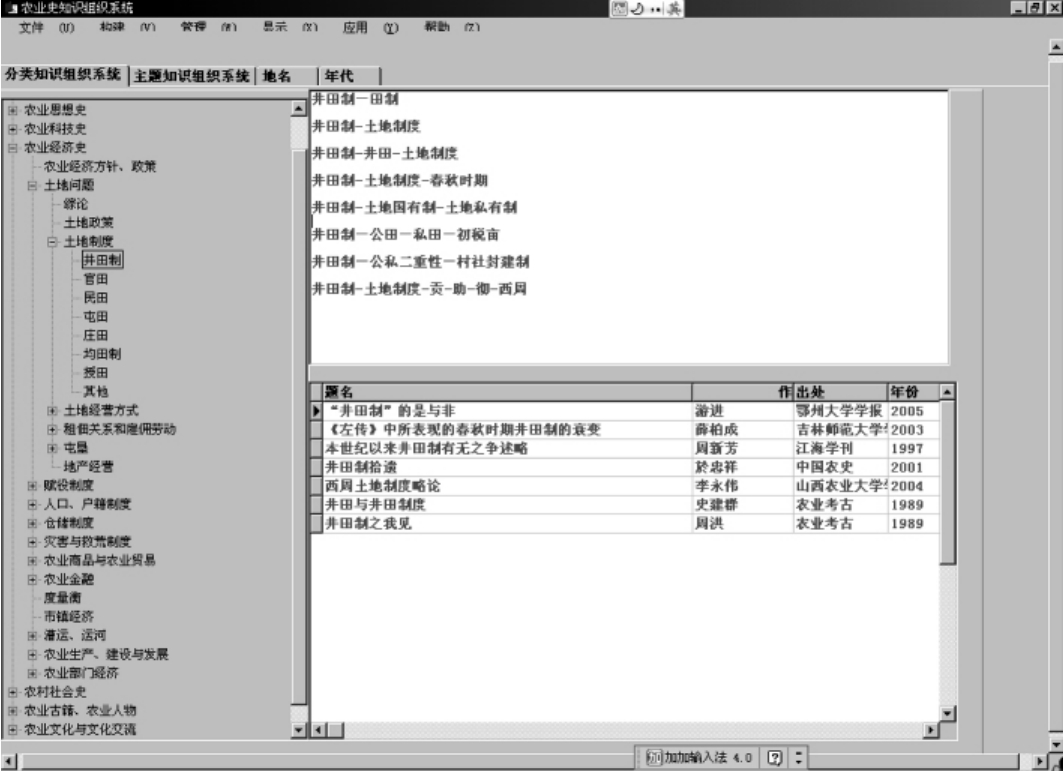
图5-5 农史分类主题一体化知识组织系统界面显示
通过类目与词串的对应,比仅仅通过类目的层次关系和类名能更深层次地揭示类目的主题概念,有助于人们对于类目概念的掌握和理解。
参考文献
[1]吴礼志.《中国网络信息分类法》编制研究[D].武汉:武汉大学硕士学位论文,2004
[2]罗思嘉,等.图书资讯学学术文献主题分类体系之研究[J].台湾大学图书资讯学刊,2001(16):185~208
[3]王强军,李芸,张普.信息技术领域术语提取的初步研究[J].自然语言处理,2003(1):32~33
[4]杨谱春.自然语言叙词表的一种特殊作用———验证创新情报的功能与原理[J].图书情报工作,1999(7):15~17
[5]夏亨廉,肖克之.中国农史辞典[M].北京:中国商业出版社,1994
[6]陈道,北京农业大学.经济大辞典·农业经济卷[M].上海:上海辞书出版社,1983
[7]中国农业百科全书总编辑委员会农业历史卷编辑委员会,中国农业百科全书编辑部.中国农业百科全书(农业历史卷)[M].北京:中国农业出版社,1995
[8]卢嘉锡,董恺忱,范楚玉.中国科学技术史:农学卷[M].北京:科学出版社,2000
[9]黄恩祝.应用索引学[M].上海:上海书店出版社,1993:48
[10]刘建舟.术语自动抽取系统的设计及关键技术研究[D].武汉:华中师范大学硕士学位论文,2004
[11]林颂坚.探勘科学创新与创造力的领域分析工具之研究[C].台北:2005年第三届创新与创造力研讨会,2005
[12]林颂坚.图书与资讯学刊论文的高频词语抽取和分析[J].图书与资讯学刊,2002,42:15~28
[13]林颂坚.基于自然语言处理技术的研究主题抽取与分析[J/OL].(2004-12-21)[2006-3-24]http://www.aclclp.org.tw/rocling/2003/M14.pdf
[14]侯汉清,马张华.文献分类法主题法导论[M].北京:北京图书馆出版社,1999
[15]林颂坚.索引典之自动化建置与视觉化[J].图书与资讯学刊,2005,55:33~50
[16]陆勇.面向信息检索的汉语同义词自动识别[D].南京:南京农业大学硕士学位论文,2005:17
[17]《中国图书馆图书分类法》编委会.中国分类主题词表[M].2版.北京:北京图书馆出版社,2005
[18]张琪玉,侯汉清.情报检索语言实用教程[M].武汉:武汉大学出版社,2004:191
[19]戴维民.信息组织[M].北京:高等教育出版社,2004
[20]《中国图书馆图书分类法》编委会.中国分类主题词表[M].北京:华艺出版社,1994
[21]侯汉清,李华.《中国分类主题词表》(第二版)评介[J].国家图书馆学刊,2006(2):15~21
[22]王军.数字图书馆的知识组织模型———分类法、主题词表和语义元数据的集成[D].北京:北京大学博士学位论文,2003:32
[23]侯汉清,薛春香.用于中文信息自动分类的《中图法》知识库的构建[J].中国图书馆学报,2005(5):82~86
【注释】
[1]此处所指的子串和父串指的是与该字串只相差一个汉字的字串。如“封建”的父串是“封建地”,而非“封建地主”。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











