



15.3 隐马尔可夫模型
前一节中发展了使用一个与具体形式的转移模型和传感器模型无关的通用框架进行时序概率推理的算法。在本节及紧接着的两节中,我们讨论更具体的模型与应用,描述基本算法的能力以及在特殊情况下所允许的进一步改进。
我们从隐马尔可夫模型(hidden Markov model,或缩写为HMM)开始。隐马尔可夫模型是用单一离散随机变量描述过程状态的时序概率模型。该变量的可能取值就是世界的可能状态。所以前一节所描述的雨伞例子是一个隐马尔可夫模型,因为它只有一个状态变量:Raint。其他的状态变量也可以加入到一个时序模型中,同时保持隐马尔可夫模型框架,不过只能通过将所有的状态变量组合成单个的“大变量”的方式实现,其取值范围是全部单个状态变量取值构成的所有可能元组。我们将看到,这种受限的隐马尔可夫模型结构能够得到所有基本算法的一种非常简单而优雅的矩阵实现[22]。第 15.6节说明了隐马尔可夫模型是如何用于语音识别的。
简化的矩阵算法
通过单个离散状态变量Xt,我们能够给出表示转移模型、传感器模型以及前向、后向消息的具体形式。令状态变量Xt的值用整数1, …, S表示,其中S表示可能状态的数目。转移模型P(Xt|Xt-1)成为一个S × S的矩阵T,其中:
Ti j=P(Xt=j|Xt-1=i)
也就是说,Ti j表示从状态i转移到状态j的概率。例如,雨伞世界的转移矩阵为:我们同样可以将传感器模型用矩阵形式表示。在这种情况下,由于证据变量Et的取值已知为,比如说et,我们只需要使用指定出现et的概率的那部分模型。对于每一个时间步t,我们可以构造一个对角型矩阵Ot,其对角线上的条目由P(et|Xt= i)的值提供,而其他位置的条目为0。例如,在雨伞世界中的第1天,U1=true,所以根据图15.2我们有


现在,如果我们用列向量表示前向消息和后向消息,则整个计算过程变成了简单的矩阵-向量运算。前向公式(15.3)变成:

后向公式(15.7)则变成:

由这些公式,我们可以了解到应用于长度为 t 的序列时,前向-后向算法(图 15.4)的时间复杂度是O(S2t),因为每一步都需要将一个S元向量与一个S × S矩阵相乘。算法的空间需求为O(S t),因为前向过程保存了t个S元向量。
除了为隐马尔可夫模型的滤波和平滑算法提供一种优雅的描述以外,矩阵的形式化还揭示了改进算法的机会。首先是前向-后向算法的一种简单变形,使算法能够在常数空间内完成平滑,而与序列长度无关。其思想是,根据公式(15.6),对任何特定时间片k的平滑都需要同时给出前向和后向消息,即f1: k和bk+1: t。前向-后向算法是通过将前向运行过程中所计算出来的f保存起来以便在后向运行过程中使用而实现的。实现这一目标的另一种方法是在单一运行过程里同时向相同的方向传递f和b。例如,如果我们让公式(15.10)从另一个方向执行,“前向”消息f也可以后向传递:
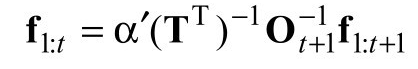
修改后的平滑算法首先执行标准的前向过程计算ft : t(抛弃所有的中间结果),然后对b和f同时执行后向过程,用它们来计算每一时间步的平滑估计。因为每个消息都只需要一份拷贝,存储需求就是不变的(即与序列长度t无关)。不过这个算法有一个显著的限制:它要求转移矩阵必须是可逆的,并且传感器模型没有零元素——也就是说,所有观察值在每个状态下都是可能的。
通过矩阵形式化揭示出可改进的第二个方面是使用具有固定延迟的联机平滑。平滑能够在常数空间里实现的事实提示我们,联机平滑应该也存在一种高效的递归算法——即一种时间复杂度与延迟长度无关的的算法。让我们假设延迟为d,我们要对时间片t−d进行平滑,这里t表示当前时间。根据公式(15.6)我们需要为时间片t−d计算
α f1:t−dbt−d+1:t
然后,当有了新的观察后,我们需要为时间片t−d+1计算
α f1:t−d+1 bt−d+2:t+1
这是如何通过增量的方式实现的?首先,我们可以通过标准的滤波过程,即公式(15.3)由f1: t−d计算f1: t−d+1。
增量计算后向消息则需要更多的技巧,因为在旧的后向消息bt−d+1: t和新的后向消息bt−d+2 : t+1之间并不存在简单关系。反过来,我们将检查旧的后向消息bt−d+1: t和序列前端的后向消息bt+1: t。为了实现这一点,我们将公式(15.11)应用d次得到:

其中矩阵Bt-d+1: t为T和O矩阵序列的乘积。B可以被认为是一个“变换算子”,它将后来的后向消息变换成早先的后向消息。当有了下一个观察之后,对于新的后向消息有类似的公式成立:

考察公式(15.12)和公式(15.13)中的乘积表达式,我们发现它们有一个简单关系:要得到第二个乘积,只要用第一个乘积“除以”第一项 TOt−d+1,然后再乘以新的最后一项 TOt+1。那么,在矩阵语言中,在新旧B矩阵之间有一个简单关系:

这个公式提供了对B矩阵的增量更新,并进而(通过公式(15.13))允许我们计算新的后向消息bt-d+2: t+1。图15.6中显示了保存和更新f与B的完整算法。

图15.6 具有固定的d步时间延迟的平滑算法,作为一种能够在给定新时间步的观察下输出新的平滑估计的联机算法而实现
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











