



10.4.3 信度与效度分析
研究所用量表的信度(Reliability)和效度(Validity)将决定测量结果的可靠性和可用性。因此,在假设检验之前应该对量表的信度和效度进行检验。
信度分析用于评价问卷的稳定性或可靠性,即当问卷对同一事物进行重复测量时,所得结果的一致性程度。信度分析分为内在信度和外在信度,内在信度是问卷的一组问题(整个问卷)是否测量的是同一个概念,即问题间的一致性如何;外在信度是不同时间对同一对象进行测量时问卷结果的一致性程度。
效度分析是为了检验量表是否能按照研究要求,正确测量被测的真实情况。效度分析又分为了内容效度(Content Validity)、构念效度(Construct Validity)、效标关联效度(Criterion-Related Validity)、表面效度(Face Validity)等。
本次问卷的主要组成部分社会网络量表、生命周期量表均是在国外成熟量表(Collins和Clark,2003;Kazanjian,1988)的基础上编制,而企业绩效则是在总结国内外研究成果的基础上再次编制。其中,生命周期量表更是完全引用该成熟量表,并且该量表已经通过了其他学者实证研究的证实(Kazanjian,Drazin,1989;Koberg,Uhlenbruck和Yolanda Sarason,1996),同时该量表为描述匹配型量表,只涉及一个题项,因此,本书研究中的信度与效度分析主要针对社会网络量表和企业绩效量表。
(1)信度分析。
根据研究目的和需要,本书采用了最常用的Cronbachα系数进行内在信度分析。关于其检验标准,一般认为:在0.9以上,该量表的信度较好;0.8~0.9,该量表的信度可以接受;0.7~0.8,该量表有其价值,但需较大修订;低于0.7,该量表需要重新设计。
通过SPSS17.0统计分析软件,对社会网络量表和企业绩效量表进行信度分析的结果表明,社会网络量表和企业绩效量表的总体信度指标良好,Cronbachα系数分别为0.905和0.891,显示出较好的内部一致性。
(2)探索性因子分析。
目前,国内外研究对于量表效度分析的做法一般是,首先通过探索性因子分子(Exploratory Factor Analysis,EFA)研究量表是否适合进行因子分析以及初步评价其构念效度,然后通过结构方程模型(Structural Equation Modeling,SEM)中的相关拟合指数进行验证性因子分析(Confirmatory Factor Analysis,CFA),验证其构念效度(侯杰泰等,2005)。因此,本书首先对社会网络量表和企业绩效量表进行探索性因子分析。
因子分析的默认前提条件是,各变量间必须有相关性,否则变量间没有共享信息,就不存在公因子可以提取。具体方法是采用KMO统计量和巴特利特球形检验(Bartlett Test of Sphericity)进行判断,以考察该量表是否适合做因子分析。KMO统计量是探讨变量间的偏相关性,比较变量间简单相关和偏相关的大小,在0~1之间。一般认为,KMO大于0.9效果最佳,0.7以上尚可,0.6效果很差,0.5以下不适宜做因子分析。而巴特利特球形检验是检验相关阵是否为单位阵,即各变量是否独立。一般认为,当巴特利特球形检验统计量的观测值较大,同时对应的概率p值小于给定的显著性水平时,能够拒绝原假设(原假设为:各变量相互对立),则表示变量间是具有相关性的,适合作因子分析。
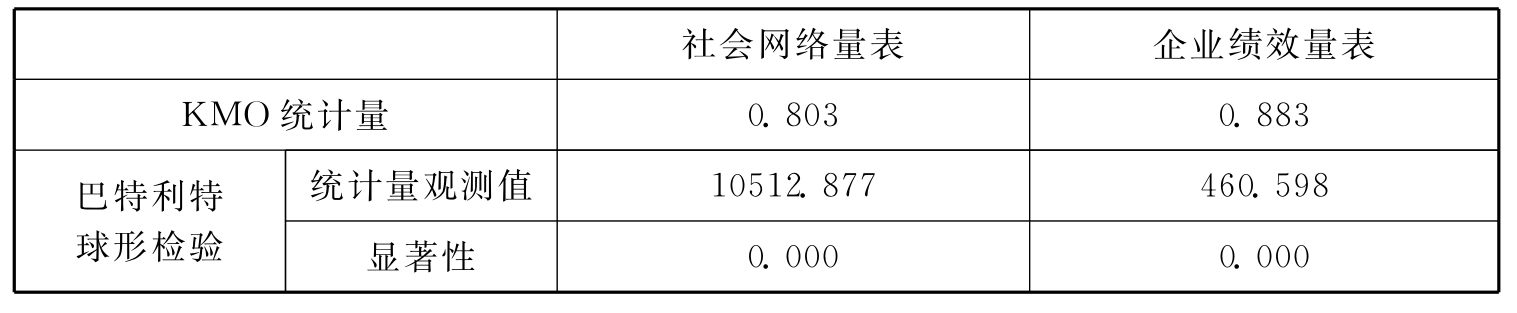
本书通过SPSS17.0统计分析软件,对社会网络量表和企业绩效量表进行了KMO统计量、巴特利特球形检验。结果表明,社会网络量表的KMO统计量值为0.803,大于0.7;巴特利特球形检验统计量为10512.877,对应的P值小于0.01。企业绩效量表的KMO统计量值为0.883,大于0.7;巴特利特球形检验统计量为460.598,对应的p值小于0.01。因此可认为原量表各变量之间存在相关关系,适合作因子分析(如表10.3所示)。
表10.3 社会网络量表和企业绩效量表的KMO以及巴特莱特球形检验结果
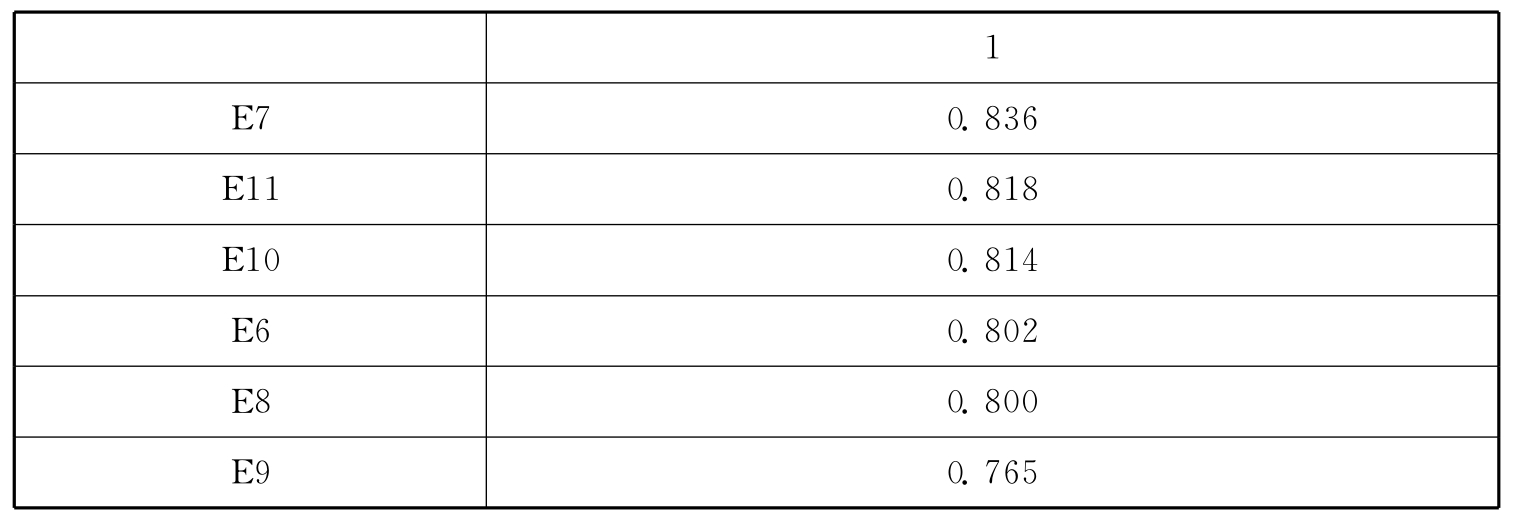
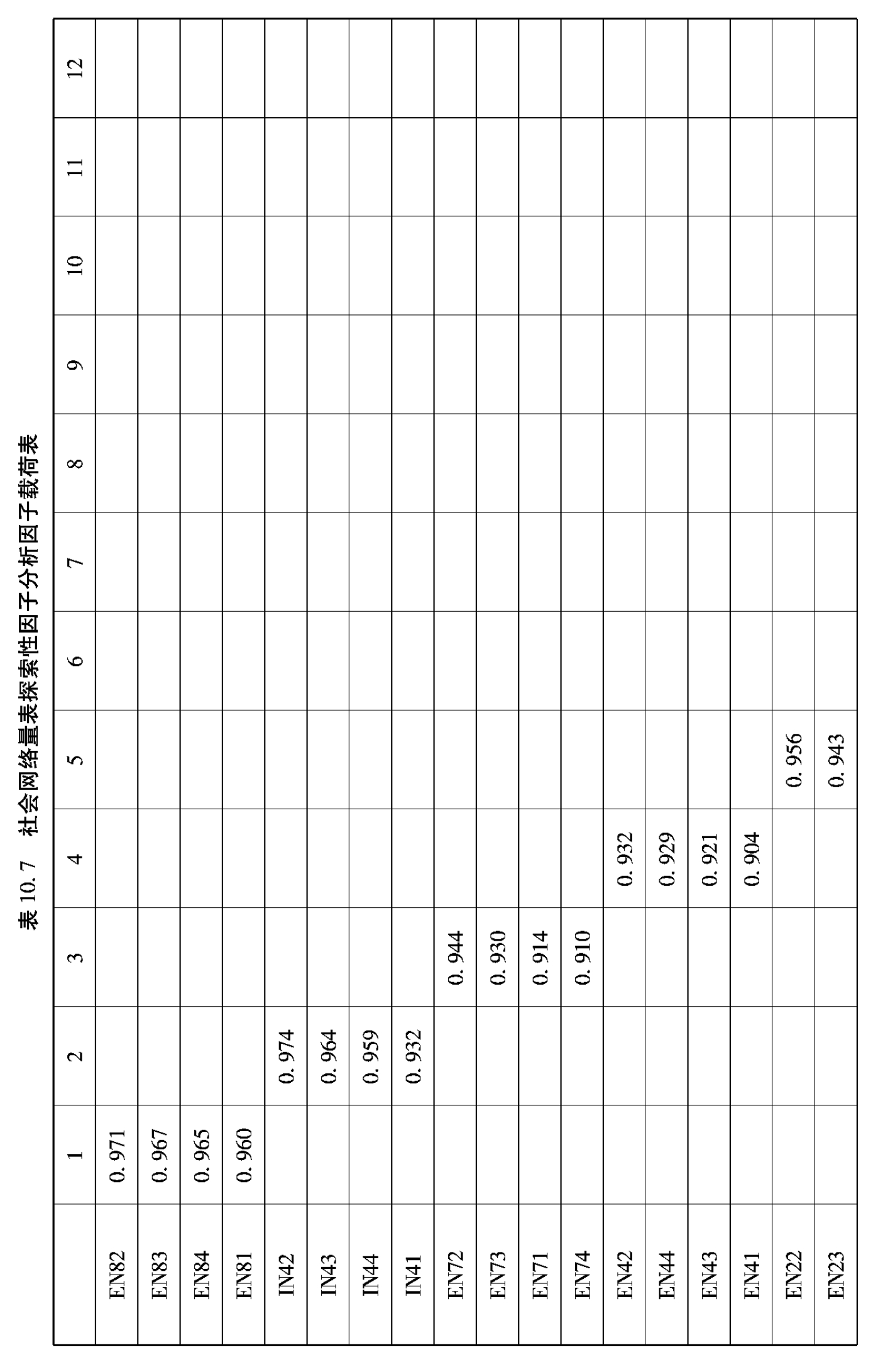
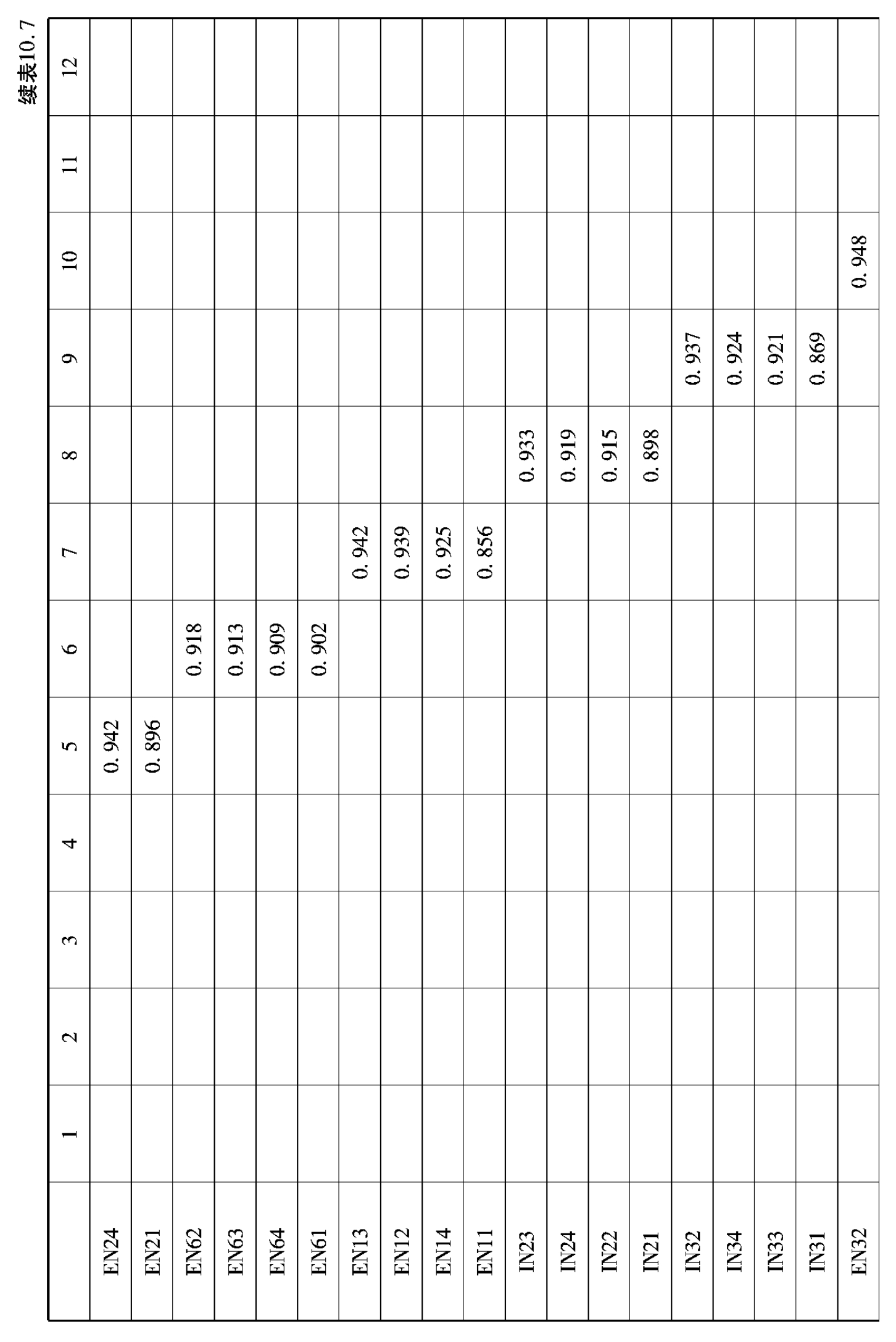
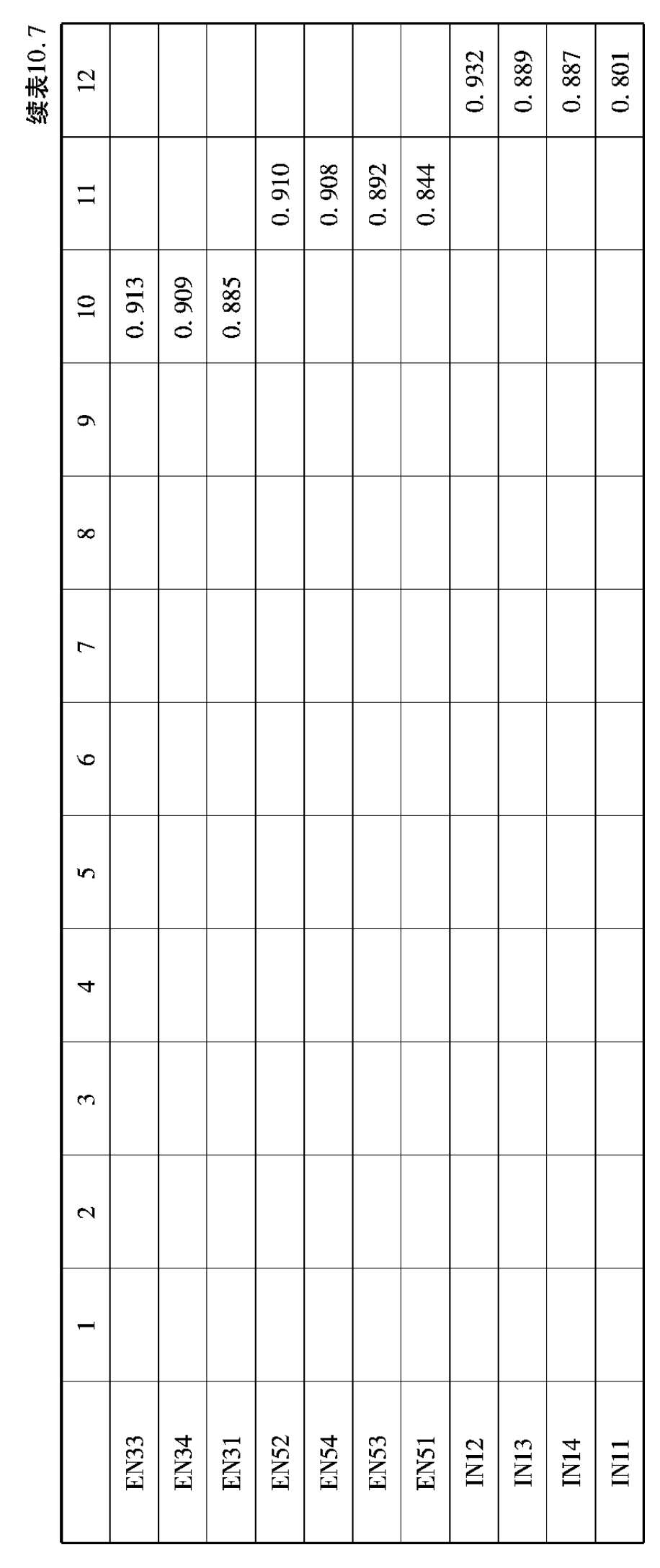
探索性因子分析过程如下:采用主成分分析法,按照特征根值大于1提取公因子,并利用最大方差正交旋转法进行因子载荷分析。根据相关研究,若存在主因子载荷小于0.5,交叉载荷大于0.4的条目,则说明该条目与因子关系不明显,需要删除,以简化问卷,提高因子区分度。探索性因子分析结果表明,社会网络量表共提取12个因子(特征根均大于1),解释了总方差的91.308%,且不存在需要删除的题项,题项在12个因子中分布与原量表中内外网络12个部门各自题项的分布相同,具体情况如表10.4、10.5所示。企业绩效量表共提取1个因子(特征根大于1),解释了总方差的67.943%,且不存在需要删除的题项,6个指标题项均分布在1个共同因子下,即均检测了企业绩效,具体情况如10.6、10.7所示。
表10.4 社会网络量表探索性因子分析因子提取结果
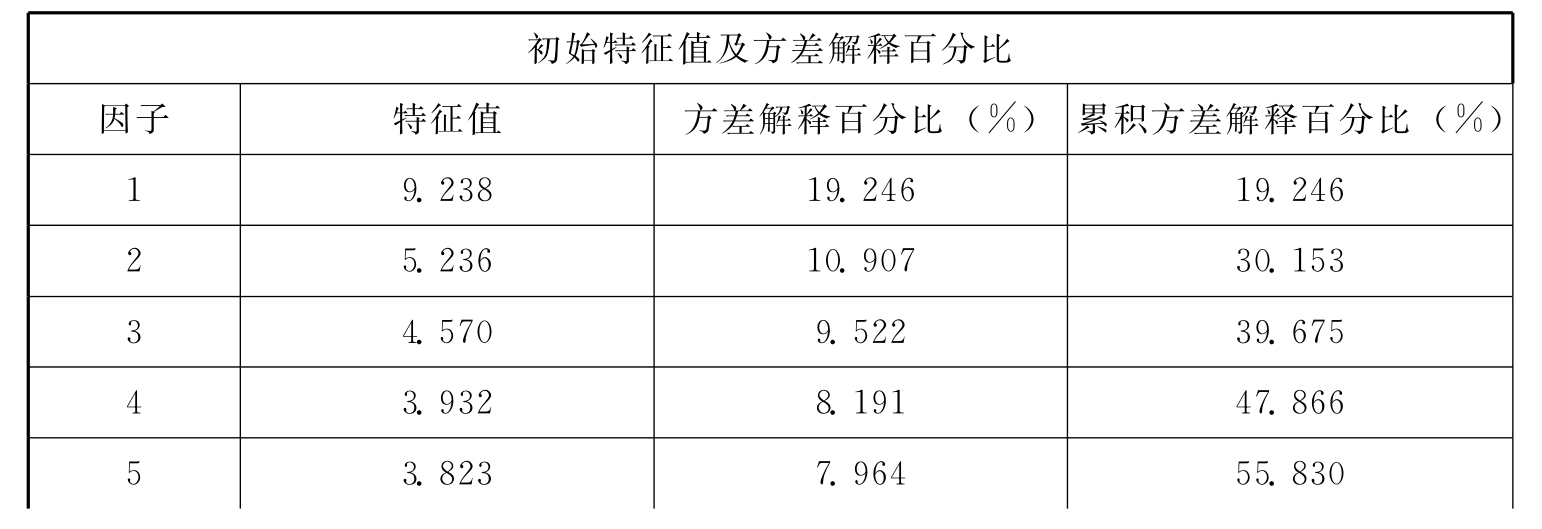
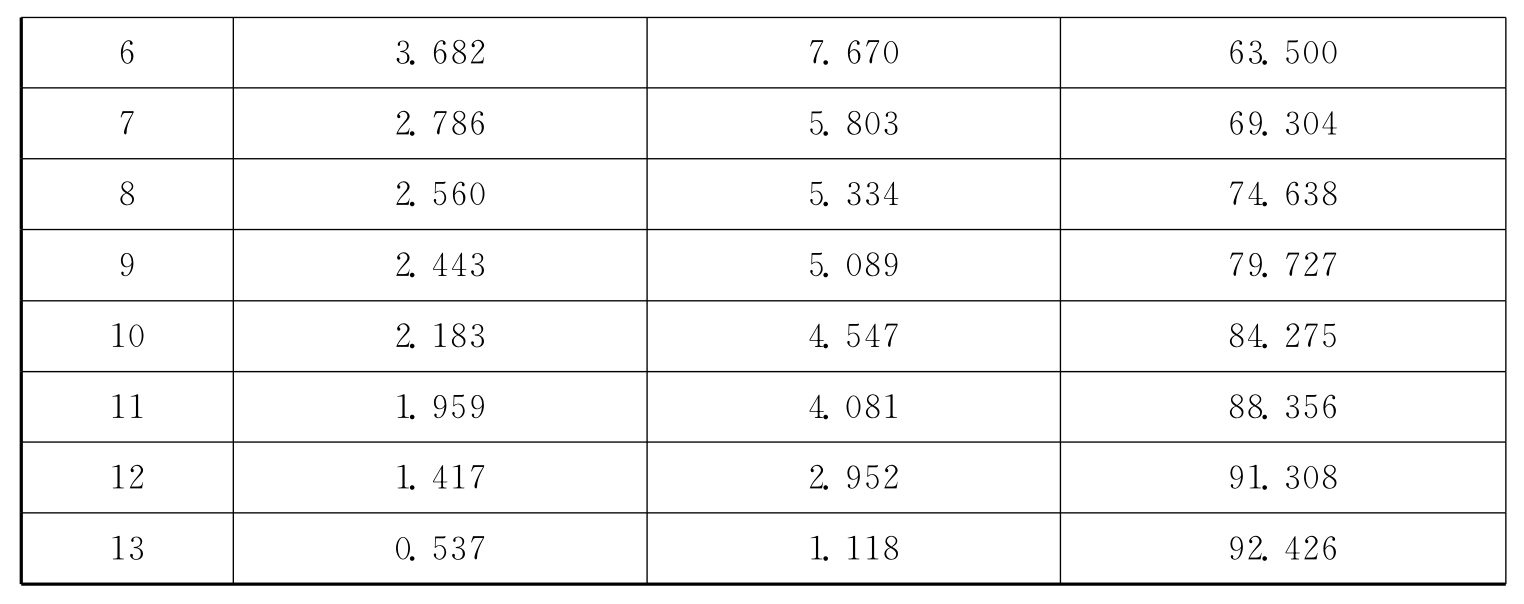
表10.5 企业绩效量表探索性因子分析因子提取结果
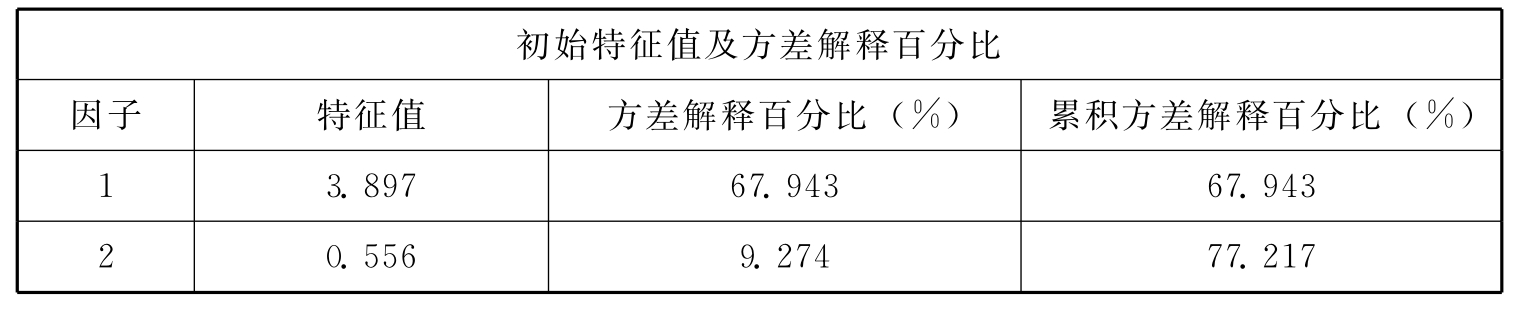
表10.6 企业绩效量表探索性因子分析因子载荷表
(三)验证性因子分析
根据研究目的和需要,本书对社会网络量表和企业绩效量表的构念效度检验使用结构方程模型中(Structural Equation Modeling,SEM)的相关拟合指数进行验证(侯杰泰等,2005),如近似均方根误差(Root Mean Square Error of Approximation,RMSEA)、标准均方根残差(Standardized Root Mean Square Residual,SRMSR)、比较拟合指数(Comparative Fit Index,CFI)、非范式拟合指数(Non-Normed Fit Index,NNFI)等。其中,RMSEA和SRMSR的取值范围均在0和1之间,越接近于0,表示观测数据与模型拟合得越好。按照通用的标准:RMSEA的值大于0.1则模型拟合较差,在0.05到0.1之间则可以接受,小于0.05表示模型拟合较好,小于0.01则模型拟合极好;SRMSR的值大于0.08时模型拟合较差,0.08到0.05之间拟合可以接受,小于0.05则模型拟合较好。CFI与NNFI的取值范围也在0到1之间,但是这两个值越接近1,表示模型拟合越好。一般两个指数的值大于0.9则可以认为模型得到较好拟合,其中NNFI若大于0.95,则说明模型拟合非常好。具体操作将采用LISREL8.70结构方程模型分析软件,相关拟合指数如表10.8所示。
表10.8 量表的信度与效度
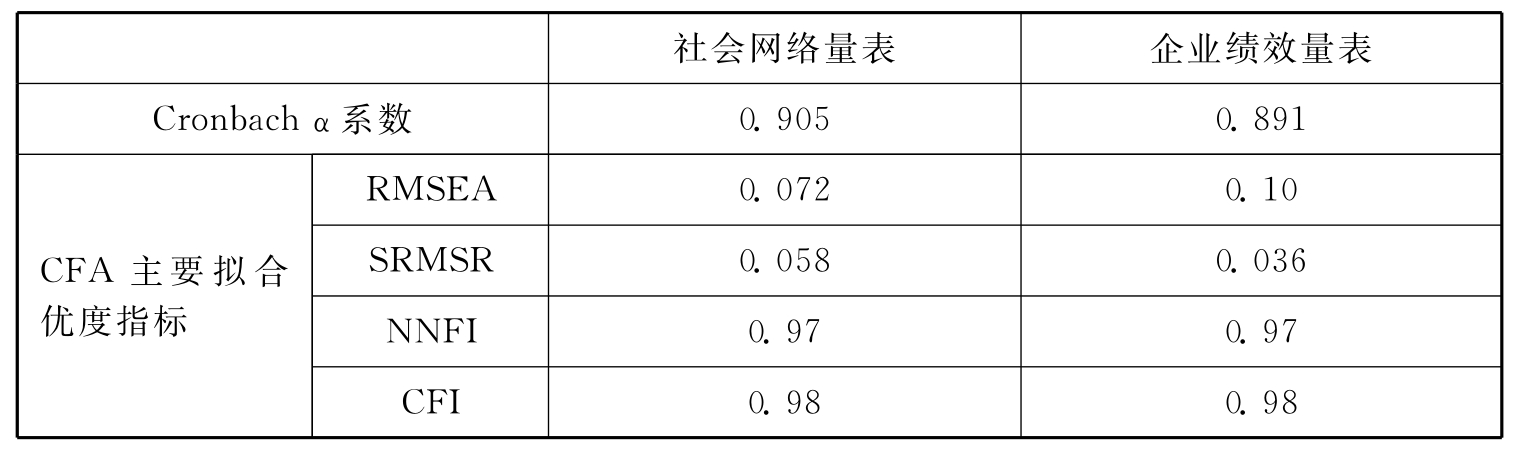
可以看出,社会网络量表与企业绩效量表的Cronbachα系数都在0.9附近,显示出良好的一致性,因此可认为本书研究所用问卷具有良好的信度。同时,虽然企业绩效量表的RMSEA值为0.1,但它的SRMSR值为0.036,小于0.05,NNFI与CFI值都大于了0.95,表示企业绩效量表的数据与模型拟合还是比较好的,说明本次研究的企业绩效量表虽然是根据前人研究结果编制的,但仍然具有较好的信度和效度,能够对企业绩效的测量实现可靠性和可用性。社会网络量表的模型拟合数据均达到了要求,RMSEA和SRMSR值分别为0.072和0.058,均小于0.08,NNFI与CFI值也都大于0.95,说明社会网络量表的数据与模型拟合非常好,进一步证明了前人研究模型的适用性和有效性。因此,综合考虑信度分析与效度分析的各个指标系数,本次研究采用的问卷具有良好的内在信度和构念效度,能够将之用于后续分析和研究。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











