



3.4 基于可变精度粗糙集的风险企业的信用风险识别方法的提出
基于可变精度粗糙集的新兴技术企业信用风险识别方法的基本步骤如下:
1.导出识别规则并构建识别规则库
(1)二维数据关系表的建立
二维数据关系表的每一行描述论域U中一个样本企业;每一列描述了一个属性,属性分为条件属性(即识别指标)和决策属性(即新兴技术企业信用状况较好或信用状况较差)。这样做出的二维数据关系表形成一个决策系统S。数据关系表的建立主要是通过搜集样本企业的各属性值而成的。
(2)应用Mean-mode法进行数据补缺
在实际的数据搜集工作中,数据缺失是很正常的情况,为此需要进行数据的补缺。为了最大限度地保留原有的决策规则,我们采取Mean-mode补缺方法,即对缺失的数值样本属性值用该属性的其他样本属性值的平均数补充,从而得到完备数据关系表。
(3)样本分类
按2∶1的比例将完备数据关系表分为两个数据关系表(对应训练样本和测试样本)。其中:总样本的67%为训练样本(training sample),用来导出识别规则,并进一步构建识别规则库;剩余的33%为测试样本(testing sample),用来检验该方法识别信用风险的精度。
(4)应用启发式算法对数据离散化
运用VPRS模型处理数据关系表时,要求表中的属性值用离散数据表示,而新兴技术企业的条件属性(识别指标值)均为连续值,必须进行离散化处理。因此,首先应用启发式算法对训练样本进行离散化,该离散化方法保持了数据关系表的分类关系,并且得到最少断点的断点集;再利用该断点集对测试样本数据进行离散化处理,从而保证了训练样本和测试样本离散化的一致性。
(5)识别规则库的形成
由于现实数据中往往存在噪音和不一致性,为了提高抗干扰能力,本研究中采用VPRS模型,其中β=0.8。应用遗传算法对训练样本进行约简,并根据支持度条件对约简结果进行筛选;然后依据约简结果导出识别规则;接下来再根据3.3.2介绍的规则价值衡量方法对识别规则进行筛选,从而形成识别规则库。约简算法如下:
算法 基于遗传算法的属性约简:
输入:决策系统S=(U,C∪D),C={c1,c2,…,cn},精度系数β=0.8,群体规模为m,交叉概率为Pc,变异概率为Pm。
输出:属性子集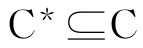 。
。
①将条件属性空间2C编码为染色体,长度为n的二进制串;基因位码值取1,代表包含对应的属性,取0代表不包含该属性;并随机产生m个个体组成初始种群。
②对每个个体x,选择适应度函数
![]()
计算每个个体的适应性[1]。
③个体r被选中的概率为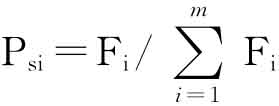 ,以轮盘赌方式进行个体的选择。
,以轮盘赌方式进行个体的选择。
④根据一致交叉算子产生的新个体为
s1′=x11′,x12′,…,x1n′,s2′=x21′x22′…x2n′
O(Pc,x):
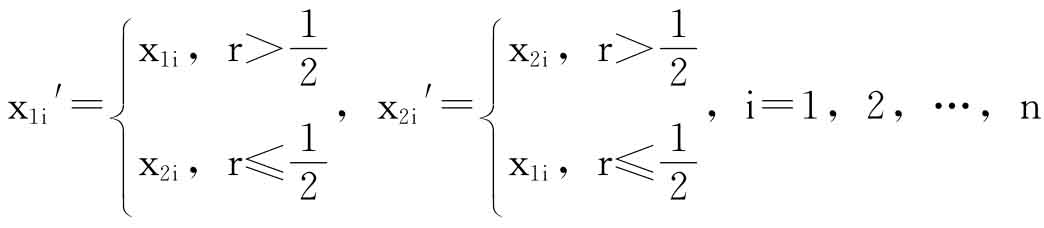
根据交叉概率Pc进行交叉操作。
⑤均匀变异产生的新个体为
s1′=x11′,x12′,…,x1n′
O(Pm,x):
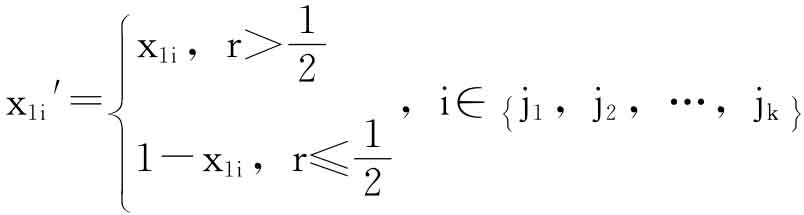
根据变异概率Pm进行变异操作。
⑥判断是否连续t代的最优个体适应值不再提高,如果是,则终止计算并输出最优个体x,并将x*转换为最优条件属性子集C*;否则,转步骤②。
2.基于二叉树建立识别方法
在识别规则库形成后,我们应用二叉树方法,建立基于二叉树的识别方法。首先用规则库中第1条规则对识别样本进行识别,再用第2条规则对第1条规则不能识别的剩余样本进行识别,接着用第3条规则对第1和第2条规则都不能识别的剩余样本进行识别,以此类推。
3.检验识别方法
为了验证方法的识别精度,我们用测试样本对识别方法进行检验。方法基本框架构建的具体过程如图3-1所示。
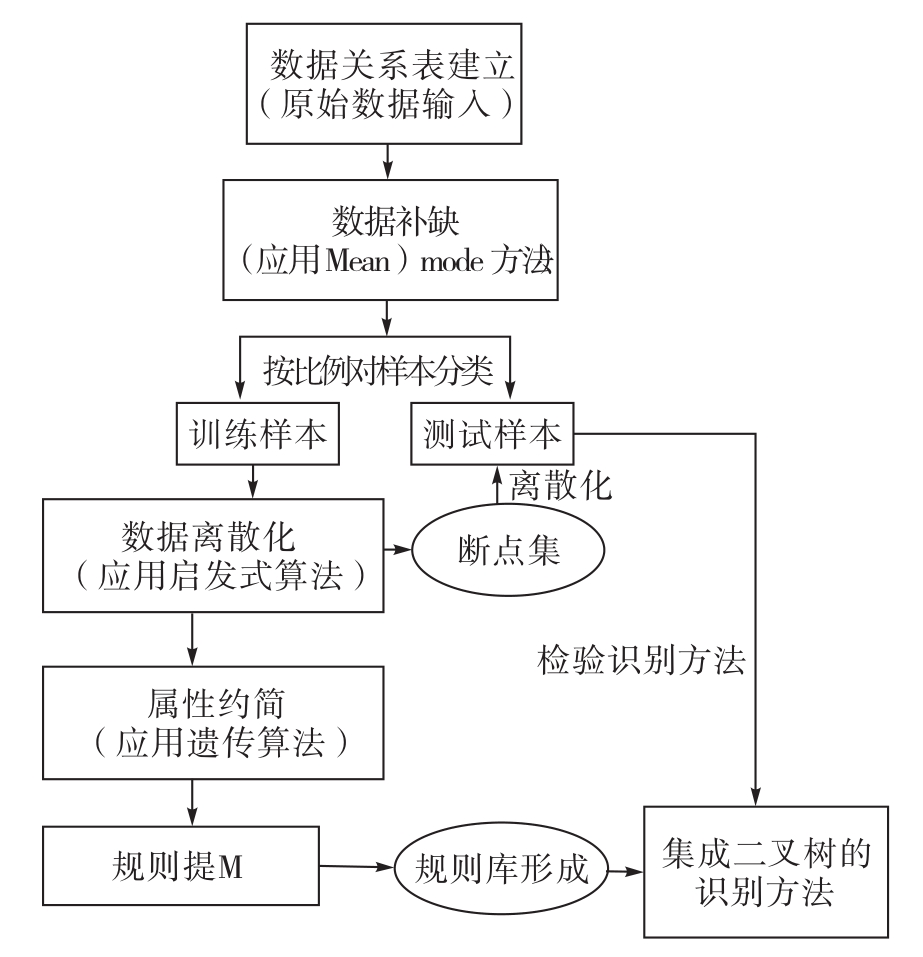
图3-1 基于可变精度粗糙集的风险企业信用风险识别方法的基本框架
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










