



9.1.5 基于粗糙集理论的分类算法
(1)基本概念
粗糙集(Rough Set)理论是波兰数学家Z.Pawlak于1982年提出的,是一种新处理含糊性和不确定性问题的数学工具。它不需要关于数据任何预备的或额外的信息。其研究对象是由多值属性描述的知识系统,形式化定义如下:
定义9-1 一个知识系统S可以定义为一个四元组:
![]()
其中U为关于对象的非空有限集,称为论域;A为对象属性的集合;V为属性值的集合;f:U×A→V为一单一映射,即对A x∈U、A a∈A均有f(x,a)∈V为对象x的a属性的值。
粗糙集是最重要的概念,即不可分辨关系。它是等价关系的交集,本身也是一个等价关系。
定义9-2 在S中,对于任意属性子集P∈A,均可定义一个不可辨关系IND(P):
![]()
在不产生混淆的情况下可以用P代替IND(P)。
IND(P)是集合U上的一个等价关系,因此集合U可以根据等价关系IND(P)进行等价类的划分。
定义9-3 集合U对于等价关系IND(P)的划分记为U/IND(P),其计算公式如下:
![]()
其中运算符×定义为:
![]()
在不发生混淆的情况下,U/IND(P)也可简记为U/P。
示例:表9-1是一个知识表的例子[5]。
表9-1 知识表示例表
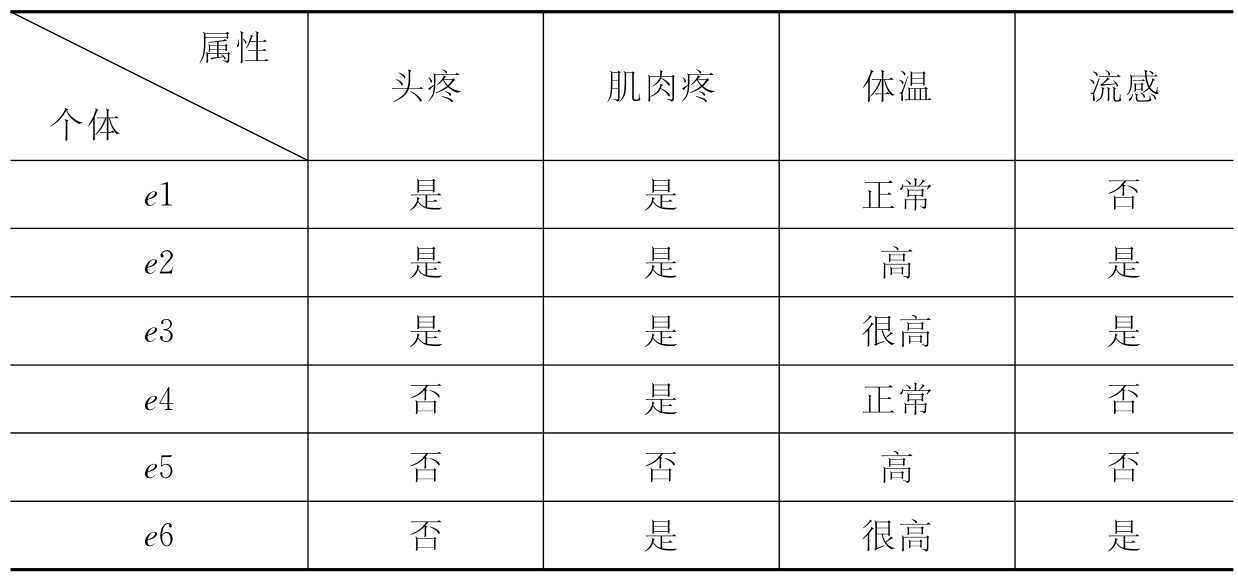
在表9-1中,可以使用不同属性对样本集合进行分类。比如U/头疼和肌肉疼={{e1,e2,e3}{e4,e5}{e6}}。其中{e1,e2,e3}彼此之间相对于属性子集“头疼和肌肉疼”都是不可辨的,{e4,e5}也是如此。也就是当给定属性头疼为“是”,肌肉疼为“是”时,我们无法确定所描述的对象是e1还是e2还是e3。
在不可分辨关系的基础上可以定义粗糙集的上近似和下近似,从而刻画集合的粗糙性,反映事物的知识粒度。
由此可以看出,粗糙集方法是一个基于一个或一组机构关于一些现实的大量数据,以观察和测量这些数据进行分类的能力为基础,从中发现、推理知识和分辨系统的某些特点、过程、对象等的方法。
(2)精确集与粗糙集
我们称U/IND(P)中的元素(也是集合)为P基本集(在不发生混淆的情况下也简称基本集),精确集与粗糙集的概念都是在基本集之上定义的。
定义9-4 我们任意有限多个基本集并称为P可定义集。对于样例E≤U,若E是P可定义集,则称E为P精确集(在不发生混淆的情况下可简称精确集),否则E就是粗糙集。
举例如下:若P={头疼,肌肉疼},则集合{e1,e2,e3,e4,e5}是精确集,而集合{e2,e4,e6}则是粗糙集。
对于精确集,当给定任意属性组合时,都可以判断具备这些属性的元素是属于该集合还是不属于该集合。而粗糙集则做不到这一点。如果想要将一个粗糙集变为精确集,可以有两种方法:第一种是补充一些元素,第二种是去掉一些不确定的元素。比如前面提到的粗糙集{e2,e4,e6},可以将元素e2、e4去掉构成精确集{e6};也可以补充元素e1、e3、e5构成精确集{e1,e2,e3,e4,e5,e6}。使用这两个精确集就可以对粗糙集进行描述。这两个集合都属于粗糙集的近似集。
(3)近似集
一个对象x是否属于集合X,需根据现有的知识来判断,可分为三种情况:x肯定属于X;x肯定不属于X;x可能属于X也可能不属于X。为了能进行精确的数学计算,粗糙集中引入了一些传统集合来对自身进行描述,这些集合包括下近似集、上近似集、正域、负域、边界域等。
定义9-5 对于样例E≤U,E的下近似集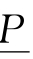 (E)和上近似集P(E)分别定义为:
(E)和上近似集P(E)分别定义为:
![]()
![]()
定义9-6 对于样例E≤U,E的正域POS P(E)、负域NEG P(E)和边界域EN P(E)分别定义为:
POS P(E)=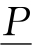 (E)
(E)
NEG P(E)=U-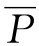 (E)
(E)
![]()
假设将E视为一个概念,则上近似集可以表示这个概念的外延,外延之外的东西肯定不属于该概念。下近似集可以表示这个概念的内涵,内涵之内的东西肯定属于该概念。边界域上的元素则可能属于这个概念,也可能不属于这个概念,由此可以看出,概念之所以具有模糊性是因为边界域的原因[5]。
(4)决策表
只有在实例学习的基础上,粗糙集理论才可以运用到知识获取中。因此粗糙集理论在知识表的基础上引入了决策表的概念。决策表同知识表一样,也包含大量实例记录,但决策表在知识表的基础上还多一条决策属性。知识获取的目的就是对实例库进行分析,确定哪些属性对决策是有贡献的,哪些属性是不重要或者冗余的。比如在表9-1中,可以将“流感”这一条作为决策属性,而其他与症状有关的属性都可以作为条件属性。决策表一般分为一致决策表和不一致决策表。
表9-2 决策表
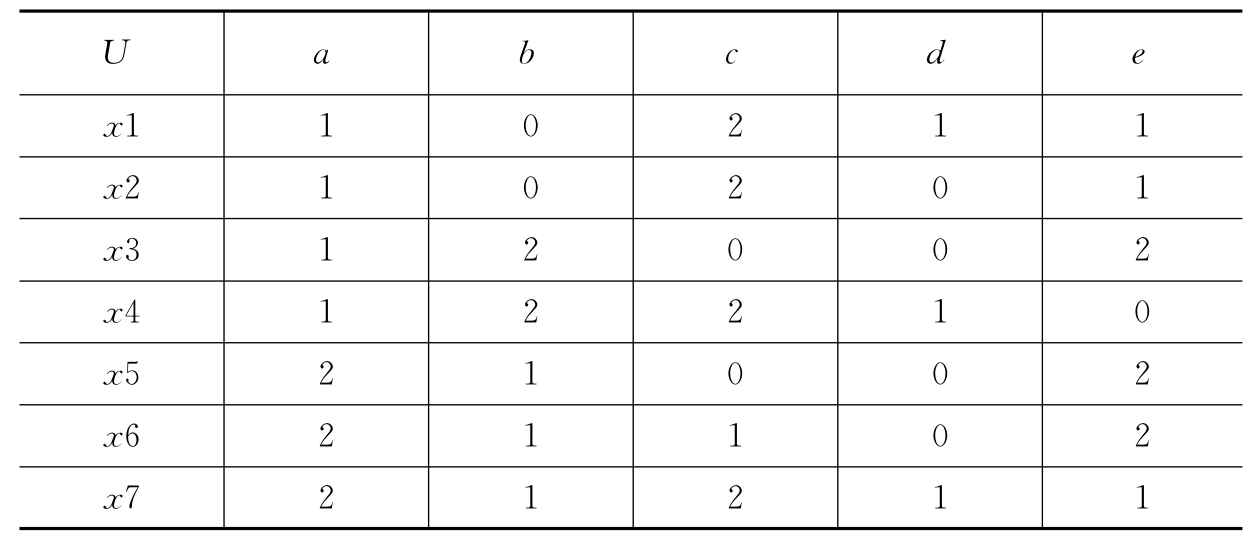
举例如下:设论域U={x1,x2,…,x7},属性集A=C∪D,条件属性集C={a,b,c,d},决策属性集D={e}。
由表9-2可知:
U/C={{x1},{x2},{x3},{x4},{x5},{x6},{x7}}
U/D={{x1,x2,x7},{x3,x5,x6},{x4}
POSC(D)={x1,x2,x3,x4,x5,x6,x7}
可以求得决策集C对于属性D的依赖度:
![]()
即为一致决策表。
在上述中系数k可以作为评估系统参数的重要性。而约简系统参数则要依赖于决策表的约简。前面已经提到不同属性对于决策的重要度是不相同的。此外决策表中还存在冗余现象。也就是在样本集中,只需要少数属性就可以重现整个决策。所谓属性约简是指在保持知识系统决策能力不变的情况下,删除其中的冗余属性。
目前已经涌现出了很多属性约简算法,包括一般约简算法、基于可识别矩阵(Discernibility Matrix)[6]的算法、归纳属性约简算法、MIBARK算法、基于特征选择的算法、基于最佳原理的算法等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











