



第三节 虚拟变量模型与滞后变量模型
当建立计量经济学模型进行经济分析时,我们选取的大量的经济变量都是可以度量的,如国民收入、价格、产量等。然而,当要分析诸如战争、自然灾害或季节等因素对经济的影响时,这些经济变量便无法具体度量了。要在模型中将这些因素的影响反映出来,提高模型的精确度,便需要将这些因素量化,根据它们的属性,进行定性分析。这通常是通过构造只取“0”和“1”的虚拟变量(dummy variables)来完成这种量化,虚拟变量记为D。
一般来说,在虚拟变量设置中,基础类型和肯定类型取值为1,比较类型和否定类型取值为0。同时含有一般解释变量和虚拟解释变量的模型称为虚拟变量模型。
一、虚拟变量的引入和设置原则
(一)虚拟变量的引入
当虚拟变量作为解释变量进入模型时,一般存在两种基本引入方法:加法方式和乘法方式。
1.加法方式
当虚拟变量对被解释变量只存在短期影响时,一般采用加法方式引入。此时,虚拟变量和其他解释变量在模型中是相加的关系。其基本形式如下:
Yi=β0+β1Xi+β2Di+μi(6-1)
采用加法方式引入虚拟变量,可以考察模型截距之间的不同。
2.乘法方式
当虚拟变量对被解释变量存在长期影响时,一般采用乘法方式引入。此时,虚拟变量和其他解释变量在模型中是相乘的关系。其基本形式为:
Yt=β0+β1Xt+β2DtXt+μt(6-2)
采用乘法方式引入虚拟变量,可以衡量模型斜率的变化,或斜率和截距同时发生变化时的情况。
(二)虚拟变量设置原则
在引入虚拟变量时,需要注意,每一定性变量所需的虚拟变量个数要比该定性变量的类别少1,也就是说,如果有M种互斥的属性类型,在模型中应该引入M-1个虚拟变量。
以引入春夏秋冬四个不同季节的虚拟变量为例。此时,M=4,那么就应当引入M-1=3个虚拟变量,此时模型为 (6-3)
(6-3)
其中,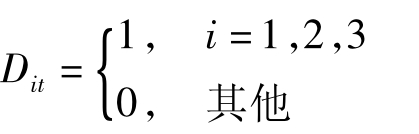
二、EViews下虚拟变量的实例分析
下面,我们将通过一个具体的案例,来分析如何在EViews下引入虚拟变量,从而进行定性分析。
例6-2为了考察东、中、西部经济增长方式,我们选取2001年大多数代表省份的总产出、劳动力和固定资产投入来对其加以分析。我们将样本分为四个研究范围,即(1)东部地区领先组:北京、天津、上海、辽宁;(2)东部地区赶超组:浙江、广东、福建和海南;(3)中西部领先组:山西、内蒙、吉林、黑龙江、湖北、江西、西藏、青海、宁夏、甘肃、新疆;(4)中西部赶超组:安徽、河南、湖南、四川、广西、云南、陕西和贵州。[1]
表6-2给出了2001年上述各省份的生产总值以及劳动力和固定资产投入量。
1.模型的建立与估计
(1)建立不含虚拟变量的模型
首先,我们不考虑增长方式对产出的影响,直接建立产出与劳动力和固定资产投入量间的因果关系计量经济学模型:
lnGDP=α0+α1lnL+α2lnK+μ(6-4)
数据录入完成后,注意用样本数据生成新的对数序列,然后直接用最小二乘法对模型进行估计,分析不考虑增长方式差异下的回归结果。对数变化命令为
genr lg=log(gdp)
genr ll=log(1)
genr lk=log(k)
其中,genr表示构造一新序列,lg,ll,lk表示对新序列的命名,新对数序列如图6-6所示。
表6-2

(数据来源:中国国家统计局.《2002中国统计年鉴》.北京:中国统计出版社,2002.)

图6-6
(2)估计不含虚拟变量的模型
得到变换的数据后,采用最小二乘估计法(OLS)对不含未引入虚拟变量的模型进行估计。同样,可以通过菜单方式和命令方式得到估计结果。
①菜单方式。选择EViews主菜单Quick/Equation Estimation,弹出对话框,如图6-7所示。在图中Equation Specification下的空白处依次输入方程的被解释变量、常数项和解释变量,在此例中,即在空白处输入LG C LL LK,在图下方Estimation settings下的Method下选择LS(Least Squares)估计方法(如图6-8所示),点击确定,就可以得到方程的最小二乘估计结果了(见图6-9)。
②命令方式。同样,通过在命令栏内输入进行最小二乘估计的命令来完成对方程的估计。命令为ls lg c ll lk,可得到与图6-9一致的最小二乘估计结果。
③模型检验。分析图6-9中的各类统计指标,模型的R2为0.976,模型拟合优度较好。F统计量为491,远远大于6%的临界值(2.66)。因此,模型整体显著。再看各系数的T统计量,其中LL与LK的系数通过显著性检验。另外,通过相关系数检验,在数据Group窗口下选择View/Correlations/Common Sample,如图6-10所示,得到相关系数矩阵图6-11。模型解释变量LK和LL之间的相关系数为0.749,一般来说,当模型的解释变量间相关系数不超过0.8时,模型解释变量之间不存在多重共线性,模型设置较优。

图6-7
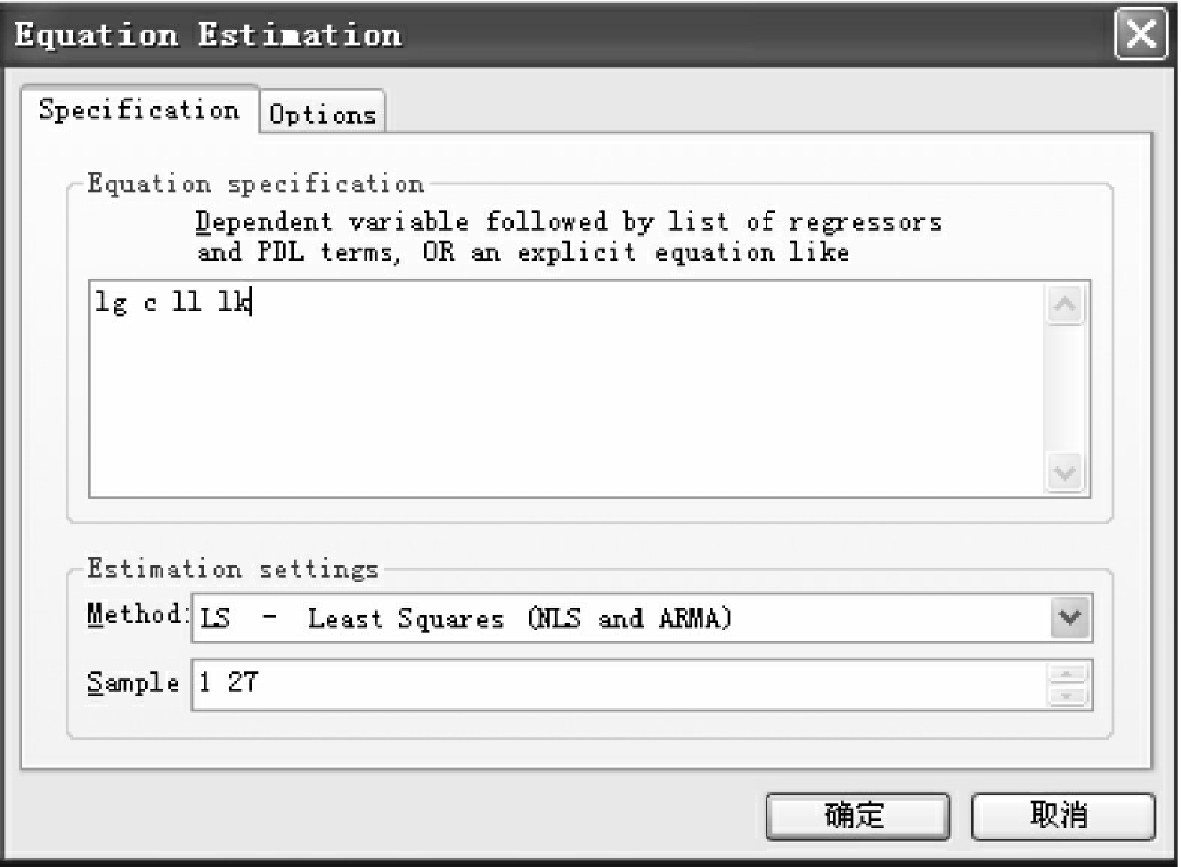
图6-8
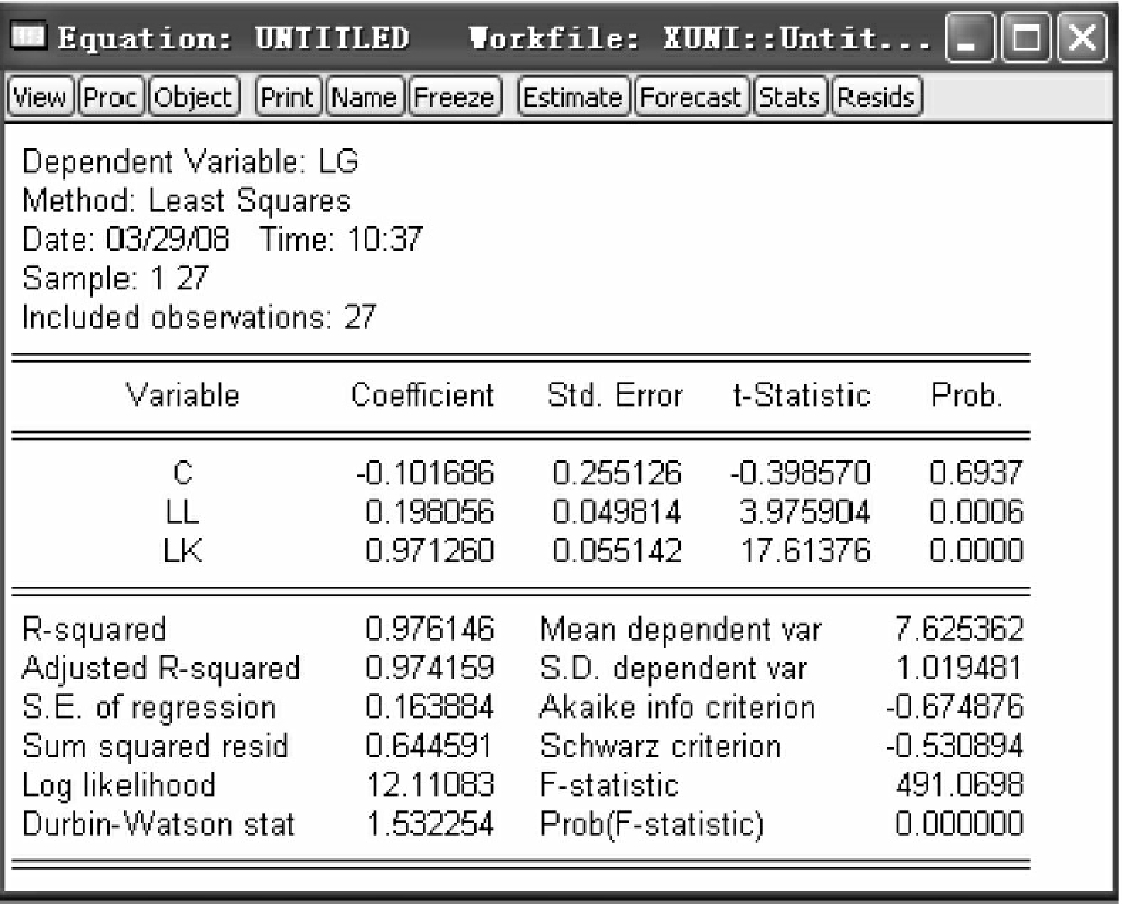
图6-9

图6-10

图6-11
(3)建立引入虚拟变量的模型
为了分析各组经济增长方式是否存在差异,在模型中引入虚拟变量D1,D2,D3,其中D1表示东部领先组,D2表示东部赶超组,D3表示中西部领先组,模型变为
lnGDP=α0+α1lnL+α2lnK+β1D1+β2D2+β3D3+μ(6-5)
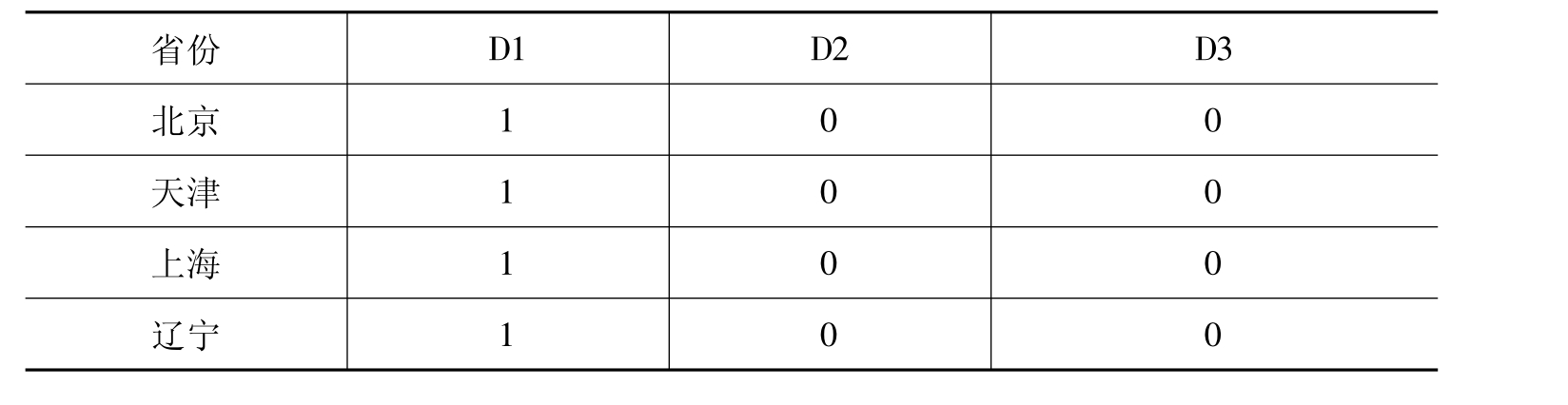
根据虚拟变量取值原则,肯定类型取值为1,否定类型取值为0。在此例中,我们对每一组进行逐个分析。各虚拟变量取值如表6-3所示。
其中,D1的取值表示东部领先组与其他各组增长方式有别,D2的取值表示东部赶超组经济增长方式不同,D3的取值表示西部领先组采取了不同的增长方式。
表6-3
续表

采用上述的命令方式对式(6-5)进行估计。命令为
LSCLGLLLKD1D2D3
得到回归结果如图6-12所示。

图6-12
分析图6-12中的各项统计指标可以看出,引入虚拟变量后的模型的可决系数R2=0.98,高于未引入虚拟变量的模型。因此,虚拟变量的引入提高了模型的拟合优度。其中D1,D2,D3的系数在5%置信水平下均为显著,只有常数项系数非显著,考虑去掉常数项后再进行分析。回归模型为
lnGDP=α1lnL+α2lnK+β1D1+β2D2+β3D3+μ (6-6)
同样,采用命令方式对模型进行回归,命令为
LSLGLLLKD1D2D3
得到最小二乘回归结果如图6-13所示。
从图6-13中可以发现,去掉常数项后,模型的整体拟合优度以及D1,D2,D3的显著性都有所降低。因此,模型(6-6)不能达到分析目的。因此,我们选择保留常数项的回归结果与模型,即认为四个地区的经济增长方式存在差异。
2.结果分析
上述分析结果得出,在引入虚拟变量后,模型的拟合度优于没有引入虚拟变量前的拟合度,而这种经济增长方式的差异存在各组之间。这说明,我国东、中西部经济增长方式存在差异,我国依然走着以资产投入为主的粗放型经济增长道路,特别是在中西部地区,技术在经济增长过程中的作用不大,而在经济发展中,科学技术才是经济发展的最终推动力。与此同时,东部领先地区注重技术的作用,并且领先组对环境的发展也为经济发展作出了不可忽视的贡献。

图6-13
因此,国家和地区在评价经济增长速度与绩效,从而做出相应经济发展决策时,不能忽视各地经济增长方式的差异,对仍然以粗放型经济增长方式为主导的地区要加以引导和规划。
三、滞后变量模型
在实际经济活动中,某些经济变量不仅受到同期各种因素的影响,同时又受到过去某些时期的各种因素甚至是自身的过去值的影响,产生时间滞后效应。一般来说,这种过去的具有滞后作用的变量称为滞后变量(lagged variable),含有滞后变量的模型称为滞后变量模型,当解释变量中含有滞后变量时,模型又称动态模型。
(一)滞后变量模型概述
在模型的解释变量中加入滞后变量,模型就变为了滞后变量模型。其一般形式为
Yt=β0+β1Yt-1+…+βqYt-q+α0Xt+α1Xt-1+…+αsXt-s+μ (6-7)
其中,q,s表示滞后时间间隔,Yt-q为被解释变量Y的第q期滞后,Xt-s为解释变量X的第s期滞后。这种同时包含被解释变量自身滞后变量的回归,又包括解释变量不同时期的滞后变量的模型一般称为自回归分布滞后模型(Autoregressive Distributed Lag model,ADL)。如果滞后变量仅出现在解释变量中,那么模型又称为分布滞后模型(Distributed Lag model)。其一般形式为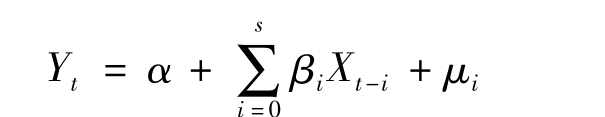 (6-8)
(6-8)
如果滞后变量模型中的解释变量仅包含X的当期值与被解释变量Y的一个或多个滞后值,则称为自回归模型(Autoregressive Model)。一般形式为: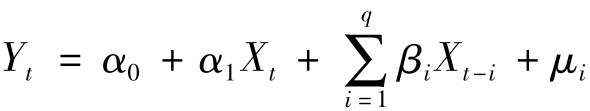 (6-9)
(6-9)
对于分布滞后模型的参数,往往采用经验加权法、阿尔蒙多项式法和科伊克法来加以估计。
(二)分布滞后变量模型实例分析
在实际操作中,常常采用阿尔蒙多项式法和科伊克法对分布滞后变量模型的参数进行估计。下面,我们将通过一实例来说明这两种方法在EViews下是如何运用的。
例6-3研究指出,1975—1995年中国电力基本建设投资X除了现期对发电量Y有影响,其滞后期也影响着发电量Y,通过对滞后期试算后发现这种滞后效应达到第6期。表6-4给出了X与Y的相应数据资料。建立模型如下:
Yt=α0+β0Xt+β1Xt-1+β2Xt-2+β3Xt-3+β4Xt-4+β5Xt-5+β6Xt-6+μt
(6-10)
我们将运用阿尔蒙多项式法对模型参数进行估计。
1.阿尔蒙多项式法(Almon)
Almon多项式法主要是针对有限分布滞后模型,通过阿尔蒙变换,定义新变量,以减少解释变量个数,然后用OLS法估计参数。
在建立工作文件时,通常采用菜单方式建立。同样,可以以命令方式建立一新工作文档。命令为:create y-x a 1975 1995。其中,create表示创建新工作文件(new work file),y-x是对工作文件的命名,后面表示时间范围。然后,通过在命令窗口输入data y x,在弹出的窗口内输入表6-4中的数据。
表6-4 中国电力工业基本建设投资与发电量

(数据来源:中国国家统计局.《1996中国统计年鉴》.北京:中国统计出版社,1996.)
2.阿尔蒙多项式变换
由于模型含6期滞后,因此,可以将模型变换为2阶阿尔蒙多项式,原模型转变为
Yt=α+α0tW0t+α1tW1t+α2tW2t+μt(6-11)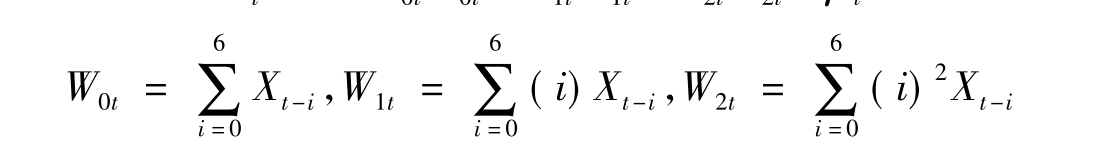
在EViwes中,对原模型进行阿尔蒙多项式变换常常采用命令方式,其命令为
pdl(x,s,k,m)
其中,pdl表示用阿尔蒙多项式分布,x代表滞后变量,s表示滞后期数,k为多项式阶数,m为可供选择项。当m=1时,表示施加近端约束,即限制在分布的末端接近于0,也就是说如果估计出的参数值由小到大,那么施加近端约束;当m=2时,表明施加远端约束,即如果估计出参数值从大到小,则限制在分布的开头接近于0,;当m=3时,表示施加两端约束,此时估计出参数值中间大,两头小,则限制在分布的开头和末端都接近于0;同样,可以省略m,表示不施加端点约束。
(1)未施加约束的估计结果
在此例中,我们令s=6,k=2,并且对模型不施加端点约束。在对模型进行阿尔蒙多项式变换后,用最小二乘法对式(6-11)进行估计,因此,合成两步命令为
ls y c pdl(x,6,2)
得到回归结果如图6-14所示。

图6-14
分析图6-14中回归结果可以看出,2阶阿尔蒙多项式估计显示出较低的t值,即W0t,W1t,W2t前的系数均可能显著为0,模型变量并不显著。此时,模型拟合优度R2=0.9538,而模型整体显著性检验的F统计量为76.68,模型整体上是显著的,但可能存在多重共线性问题。因此,尝试对模型施加约束,从而消除多重共线性,分析回归的参数值。可以看出,中间滞后期的参数估计值大于两端的参数估计值,因此,尝试对模型施加两端点约束。
(2)施加两端点约束的回归结果
对阿尔蒙多项式施加两端点约束,进行回归,命令为:
ls y c pdl(x,6,2,3)
最终结果如图6-15所示。此时,模型参数t值较高,整体显著性检验统计量F=263.31,可决系数R2=0.95295。这些统计量均说明,施加了两端约束的2阶阿尔蒙多项式拟合优度较高,模型整体线性关系显著,单个变量通过显著性检验。至此,我们得到较优的2阶阿尔蒙多项式参数估计值。根据图6-15中的结果,写出2阶阿尔蒙多项式方程为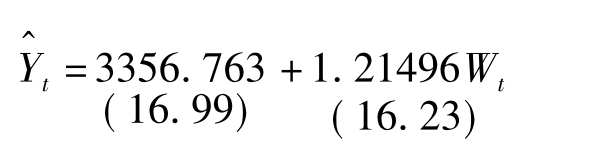 (6-12)
(6-12)
图6-15下方直接给出了由2阶阿尔蒙多项式系数估计值换算出的分布滞后模型的参数估计值。据此,可以写出分布滞后模型的估计式:
从图6-14和图6-15中均可以看出,模型估计的DW值均较小,均在0.3附近,模型存在序列相关性,但是在阿尔蒙多项式法下,暂时没有方法能消除这种序列相关性。
3.结果分析
阿尔蒙多项式分布法一般针对有限分布滞后模型,当遇到无限分布滞后模型时,则往往使用Koyck法,将无限分布滞后模型转换为自回归模型,然后进行估计。它以一个滞后被解释变量替代了大量滞后解释变量,节省自由度。并且由于滞后一期被解释变量与解释变量的线性相关程度低,缓解了多重共线性。
在对含有滞后变量的模型进行参数估计、回归分析时,不能直接采用最小二乘法进行估计。在本例中,如果直接采用最小二乘法进行估计,得到的参数估计结果均是非显著的,并且不符合实际经济意义(见图6-16)。因此,当遇到含滞后变量的模型时,如果滞后分布是有限的,则考虑采用阿尔蒙多项式法;当滞后分布为无限时,则考虑采用科伊克方法进行参数估计。

图6-15
另外,通过此例的回归结果可以看出,一国电力基础设施的建设水平对一国的发电量有着至关重要的影响,并且这种影响持续时间长,过去的基础建设水平对发电量的影响不容忽视。加快整个社会基础设施的建设,其不仅对当代有利,同样会造福后代,符合可持续发展的目标。

图6-16
【注释】
[1]蔡昉:《技术效率、配置效率与劳动力市场扭曲》,原载《经济学动态》,2002年第8期。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










