



第二节 线性回归分析
回归分析(Regression)是一种应用广泛的统计分析方法,它侧重于分析变量之间的变化规律,通过回归方程反映这种关系,并对其发展趋势进行进一步的预测。回归分析研究的是一个或多个变量(自变量)对一个变量(因变量)的影响。根据变量之间的关系,回归分析又可分为线性回归和非线性回归。社会学研究中最常用的是线性回归,如果参与回归分析的自变量只有一个,则称为一元线性回归分析;如果参与回归分析的变量有多个,则称为多元线性回归分析。
一、一元线性回归
一元线性回归,指的是自变量只有一个的线性回归分析,其表达式为: Y'=a+bX,其中a是截距,b是回归直线的斜率。
在进行一元回归分析时有几个方面需要注意:
1.一元线性回归的假设
线性模型的成立需要满足以下条件:
(1)正态性,即总体的各误差项ε满足均值为0,方差为σ2的正态分布。
(2)等方差性,即总体各误差项的方差相同,且为一常数。
(3)独立性,即自变量取任何值,其误差项不相关。
(4)无自相关,即各自变量的误差项之间互不相关。
(5)自变量与误差项不相关,即随机误差项与相应的自变量对因变量的影响相互独立。
2.一元线性回归方程的检验
在根据统计值预测参数值时,需要对统计结果进行假设检验,回归方程的检验涉及:
(1)回归系数的检验。
对回归系数b(B)的检验,原假设是:总体回归系数为0。检验的t值计算公式为: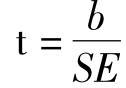 ,SE是回归系数的标准误。
,SE是回归系数的标准误。
对截距a的检验,原假设是:总体回归方程的截距a=0。检验的t值计算公式为: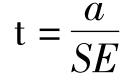 ,SE是斜率的标准误。
,SE是斜率的标准误。
(2)模型的拟合优度。
在判定一个线性模型的拟合优度时,R2(决定系数)是一个重要的指标,指的是X对Y的影响,等于回归平方和在总平方和中所占的比率,一元回归分析中R2=r2。R2越大表示X对Y的解释越强。
(3)方差分析。
因变量观测值与均值之间的差异的偏差平方和(SSt)由回归平方和SSr(反映了自变量的重要程度)和残差平方和SSe(反映了调查误差和其他误差对Y的影响)组成。这两部分除以各自的自由度,就得到它们的均方。F=回归均方/残差均方。当F值较大时,拒绝b=0的假设。
(4)Durbin-Watson假设。
在误差项的诊断分析中,一般采用的是Durbin-Watson诊断,简称Dw或D。D的取值范围是0<D<4,统计意义如下:
①当残差与自变量相互独立时,D≈2;
②当相邻两点的残差为正相关时,D<2;
③当相邻两点的残差为负相关时,D>2。
模型的残差和正态性检验手工计算较为复杂,SPSS软件可以通过残差图形及残差的直方图和累积概率图直观地将其表现出来,不作详细说明。
(5)残差分布图。
在直角坐标系中,以预测值Y'为横轴,以Y与Y'之间的误差或学生化残差为纵轴,绘制残差的散点图,如果散点图呈现出明显的规律性,则认为存在自相关性或非线性或非常数方差的问题。
二、多元线性回归
根据多个自变量的最优组合建立回归方程预测因变量的回归分析,称为多元线性回归分析,回归方程的模型为:Y'=a+b1X1+b2X2+…+biXi,其中a是常数项,b1,b2,…,bi为X1,X2,…,Xi对应的偏回归系数。通过对偏回归系数的标准化,标准回归方程为: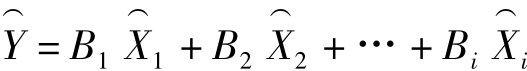
1.多元回归分析中的参数:复相关和决定系数
在研究多个自变量和一个因变量的关系时,其中一个重要的方面是研究多个自变量对因变量共同影响的大小,复相关就是用一个统计值来简化多个自变量与因变量关系的方法,表示因变量Y与自变量Xi之间线性相关密切程度,用R表示,R2称为决定系数,是用来判断模型拟合优度的重要指标。
其中:R2为决定系数,n为样本大小,k为自变量的个数。
2.多元回归分析的检验
首先,多元回归方程的成立也必须满足前述的假设条件。另外,还要对以下方面进行检验来验证模型对总体的解释力:
(1)回归系数的检验。
检验的虚无假设是:各自变量的偏回归系数为0,常数项为0。因为多项回归系数是偏回归系数,所以在进行t检验时,t=偏回归系数/偏回归系数的标准误。
(2)方差分析和方差齐性检验。
方差分析是对整个回归方程进行的显著性检验,它的分析原理与一元回归分析相同。
方差齐性检验是指残差的分布是常数,与预测变量或因变量无关,即残差应该随机的分布在一条穿过0点的水平直线的两侧。在实际应用中,一般绘制预测值与学生化残差的散点图。在线性回归的Plots对话框中,选择SRESID(学生化残差)做Y轴,选择ZPRED(标准化预测值)做X轴,在结果窗口中即可输出方差齐性的散点图。
(3)残差的正态性检验[2]。
对残差的正态性,检验的方法很多,最直观、简单的方法是残差的直方图和累计概率图,应该明确的是,即使存在理想的总体数据,残差也不可能完全服从正态分布,样本的残差也只能是近似于正态分布。
在Plots对话框中,选择Histogram即可得到残差的直方图。
残差的累积概率图,又称P-P图,是用来判断一个变量的分布是否符合一个特定的检验分布的,这些检验分布包括:Beta分布,Chi-square分布,Exponential分布,Gamma分布,Half-normal分布,Laplace分布,Logistic分布,Lognormal分布,Normal分布,Pareto分布,Student分布,Weibull分布,Uniform分布。如果两种分布基本相同,则P-P图中的点应该围绕在一条斜线的周围。如果两种分布完全相同,则P-P图应该只有一条斜线。通过观察比较观测值的残差与假设直线的分布情况对两种分布进行比较。
残差散点图可以判断模型的拟合效果。如果各点呈随机状,并且大部分落在±2α范围内(68%的点落在±α内,96%的点落在±2α之中),则说明模型对数据的拟合效果较好。如果大部分落在±2α范围之外,则说明模型对数据的拟合效果不好。
3.虚拟变量
多元线性回归分析要求变量是定距变量,如果是定类和定序变量,可以用交互分类表来研究一个或多个自变量对一个因变量的共同影响,但其效果不如复相关和回归分析得到的信息多。社会学研究中通常将定序变量看做定距变量[3],而把定类变量变为一组虚拟变量(Dummy Variables)。
任何一个二分变量(Dichotomous Variables),只要将其中一个值给予1分,另一个值给予0分,就成为定距变量,因为1和0之间的距离是一定的(当然,也可以设置为其他的值,如1分和2分,2分和3分,但在分析时都不如1和0方便)。“性别”是定类二分变量,如果设置男性=1,女性=0,则性别就有了1和0两个值,就变成了定距变量。像“性别”这样,本身不是定距变量,通过赋予0和1两个值而变成了定距变量,在统计学上就称之为虚拟变量或虚构变量。定类变量变为虚拟变量之后,便可以采用定距变量的统计方法进行分析。
如果定类变量不是二分变量,在虚拟化时,就要根据变量值成立一组虚构变量,如一次调查的地区涉及华南、华东、华中、华北四个地区,这个变量可以组成四个虚拟变量:
第一个虚拟变量(D1):华南为1,其余为0;
第二个虚拟变量(D2):华东为1,其余为0;
第三个虚拟变量(D3):华中为1,其余为0;
第四个虚拟变量(D4):华北为1,其余为0。
4.线性回归的分析过程
线性回归的内容较多,在分析时,既要求出回归系数、截距,建立回归方程,也要对统计值进行检验,等等。回归分析的过程可简单归纳如下:
(1)确定回归分析中的自变量和因变量。回归分析分析的是一个事物如何随其他事物的变化而变化,所以第一步首先要确定哪个事物是需要被解释的因变量(Y),哪个或哪些是用于解释其他事物的自变量(X)。
(2)确定回归模型。通过散点图确定应该通过哪种模型来概括变量之间的关系。如果自变量和因变量之间存在线性关系,则应进行线性回归分析,建立线性回归模型。反之,则应进行非线性回归分析。
(3)建立回归方程。通过对样本资料的统计分析,估计出方程的参数值,通过假设检验,得到一个确定的回归方程式。
(4)利用回归方程进行预测。通过建立的回归方程,预测事物的发展趋势。
三、线性回归的SPSS应用
SPSS软件中的Regression子菜单提供了多种回归分析的过程,包括Linear:线性回归分析;Curve Estimation:曲线估计;Binary Logistic:Logistic回归分析;Multinomial Logistic:多项对数回归分析;Ordinal:有序回归分析; Probit:概率单位回归分析;Nonlinear:非线性回归分析;Weight Estimation:加权估计分析;2-Stage Least Squares:二阶最小二乘回归分析;Optimal Scaling:最佳缩放比例分析。
SPSS软件中的一元线性回归和多元线性回归分析的功能模块是相同的,都是通过Regression中的Linear过程进行分析的,在此一并介绍。
1.Linear:线性回归的分析过程
打开数据库,线性回归的分析过程如下:
(1)点击Analyze→Regression→Linear,打开如图11-3的对话框。
(2)选择回归分析的因变量和自变量。从左侧源变量框中选择要分析的因变量和自变量,因变量放入Dependent窗口,选择一个或多个自变量放入Independent(s)窗口。SPSS软件提供了对一个因变量的多次分析过程,当自变量放入Independent(s)窗口后,Previous和Next窗口变亮,点击Next命令,可以在Independent(s)窗口输入另一组自变量。
(3)Method:确定自变量进入方法。系统根据自变量对因变量作用的大小,对自变量进行选择的方法。Method窗口提供了五种选择自变量的方式:
①Enter:强行进入法,即所有选择的自变量全部进入回归模型,用户根据自变量回归系数t检验的值是否达到显著性水平决定哪些自变量应该进入模型。这是系统默认的选项。一元回归分析因为只有一个自变量,所以采用此种自变量进入方法。
②Remove:消除法,根据Options设定的条件逐步剔除对因变量影响不显著的变量。
③Backward:向后剔除法,首先让所有的自变量都进入回归方程中,然后逐一来删除它们,删除变量的标准是Options对话框中设定的F值。依次删除和因变量之间的偏相关系数最小的自变量。
④Forward:向前选择法,这种方法与Backward方法正好相反,它逐一让自变量进入回归方程,进入的标准也是Options对话框中设定的F值。依次进入与因变量具有最大相关的自变量。
⑤Stepwise:逐步进入法,是Forward和Backward相结合的方法。根据Options设定的判断,在选择自变量时,首先选择对因变量贡献最大的自变量进入方程,每加入一个自变量进行一次方差分析,如果有自变量使F值最小且t检验达不到显著性水平,则予以剔除。这样重复进行,直到所有符合要求的自变量都进入模型。

图11-3 Linear对话框
(4)Selection Variable:选择变量。
如果选择变量进入Selection Variable窗口,该变量被用做指定分析个案的选择标准,在分析时,对选择的个案进行分析。点击Rule按钮,打开Linear Regression:Set Rule对话框,如图11-4所示。在Value中输入选择个案的取值,统计分析只对这部分个案进行。
(5)在Case Label下面输入变量名,用其值作为观测量标签。
(6)WLS Weighted:变量加权。
单击WLS按钮,选择一个作为权重的变量进入WLS Weight框中,利用加权最小二乘法给观测量不同的权重值,可用来弥补或减少不同测量方法所产生的误差,与利用观测值加权改变有效样本的大小是不同的。已选入的因变量与自变量不能作为加权变量,加权变量的值如果是零、负数或缺失值,相应的观测量将被删除。

图11-4 Set Rule对话框
(7)Statistics:确定输出的统计量。单击Statistics按钮,打开Statistics对话框,见图11-5。此对话框中包括以下几部分:

图11-5 Statistic对话框
①Regression Coefficients:回归系数选项栏,其中:
●Estimates:输出估计值选项。选择此项,则在输出结果中输出回归系数B(回归方程中的b),B的标准误,标准化回归系数beta,B的t检验值以及t值双侧检验的显著性水平Sig.。这是系统默认的选项。
●Confidence intervals:输出回归系数置区间的选项。若选择此项,则在输出结果中输出回归系数95%的置信区间。
●Covariance matrix:输出回归系数的协方差矩阵、各变量的相关系数矩阵。
②模型拟合及拟合效果有关的选项。
●Model fit:输出的是引入模型和从模型中剔除的变量,提供复相关系数R,复相关系数平方R2及其修正值,估计值的标准误,ANOVA方差分析表。这是系统默认选择项。
●Descriptives:输出观测值的个数、均值、标准差、相关系数矩阵和检验的显著性水平矩阵。
●Part and partial correlation:相关系数选项。选择此项后,系统将输出回归方程的部分相关系数、偏相关系数和零阶相关系数。
●Collinearity diagnostics:共线性诊断选项[4]。选择此项后,系统将输出各变量的容许度、方差膨胀因子和共线性诊断表。
在回归分析方程中,参与统计的自变量较多,有些自变量彼此相关,变量之间的相关,可能减弱单个自变量对因变量的影响,从而不能正确地估计自变量和因变量的关系,我们称这种现象为共线性,也称统计累赘。因此,在进行多元线性回归时,需要对变量进行共线性诊断,常用的参数有:容许度、方差膨胀因子、条件参数等。当一组自变量存在共线性时,必须剔除一个或多个自变量,剔除的变量并不包含任何多余的信息,因此得出的回归方程并没有损失什么。为了避免统计累赘,虚拟变量在引进方程时,需要舍弃其中一个变量。
Ⅰ.容许度(Tolerance)
Ⅱ.方差膨胀因子(VIF)
方差膨胀因子是容许度的倒数,即: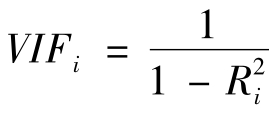
它的值越大,自变量之间存在共线性的可能性越大。
Ⅲ.条件参数(Condition Index)
条件参数是在计算特征值时提出的一个统计量,它的表达式为: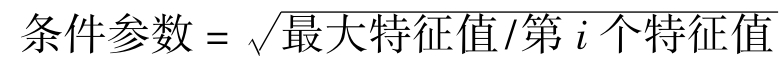
条件参数的数值越大,说明自变量之间存在共线性可能性越大,虽然理论上还没有得到证明,有学者提出,当条件参数≥30时,认为有共线性存在的可能性。特征值(Eigenvalue)如果很小,则共线性存在的可能性很大。
③Residuals:残差分析。该栏包括两项内容:
●Durbin-Watson:序列相关检验选项,选择该项后系统将在模型概要中输出Durbin-Watson的值。
●Casewise diagnostics:输出观测量诊断表。
Outliers outside standard deviation是设置奇异值选项,若默认为≥3倍标准差,则被看做是奇异值,用户可自己修改。
All cases:输出所有观测量的残差值。
上述选项做完以后,单击Continue按钮,返回回归分析主对话框。
(8)Plots:绘制图形。单击Plots按钮,打开图形选择对话框,见图11-6。

图11-6 Plots对话框
系统默认是不输出图形。绘制图形对检验残差的正态性,等方差性,奇异值等是非常有帮助的。作图过程为:
①选择坐标轴变量。
从左侧的源变量窗口中选择两个变量分别进入右侧的X窗口和Y窗口。如果要输出多个散点图,可单击Next按钮,在Y和X窗口中再输入另外两个变量。
●DEPENDNT:因变量。
●ZPRED:标准化预测值。
●ZRESID:标准化残差。
●DRESID:剔除残差。
●ADJPRED:调整的预测值。
●SRESID:学生化残差。
●SDRESID:学生化剔除残差。
②Standardized Residual Plots:确定标准化残差的图形类别,包括两种图形:
●Histogram:输出带有正态曲线的标准化残差的直方图。
●Normal probability plot:输出残差的正态概率图,检查残差的正态性。
上述选项完成以后,单击Continue按钮,返回主对话框。
(9)Save:保存结果。单击Save按钮,打开如图11-7的对话框保存变量。系统将把被选择的分析结果作为新变量保存到数据窗口中。

图11-7 Save对话框
①Predicted Values:预测值。
●Unstandardized:非标准化预测值。
●Standardized:标准化预测值。
●Adjusted:调节预测值。
●S.E.of mean predictions:预测值的标注误差。
②Residuals:残差。
●Unstandardized:非标准化残差。
●Standardized:标准化残差。
●Studentized:学生化残差。
●Deleted:剔除残差。
●Studentized deleted:学生化剔除残差。
③Distances:距离。
●Mahalanobis:Mahalanobis距离。
●Cook's:Cook距离。
●Leverage values:中心点杠杆值。
④Prediction Intervals:预测区间栏。
●Mean:预测区间高低限的均值。
●Individual:观测量上限与下限的预测间距。
选择上述两项后,在Confidence Interval参数框中确定置信度,默认值为95%,输入的值必须在0~100之间。
⑤Influence Statistics:影响点的统计量。
●DfBeta(s):因排除一个特定的观测值所引起的回归系数的变化,一般情况下,此值大于2,则被排除的观测值可能是影响点。
●Standardized DfBeta(s):标准化的DfBeta(s)值。
●DfFit:因排除一个特定的观测值引起的预测值的变化。
●Standardized DfFit:标准化的DfFit值。
●Covariance ratio:协方差比矩阵,剔除了一个影响点的协方差矩阵与全部观测量的协方差矩阵比。
⑥Save to New File:将回归系数结果作为一个文件,保存到指定的文件夹。
⑦Export model information to XML file:将模型信息输出到一个新的XML文件。
⑧Include the covariance matrix:保存的结果包括协方差矩阵。这是系统默认值。
(10)Options:其他选项。单击Options按钮,打开选项对话框,见图11-8。
其中涉及的命令主要包括:
①Stepping Method Criteria:设置变量引入模型或从模型中剔除的判断标准栏。

图11-8 Options对话框
●Use probability of F:以F的概率作为变量引入模型或从模型中剔除的判断标准。系统默认状态是当一个变量的F值的显著性水平Sig.≤0.05时,该变量被引入回归方程。当一个变量的F值的显著性水平Sig.≥0.1时,该变量被从模型中剔除。
●Use F values:以F值作为变量引入模型或从模型中剔除的判断标准。系统默认状态是,当一个变量的F值≥3.84,该变量被引入回归方程。当一个变量的F值≤2.71时,该变量被从模型中剔除。用户也可以通过选择Use F values选项,根据需要自己设定这两个数值。
②Include constant in equation:在方程中包含常数项的选项。这是系统默认选项。
③Missing Values:缺失值的处理方法,包括三种方式:
●Exclude cases listwise:剔除参与回归分析的任何变量中的缺失值。
●Exclude cases pairwise:成对删除缺失值。
●Replace with mean:用平均值代替缺失值。
上述选项做完以后,单击Continue按钮,返回回归分析主对话框。
(11)输出结果。单击OK按钮,提交运行。在输出结果窗口中输出分析结果。
2.实例分析
例2 根据data10.3数据,以“工资”为因变量,以“教育年数”为自变量进行一元回归分析。
打开数据文件后,执行以下操作:
(1)点击Analyze→Regression→Linear,打开对话框。
(2)从源变量框中选择“现在工资(a4)”作为因变量放入Dependent窗口,“教育年数(a2)”作为自变量放入Independent(s)窗口。
(3)打开Statistics窗口,选择Durbin-Watson选项,点击Continue按钮。
(4)点击Plots按钮,打开对话框,从左侧的源变量窗口中选择SRESID(标准预测值)放入X窗口,选择ZRESID(标准化残差)进入Y窗口。选择Histogram选项。单击Continue按钮,回到分析对话框。
(5)单击OK按钮,提交运行。可以在输出结果窗口中看到表11-4至表11-11和图11-9、图11-10的结果。
表11-4 进入或剔除的变量

表11-4表示的是采用Enter法,“教育年数”变量进入模型。这个结果对一元回归分析没有意义,但对多元回归分析的意义较大。
表11-5 模型概要

表11-5是对模型基本情况的说明,结果显示,两个变量的相关系数R为0.658,模型的决定系数R2为0.434,说明用教育年数解释工资时可以削减43.4%的误差,模型的拟合优度较好。标准误差为1259.71。Durbin-Watson的值是0.763。
表11-6 方差分析表
ANOVAb
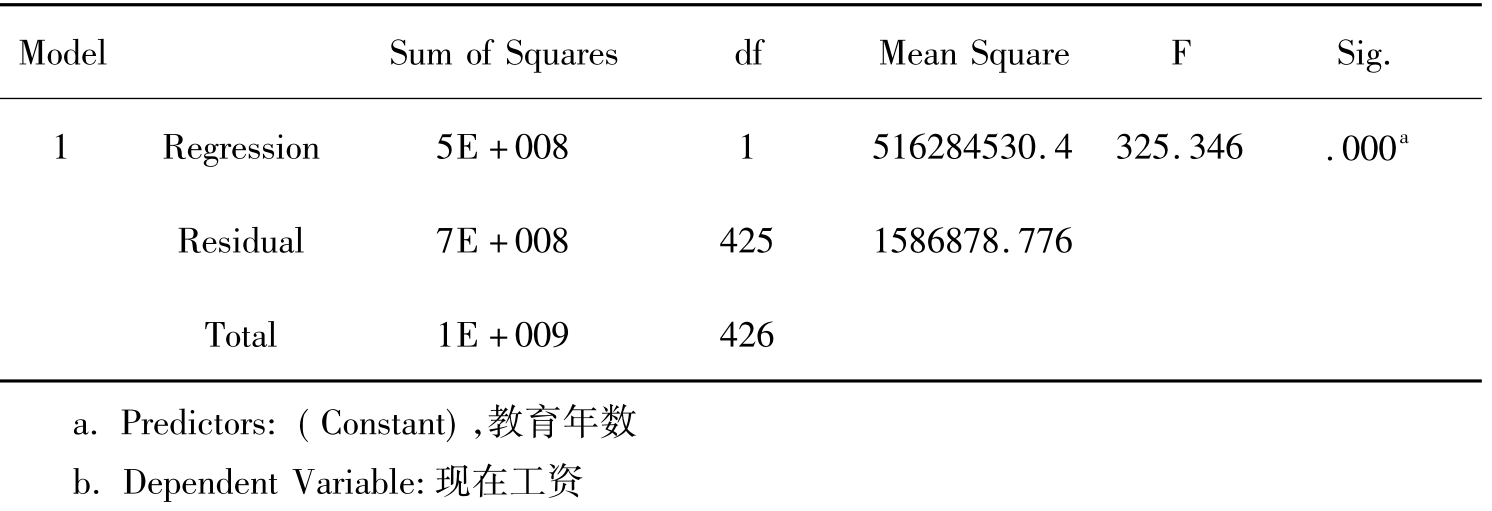
ANOVA是对模型的方差分析和F检验的结果,表11-6中分别列出了回归平方和、残差平方和和总平方和,以及自由度、F检验的结果和显著性水平。方差分析结果表明,当回归方程包含不同自变量时,其显著性水平值为0.000,拒绝回归系数为0的假设。
表11-7 回归系数

表11-7是回归方程的参数及检验结果。从结果来看,回归方程的常数项即截距a为-1772.2,标准误为293.47,t检验的值为-6.039,显著性水平Sig.为0.000。回归方程的斜率及回归系数b为385.458,标准误为21.37,标准回归系数B为0.658,t检验的值为18.037,显著性水平Sig.为0.000。可以看出,在0.001的显著性水平上,常数和回归系数对总体都是有意义的。根据回归系数,我们可以写出回归方程:工资=-1772.2+385.458×教育年数。标准回归方程:现在工资=0.658×受教育年数。
表11-8 残差分析表

表11-8中的Predicted Value是预测值,Residual是残差,Std.Predicted Value是标准化预测值,Std.Residual是标准化残差。从表11-8中可以看出,残差的均值为0,标准化残差的均值也是0,说明残差的分布满足均值为0的假设。

图11-9 残差的直方图
从图11-9中可以看出,残差的分布接近正态分布。
图11-10是以学生化残差为横轴,标准化预测值为纵轴的残差分布图。从结果可以看出,虽然样本存在奇异值,模型的数值绝大多数都落在±2α范围内,较好地满足了残差等方差性的要求。

图11-10 残差散点图
例3 根据data11.2数据,以“工资”为因变量,以“性别”、“教育年数”、“城乡来源”为自变量进行多元回归分析。
分析说明:在此分析中,工资和教育年数为定距变量,而性别和城乡来源为定类变量,首先对定类变量作虚拟变量分析,“性别”变量中0=男,1=女;“城乡来源”变量中0=城市,1=农村。
打开数据文件后,执行以下操作:
(1)点击Analyze→Regression→Linear,打开对话框。
(2)选择“工资”作为因变量放入Dependent窗口,“性别”、“教育年数”、“城乡来源”作为自变量放入Independent(s)窗口。
(3)在Method窗口选择Stepwise。
(4)打开Statistics窗口,选择R Squared Change,Durbin-Watson选项,选择Collinearity diagnostics,其他默认,点击Continue按钮。
(5)点击Plots按钮,打开对话框,从左侧的源变量窗口中选择ZPRED(标准预测值)放入X窗口,选择ZRESID(标准化残差)进入Y窗口。选择Histogram选项。单击Continue按钮,回到分析对话框。
(6)单击OK按钮,提交运行。可以在结果输出窗口中看到分析的结果。这里主要介绍与例1不同的图形和结果。
表11-9 进入/剔除变量窗口

从表11-9的结果可以看出,通过Stepwise逐步回归方法,进入分析的三个变量共建立了三个模型,第一个模型包括“教育年数”变量;第二个模型包括“教育年数”“性别”两个变量;第三个模型包括“教育年数”、“性别”和“城乡来源”三个变量。进入模型的标准是F值的概率≤0.05,剔除变量的标准是F值的概率≥0.1。
表11-10模型概要

表11-10分别说明了三个模型的解释力。第一个模型的调整R2为0.434,第二个模型的调整R2为0.485,第三个模型的R2为0.504。Change Statistics表示出的是每增加一个变量R Square的变化情况,可以看出“教育年数”对工资的影响最大,“性别”和“城乡来源”变量对R Square的变化的影响不大,分别只增加了0.53和0.20。
表11-11 方差分析表

从结果可以看出,每一个模型都达到了0.000的显著性水平,回归模型具有意义。
表11-12分别给出了三个模型的截距(Constant)、回归系数、标准误、标准回归系数、检验值、t检验的显著性水平值,以及共线性诊断中的容许度和方差膨胀因子。从各变量的t检验可以看出,三个变量对因变量的影响都是显著的,从模型三的标准回归系数可以看出,教育年数对工资的影响最大,其次是性别。共线性诊断的容许度不是很小,方差膨胀因子不大,可以认为它们之间不存在共线性。根据回归系数可以得到回归模型。以模型三为例,回归方程是:工资=-334.076+318.616×教育年数-886.508×性别-580.482×城乡;标准回归方程为:工资=0.544×教育年数-0.265×性别-0.145×城乡来源。
表11-12 回归系数

表11-13 剔除的变量

表11-13列出的是每一次模型迭代中剔除的变量。
表11-14 共线性诊断

除了在Coefficients数据表中列出变量的共线性检验的容许度和方差膨胀因子外,共线性诊断表还列出变量共线性诊断的维数(Dimension)、特征值(Eigenvalue)、条件参数(Condition Index)和各变量的方差比例(Variance Proportions)。从特征值和条件参数可以看出,各模型的特征值不算太低,条件参数值不高,因此也可以断定变量存在共线性的可能性比较小。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










