



6.2.1 特征选择与词间语义相似度量度
未知词汇的含义常常能从它的上下文推导得出。语义相似的概念和术语常常出现在相同的上下文中,由此可以推断,如果以与某词汇经常同现的词作为其特征词汇,那么特征词汇重叠度越大,词汇之间的语义相似度就越高。以此为依据,根据同现分析的计算结果,用与词T最相关的前K个词汇代表其特征,构成词T的特征向量T(<T1,W1>,<T2,W2>,…<TN,WN>),其中,Ti表示相关词汇,Wi表示相关词汇Ti与T的关联度值。如果把与词汇T相关的词汇看作对其词义的描述和定义,那么相同的描述词个数越多,词汇在语义上就越相似。但如果把所有与词T相关的词汇均罗列在向量中,这种“贪婪”的做法导致计算量过大;另外,一些与词汇T相关度很小的词汇对词T的语义描述能力很弱,甚至两词实际上完全不相关。根据对关联结果的分析经验,本文提取每个词前50个关联度最高的词汇和相应关联度构成该词的特征向量来降低向量维度,起到缩小计算窗口的作用,这样做不仅提高相似度计算精度,同时避免了不必要的计算,提高词聚类速度。
当词汇被表示为与其同现的词汇空间的向量时,两个词Ti 与Tj之间的语义相似度Sim(Ti,Tj)就可以借助于向量之间的某种相似性函数或距离来度量。本文采用了向量空间模型中常用的余弦相似度算法来计算两词汇之间的语义相似度。词汇向量之间的夹角越小,它们的语义相似性就越大。
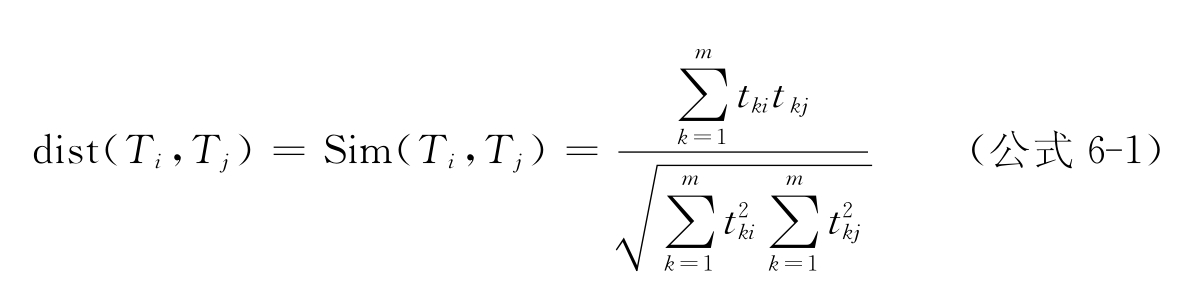
例如,两词汇“直接税”和“间接税”的特征向量如表6-2所示:
表6-2 特征向量示例

(续表)

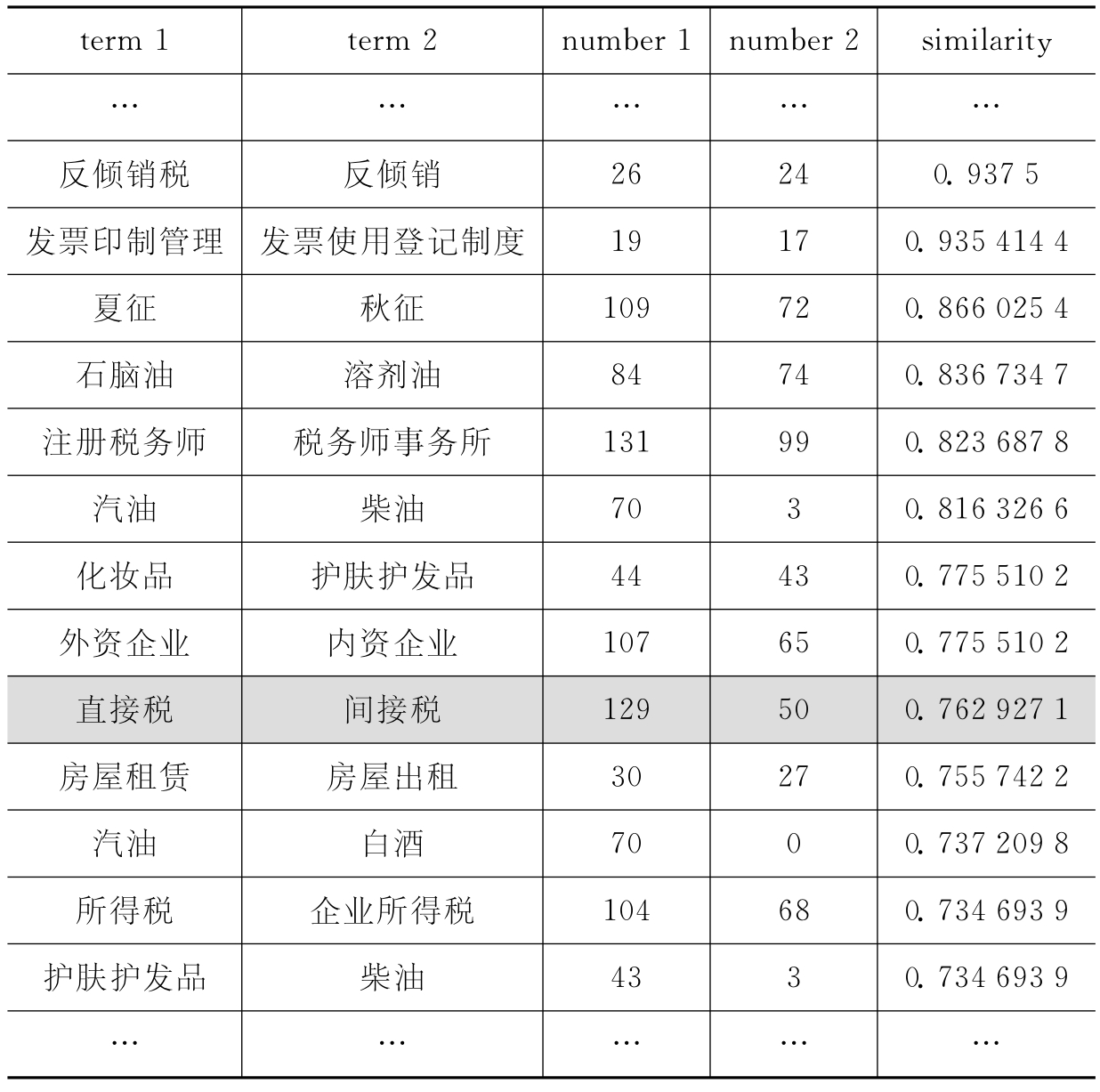
经余弦相似度计算,“直接税”和“间接税”的语义相似度为0.762 927 1。计算内核部分词汇两两之间的相似度,并存储在相似度矩阵表中,待进一步聚类。如表6-3所示,其中字段term 1和 term 2是待聚类词汇对象,字段number 1和number 2分别是term 1和term 2在矩阵中的位置序号,字段similarity为term 1 和term 2的相似度值。
表6-3 相似度矩阵表
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









