



6.1.3 聚类算法[10]
聚类,即给定一数据样本集X{X1,X2,…,Xn},根据各个样本之间的相似度将数据集合分成k个簇:{C1,C2,…,Ck},使得相似样本在同一簇中,相异样本在不同簇中,其中Ci={Xi},Ci∪Cj=ф,i≠j。关于同一簇中的样本比来自不同簇的样本更相似的判断问题主要涉及以下两个方面:①怎样度量样本之间的相似性;②怎样衡量对样本集的某种划分的好坏。相似度通常用描述对象的属性值来计算。
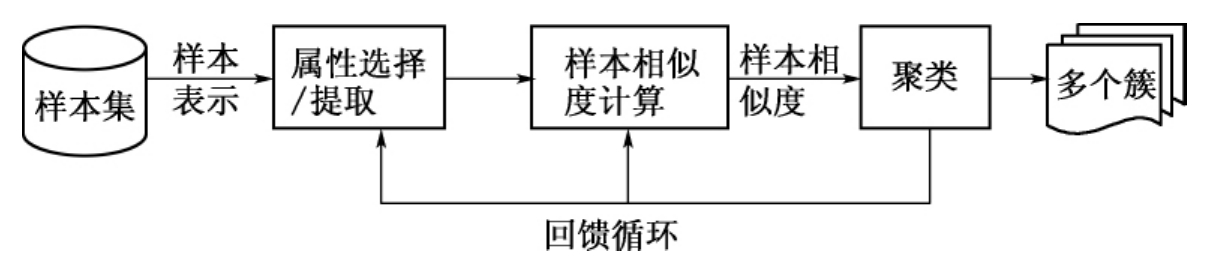
图6-1 聚类过程描述
聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题,被广泛用于市场或客户识别、模式匹配、生物学研究、空间数据分析、Web文档分类等研究领域。主要有划分方法(如K-mean算法)、等级聚类方法(如全连通、单连通、平均连通)、基于密度的方法(如DBSCAN算法)、基于网格的方法(如STING)、基于模型的方法(如COBWEB和神经网络算法SOMs)。其中等级聚类算法实现简单,适合详细的数据分析过程,能提供更多的数据信息,灵活性高,聚类过程可视化,准确度较高,是最常用的一种聚类分析方法。根据聚类过程中簇之间距离的计算方法不同分为单连通、全连通和平均连通三种算法,见表6-1。
表6-1 聚类算法的簇间相似度计算方法

单连通算法中簇之间距离定义为两个簇中最相似样本之间的相似度,聚类结果具有良好的局部一致性,但易产生“狭长区域”。
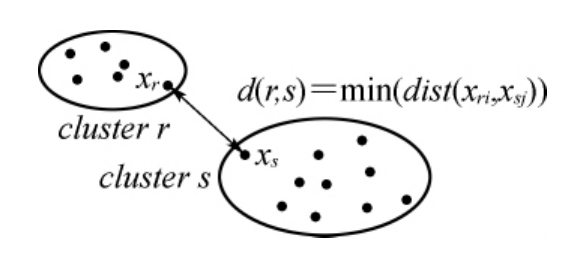
图6-2 单连通聚类相似度计算方法
全连通聚类算法考虑到全局因素,簇之间的距离定义为两个簇中最不相似样本的相似度,因此改善了单连通聚类算法的缺陷,但是效率较低(计算复杂度为n 3)。
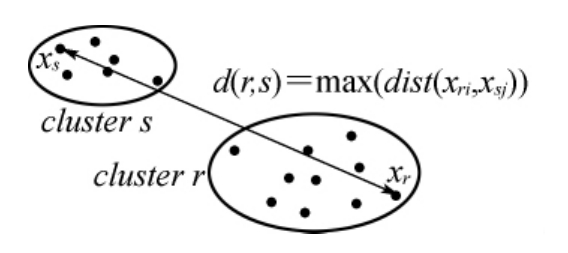
图6-3 全连通聚类相似度计算方法
平均连通算法是前两者的折中,以两个簇中的所有样本对的相似度平均值作为这两个簇的距离,它可以用来替代全连通聚类算法,不仅避免了单连通聚类算法的缺陷,而且其计算复杂度(n 2)小于全连通算法。
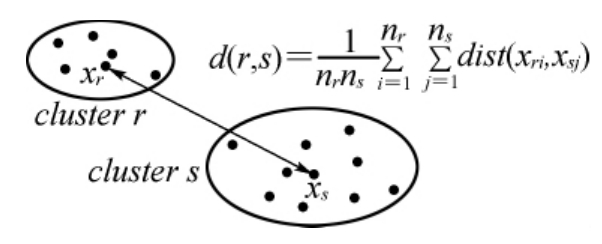
图6-4 平均连通聚类相似度计算方法
对于各等级聚类算法的性能,有学者指出,虽然每种聚类算法各有其优缺点,但不存在最优的聚类算法,现有算法只能证明它对某个应用是最优的。所以,在实际操作中才能确定哪种算法才是最合适的[11]。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。








