



10.1 层次分类原理
如本书第2章所述,多层分类是指多层类别关系下的分类问题。多层分类中,类别关系的复杂和相互干扰以及不同类别层次间分类错误的传播都可能对分类器的准确性评估造成影响[1—2]。文献[3]~[5]文对中文文本的多层次文本分类进行了探索。本章以向量空间模型为基础,进行文本分类算法的实验。
采用向量距离法进行分类,对于某个对象,分类器在进行类别匹配时,都要计算出一个数值来指示该对象属于该类别的相似程度。文本分类系统,用文档和类别所表示成的空间向量之间的相似度,来表示两者之间的相似程度。若相似度大于对应阈值,则分类成功。在进行特征提取时,一般的做法是,将所有文本类别都视为同一层次,提取出各类在同一层次条件下的特征向量,分类时,再计算待分类文档与各类中心向量的相似度,若满足阈值条件,则将其划分到相应的文档类。
采用以上方法,当文档类较少,并且文档类之间的区分度较大,亦即主题类别差异很大时,这种匹配策略能够较为有效地进行文档类的划分。但当文档类的数目较多,且存在两个类特征向量特别相近,其对应的文献又属于不同类别时,系统区分它们的能力严重依赖于训练文献集,而且能够起区分作用的一般是为数较少的一些特征项。在这种情况下,如果我们考虑类别体系的层次结构,则对应的文献又往往分别属于某一主题类的两个子类。此外,如果不考虑类别体系的层次结构,则对于存在相邻层次关系的类别,分类精度很难保证,并且在分类时需要进行所有文档类的匹配计算,运算量明显增大。
对此,我们在实验中也得到了验证。
其中,“工业”类和“化工”类等之间的区分度不明确,且分别归属于两个上层类目(分别是“重工业”和“石油化学工业”),所以导致它们之间的错分情况较为普遍,分类准确率也较低。
通过对分类系统的分析可知,一般的主题分类体系都有分层次的树状特征,这在以主题作为分类体系的一些商业网站中相当普遍,如Yahoo、Sohu等。归类文本也相应地可以根据分类体系划分为树状的多个层次(对于ChinaInfobank语料类,按照本书所采用的分类体系,具体分为2层),由内容相近的类组合成一个大类,内容相似的大类再组成更上一层的大类,如图10-1所示。
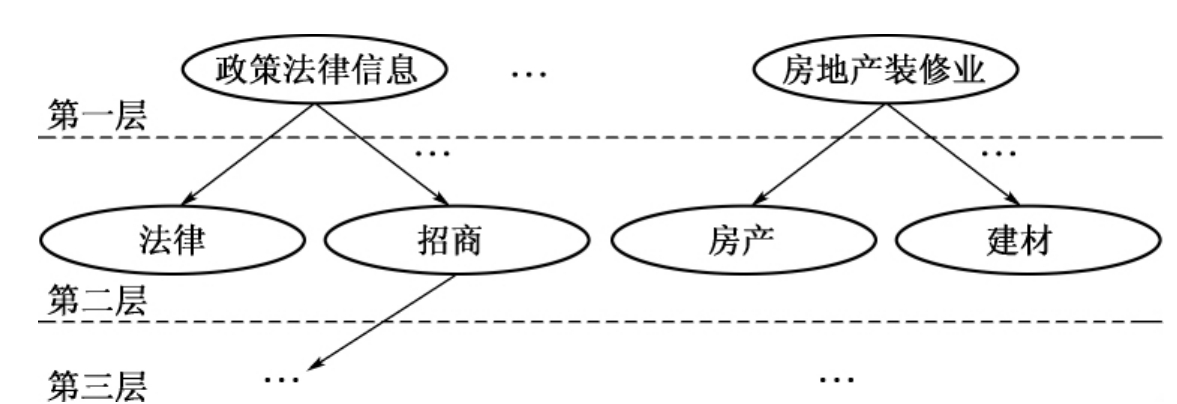
图10-1 类别体系的层次结构示意图
对于《中图法》分类体系,这一层次特征更为明显,不再赘述。
根据这种层次结构,我们考虑可以采用自顶向下地逐层分类的方法。从理论上来说可以提高分类精度,降低计算量。分析如下:
有些特征项在单层次的分类中对分类的重要度不高,但在多层次分类中却很重要。如“住宅”这个特征项,在单层次分类时,有关房产的一些类别都是和“住宅”有关的,其对分类作用不大。但在多层次分类中的第一层分类中,它对区分“政策法律信息”类别和“房地产装修业”类别却起到了很重要的作用。
在第一层上,一般来说主题类别差异都比较大,而且类别数目量比较小,如此,区分一篇文章属于哪一类,相对来说会较为容易一些。而在此后的进一步细分过程中,分类路径是沿第一层的某个结点的各个子结点逐层向下的。每进行一次细分,都是在很小的类别范围内进行,因此,分类精度也较有保证。
另外,由于文献的特征向量,并不是与所有的类别平面特征向量进行比较,而仅是与部分类别特征向量进行比较,在较高层次上进行比对时,减少了比较次数和计算量,相应地降低了单层时间复杂度,但总体花费有所增加。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











