



【摘要】:6.3.1 关联规则挖掘概述数据挖掘又称数据库的知识发现,定义为从数据库中获取有用的、事前未知和最终能为人们所理解的知识的过程。关联规则挖掘发现大量数据中项集之间有趣的关联和相关联系。随着大量数据被不停地收集和储存,许多业界人士对于他们的数据库中的挖掘关联规则越来越感兴趣[8]。关联规则的模型定义如下:设I={i1,i2,…规则的支持度和置信度是两个规则兴趣度度量,强规则认为是有趣的。
关联规则挖掘概述_文本自动标引与自动分类研究
6.3.1 关联规则挖掘概述
数据挖掘(KDD)又称数据库的知识发现,定义为从数据库中获取有用的、事前未知和最终能为人们所理解的知识的过程。也就是在大规模数据库中高效地发现潜在可用的模式或指导性的规则。获取的知识是一组规则的集合,这些规则是对数据库中数据属性、模式产生频率、对象簇集的描述,获取的知识可以用来在数据库记录间识别联系,为被挖掘的数据库产生摘要,形成预报和分类模型,最终提供给决策支持系统[7]。
关联规则挖掘发现大量数据中项集之间有趣的关联和相关联系。随着大量数据被不停地收集和储存,许多业界人士对于他们的数据库中的挖掘关联规则越来越感兴趣[8]。
关联规则的模型定义如下:
设I={i1,i2,…,im}是m个不同项目交易的集合。对于一个给定的交易数据库D,其中的每个交易T是I中的一组项集,即T包含I。每一个交易都与一个唯一的标识TID相对应,如果I中的每一个子集X,存在X包含T,就表示一个交易包含了X。关联规则蕴涵式形如X=>Y形式,X和Y是项集,X包含I,Y包含I,且X∩Y=Ø。若用P(X)表示交易X发生的概率,关联规则X=>Y的支持度因素和信任度(置信度)因素就可以定义如下:
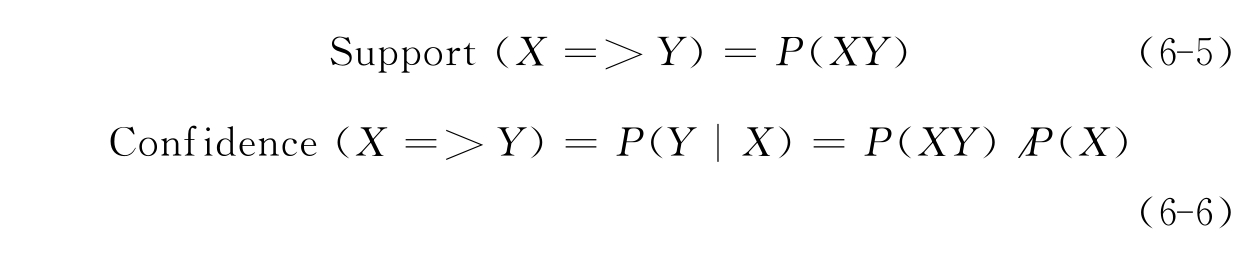
同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称作强规则。规则的支持度和置信度是两个规则兴趣度度量,强规则认为是有趣的。这个阈值可以由用户或领域专家设定。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










