



5.2 领域词表的构建
5.2.1 领域词表的界定和构建目的
主题词表根据其涉及范围的不同,有通用词表和专业词表之分。而领域词表是在一个学科领域内使用,表示该学科领域内概念、特征或关系的词语的集合。一个领域内的词汇亦即术语,集中体现和负载了一个学科领域的核心知识,词汇的变化在一定程度上反映了一个学科领域的发展变化。因此,利用领域词表,使用者可以浏览和探索某一学科领域知识结构的全貌与细节,是了解一个学科知识相当重要的参考资源[3]。
术语是一个领域的核心词,但在一个学科领域内除了核心词还应该包括一般词汇。农业史本身就是一个多学科交融的领域,涉及农业、历史、经济、社会文化多个学科领域,因此农史领域词表是通用词典和专业词表的结合,除了包括农史术语外,还会包括一些农业、历史、经济、社会文化领域的词汇。
本研究中农史领域词表的构建目的是:①作为抽词词典,用于农史信息资源自动标引和自动分类;②作为智能信息检索的入口词表,即后控词表。出于这两个目的,这部农史领域词表应该是一种自然语言叙词表,它“可以容纳同义词、近义词、等级上和语义上相关的词”[4]。这种适用于网络环境的自然语言词表,不同于传统的等级和体系严格规范的叙词表,而是着重于控制同义词,准同义词或非正规词与正规词之间的对应等。因为在网络环境中,通过上下位关系来扩大检索范围,可以借助于分类体系,而不必依赖于领域词表。因此,农史领域词表编制的指导思想是:尽可能收录农史领域中的核心词汇,词汇之间关系的控制主要是等同关系和相关关系,而上下位的这种等级关系的控制则交由农史专业分类表来完成。
5.2.2 领域词表构建方案
词表的构建方法有人工构建和计算机自动构建。采用人工方式构建,准确率高,但成本高、速度慢,新的词汇不能被及时收录;采用计算机自动构建,收词范围广、成本低、速度快,但准确性差,术语之间的关系不能被完整揭示。因此,更多的情况是两者相辅相成,以自动构建为主,人工审核为辅。本词表的构建亦采用此方案进行,具体构建步骤如下:
(1)界定学科领域,根据学科范围确定概念收录范围
主要从两个来源进行收词:一是现有的词表、词典、索引、百科全书;一是该领域文献集合。针对农史领域,其词表的构建也主要从这两个方面收词。
①从现有的工具书中收取农史术语概念
《中国农史辞典》,夏亨廉、肖克之主编,中国商业出版社于1994年12月出版,是一部农史词解工具书,是国内外最早的一部农史词典。该辞典收词范围以农业科技史为主,涉及农业史的诸多方面,包括农业史通论、农业思想史、农业人物与农书、土地制度、赋役制度、人口户籍、漕运、粮食仓储、自然灾害与荒政、土壤改良、土地利用、肥料、农具、农田水利、农艺、农作物、园艺、林业、畜牧业、蚕业、渔业、茶文化、饮食文化等内容。所收词条时间自远古至20世纪90年代,尊奉详古略今、宁缺毋滥的原则,1840年后非重大者不收入。共收词2 478条,按照汉字笔画编排[5]。
《经济大辞典(农业经济卷)》,陈道主编,北京农业大学等编,上海辞书出版社、农业出版社1983年出版,收集了农业经济学科常用术语2 373条,包括土地改革、农业社会主义改造、土地、劳动、种植业、林业、渔业、畜牧业、工副业、中国农业经济史、经济思想史等19个农业经济领域的词汇[6]。从中选取出农史领域的词汇共369个。
《中国农业百科全书(农业历史卷)》,中国农业百科全书编辑部农业历史卷编辑委员会编制,中国农业出版社1995年12月出版,是荟萃古今中外农业历史知识的一部大型工具书。包括中国农业历史、中国农业发展史、中国农业经济史、中国农业科学技术史、世界农业史等内容。共有条目661条,主题771个,按音序编排,并提供学科分类目录、汉字笔画索引、条目外文索引、内容索引等[7]。
《中国科学技术史(农学卷)》的书后索引,董恺忱、范楚玉主编,科学出版社2000年6月出版。该书对中国传统农学的发展过程与历史成就加以记述和总结。依照中国农业历史发展的内在规律所呈现的阶段性,全书分为先秦、秦汉魏晋南北朝、隋唐宋元及明清四篇,在分别简述其时代特征背景的前提下,侧重从历史文献、技术体系与指导思想等三个方面从事农史探索分析[8]。书后索引是一种古老的索引类型,它把图书中的各种资料单元作为标目,按字序法排序,注明它在书中的页次(版面区或行次),以供读者快速检索书中的内容,通常置于每书之后[9]。书后索引有很多种类型,在《中国科学技术史》(农学卷)一书中,书后索引主要收录了该书中出现的农史领域相关的主题词、各种名词和一些篇章的主题,共有主题词汇1 038条。
《中分表》(第2版)中农史相关词汇。《中分表》是在《中图法》和《汉表》的基础上编制的、两者兼容的分类主题一体化情报检索语言,1994年出第1版,2005年发行第2版,包括印刷版和电子版。《中分表》(第2版)包含类目52 992个,主题词110 837个,主题词串59 738条,入口词35 690个,包含哲学、社会科学和自然科学所有领域的学科和主题概念。由于农业史涉及的内容分散,在《中图法》中未单独列类,因此我们通过人工挑选出农业史类目及相关类目,共59条,然后将与这些类目对应的词收录到农史领域词表中来,共计274个。
将以上五个来源中的农史词汇收集起来,共有词汇4 930个。合并去掉重复的部分,共有词汇4 095个。五个来源的词汇重合度不高,说明这些工具书因为收录信息的范围针对性不同,收录的词汇也各有偏颇。加上编制年代已久,来自于它们的词汇并不能覆盖整个农史学科领域的主题和概念,尚有一些农史专业词汇未被收录,有必要从第二个词汇来源———文献中进行挖掘。
②从农史文献中收词
从文献中选取出来的术语必须是词或词组这样具有完整意义的语义单元。但在中文中词与词之间缺乏明显的语义间隔,因此从语料中识别出文献中出现的词与词组具有一定的难度,通常采用人工抽取和自动抽取两种方法:
人工抽取。这种方法是由人工辨认、识别出文本中的农史词汇,并将其抽取出来。
自动抽取。自动提取术语是利用计算机在文本语料中抽取符合要求的词汇。主要的提取方法有三种:利用语言学知识进行术语自动抽取、利用统计学知识进行术语自动抽取和将语言学和统计学知识结合起来的混合方法来自动抽取术语。对应这三种方法又有三种术语抽取模型:规则模型、统计模型和规则统计结合模型。规则模型和统计模型各有优缺点,规则统计结合模型是对这两种方法的有效结合,能有效地改善术语抽取的性能[10]。
采用人工方法收词需要抽词人员具备相当的专业知识,抽取效果好,但要投入大量的人工,是一项成本高、耗时长的工程;采用计算机抽词,省时省力,但噪音大,精度不高。本研究采取自动抽取为主,人工判别为辅的方式来获取农史词汇。
对于领域内术语的抽取,应以术语的单元完整性和领域相关性为依据[11]。换言之,要求抽取出来的候选字串是语法结构上的完整单位,即是一个有语义的词或短语,并且要求与该领域的主题相关。
本研究将从农史文献资源库中采集农史专业领域的术语。农史文献资料库包括:农史文献题名库(包括农史著作和论文)和农史论文全文库两个部分。其中农史文献题名库收录了清末至今的农史文献30 000余篇,农史论文全文库主要是1980年至今的在农史核心期刊和主要相关期刊上刊登的论文10 000篇。通过对全文采用经典的N-元语法分词试验,发现这种方法虽然能挖掘出一些完整的词汇,但是人工审核排检耗时耗力,事倍功半,可行性不高。题名是一篇文献主题的集中体现,尤其是一些重要的词汇和新出现的术语,会在题名中首先反映出来。综合考虑,从题名中发现术语明显优于从全文中发现,故本研究主要是从题名中进行选取。
学术文献的题名具有概括性、精炼性和报道性,基本上是名词性的词组,具有固定的句式和鲜明的语法特征。由于题名在整个文献中的特殊位置,它力图浓缩和揭示文献的内容主题,除了一些通用词,如“的”、“与”、“研究”、“综述”、“述评”、“再议”、“小议”等及一些标点符号外,出现的大都是具有实际意义的农史专业词汇。这些出现在题名中的通用词和标点符号,一般是两个词语之间一个明显的分隔标记。通过这些分隔标记,可以把标题分隔成具有一定意义的字串序列,有的字串甚至可以直接成词。
如标题“氾胜之与《氾胜之书》”,通过“与”和“《”、“》”这样的分隔标记的过滤,可以得到“氾胜之//氾胜之书/”这样的切分结果,直接就可以分出“氾胜之”和“氾胜之书”这样的具有完整意义的名词术语。
当然,并不是所有的情况都是这样的,也有不能成词的情况存在。如“由母权制氏族向父权制氏族过渡是否是由锄耕农业向犁耕农业过渡”,经过停用词过滤后,得到的结果是“/母权制氏族/父权制氏族过渡/锄耕农业/犁耕农业过渡”,其中“母权制氏族”、“锄耕农业”都可以单独成词,而“父权制氏族过渡”和“犁耕农业过渡”这两个字串序列却不是一个术语概念,需要进一步处理。
据此,本项研究设计出如图5-1所描述的术语提取模型,以从农史题名库中提取农史词汇。
通过实验发现,如果停用词表构建得完备合理,可以从标题中直接切分出大部分具有完整语法结构的词汇。本研究通过多次实验,构建出一个适用于农史领域的停用词表,收词421个。先用停用词表中的词汇和分隔标记来切分题名,然后对分割后的形成的词串序列进行频次统计,频次越高表明该词串序列成词的可能性越大。
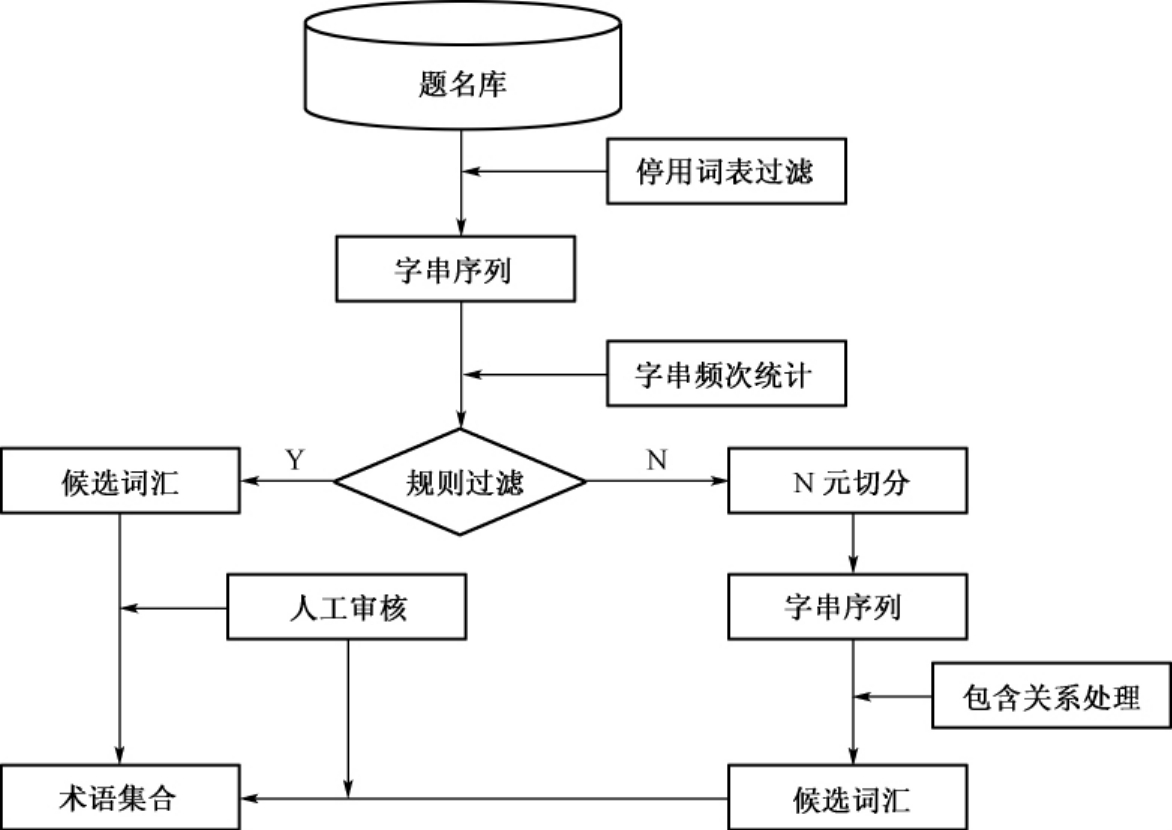
图5-1 术语抽取模型
对30 000篇文献标题进行处理,生成词串序列35 537条,最短的词串序列仅1个汉字,最长的达到19个汉字,出现频次在1~474次之间,其中频次最大的前20个词串序列如表5-2。
由表5-2可见,通过分隔标记发现的词汇,频次高的基本上是具备完整意义的词汇,并且与农史领域相关程度较高。
表5-2 基于停用词过滤的词串序列示例

续表5-2
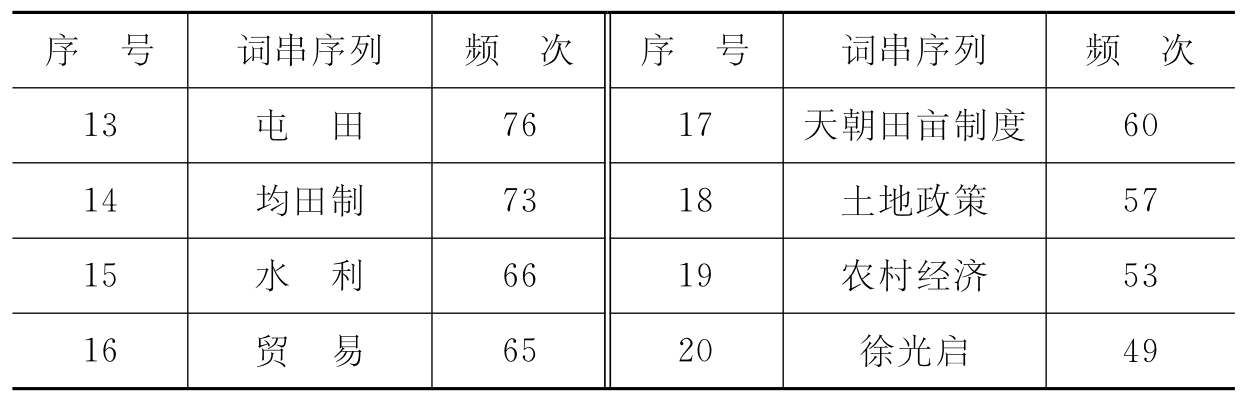
一般汉语词汇以二字、三字、四字词为主,但考虑到专业术语专指程度较高,长词的专指程度更高,因此,本文首先提取出现频次大于等于2,字数在2个及2个以上的词串序列,共5 013个。对这5 013个词串序列进行分析,其中不成词的仅1 646个,剩余的词汇中,未被收录到停用词表中的通用词278个,已经存在于农史词表中的词745个,剩余词汇均是与农史相关的并具备意义的词汇,共2 344个。如“稻作农业”、“田制”、“李冰”、“铁农具”、“井田”等,而这些词往往是农史文献中出现频次很高的核心词汇。
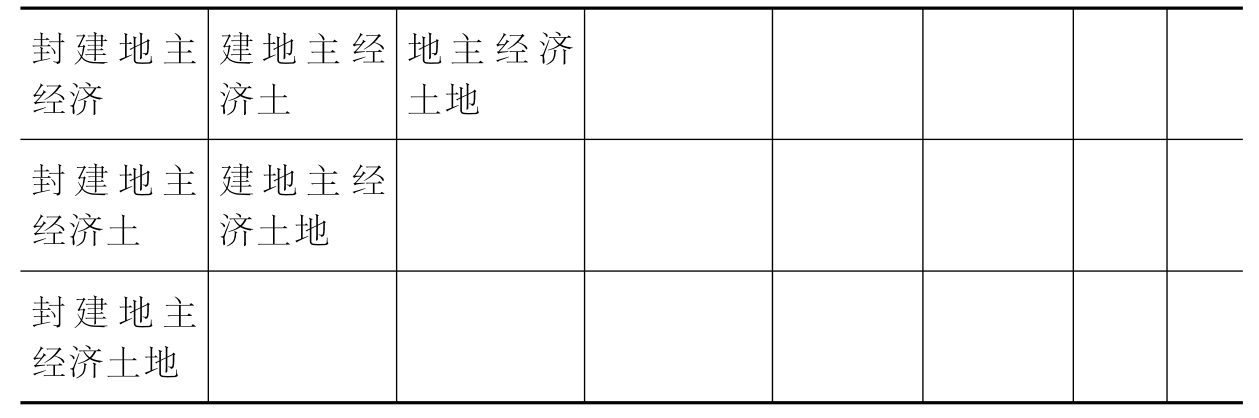
第二步对不符合上述频次和词长规则的词串序列,再采用N元切分统计来发现术语。经过N元切分后形成词串序列,如其中的一个词串序列“封建地主经济土地”,采用N元切分形成表5-3所示的词串。
表5-3 N-元切分生成词串示例

续表5-3
为了减少系统计算量,充分考虑到专业词汇的长度一般不超过9个汉字,本系统将最大切分长度限定为9个汉字。N元切分后,合并,统计频次。
首先,根据频次和字串长度,去掉频次为1、字数为1的字串,共生成新的字串38 258个。
其次,对不完整的字串进行过滤。通过N元切分后产生了很多不能构成词汇的字串,称为伪词串,如“封建地”、“建地主”等,这些伪词串需要通过一定的方法进行过滤。如果单纯依靠出现频次过滤,许多高频的伪词串可能都被保留了,因为“封建地主”在整个语料库中出现的频次很高。所以,这些词的部分,如“封建地”、“建地主”这样的伪词串出现的频次也会相应地很高。因此,必须首先对这种与真正的词串,即完整结构的词汇,存在着包含关系的伪词串进行过滤。
过滤伪词串的方法有很多种,如林颂坚提出用前(后)接字复杂度来进行过滤[12]。该方法基于如下的原理:在一个语料库中,如果一个字串前(后)连接字的情形不多的话,那么这个字串很可能是某个词汇的一部分,而非一个完整的词汇,是N元切分后形成的伪词串。如前文所提到的例子,字串“封建地”的后连接字只有一个可能是“主”,因此不是一个完整的词汇;同样,字串“建地主”的前接字选择可能,也不是很多,所以也不是一个完整的词。但是“封建地主”、“封建”、“地主”都是一个完整的词,前后连接字的可能情形非常多。公式5-1为字串S的前接字的复杂度CaS。
![]()
同理,公式5-2为字串S的后接字复杂度CSb
![]()
式中,CaS和CSb分别表示字串S的前接字复杂度与后接字复杂度,a和b分别代表字串S在论文资料中的任何一种可能的前接字和后接字,FS、FaS和FSb分别是字串S、aS和Sb的出现总频次。从公式5-1前接字的情形看,若是字串S的前接字种类越多,而且每一种前接字出现的次数越接近时,CaS的值越大;反之,当字串S前只有一种前接字时,CaS的值等于0;或是有一个前接字出现的机会较其他的大得多时,则CaS的值接近0,表示该字串再加上这个前接字可能才是一个词汇。前接字复杂度越大,代表该字串越有可能是一个独立完整的词汇,而不是其他词语的组成部分;后接字的情形也是相同的道理[13]。
本研究对这种方法进行试验后,发现其针对完整的句子有一定的效果,但复杂度阈值的确定不好把握。因本研究处理的对象已经是经过停用词过滤后的碎片了,其前(后)接字的一些信息已经损失,但这种前(后)接字的思想为我们处理存在包含关系的词串和伪词串提供了思路。
我们知道,经过N元切分后形成的字串集合中,除了最短字串没有子串,最长字串没有父串外,其他所有的字串都存在子串和父串[1]。
对于子串是伪字串的情况进行过滤。基于这样一个原理:在经N元切分后形成的字串库中,字串S在整个库中出现频次为FS,其前接一个字符形成S的父串aS,aS在字串库中出现频次为FaS。因为子串来源于父串,FaS必然大于或等于FS,但如果FaS、FS两者相等,则表明子串S一直是作为aS的一个组成部分而存在的,即S的前接字情形只有一种,故字串S很有可能是一个伪字串。通过这种方式就可以将子串是伪词串的字串过滤掉。后接字父串Sb的原理相同。其实,这种方法就是前接字或后接字的情形只有一种情况的特例。这种方法虽然无法排除所有的伪词串,但能保证被排除的字串都是伪词串。
如表5-3中的字串,最后保留的字串为“封建地主”、“封建地主经济”、“地主”、“地主经济”、“经济”、“土地”,而像“封建地”、“封建地主经”等这样的伪词串则被过滤掉。
采用这种方法过滤后生成候选词串11 768个。使用从工具书和第一次发现的词汇组成的词表来对这部分候选词串进行过滤,最后剩下8 461个候选词串,按频次高低排序,人工审核筛选,保留词汇6 319个。
将从工具书和文献题名中抽取的词汇进行合并,生成农史概念词典,共有词汇12 758个。这种方式相比完全依赖N-元模型来识别,计算量少、识别精度高,比较适合于从题名这样特殊的文本数据中发现语词。
由于本词表收集的语词来自于农史专业的相关工具书和农史文献题名,这些词汇与农史领域的相关性远远高于从全文中提取的词汇;并因词量有限,这些词汇均经过人工审核,因此,可以大致认可这些词与农史领域的主题相关。
(2)词汇控制
词汇控制是构建叙词表的一个重要步骤,包括词类控制、词形控制、词义控制、词间关系控制、先组度控制等[14]。本研究构建的农史领域词表,是一种自然语言叙词表,对于词汇控制的要求并不如叙词表那样严格。但从文献标引和检索的角度来看,还有必要对收集来的农史词汇进行一定的规范化控制,主要是外在形式上的控制,比如词汇类别、词汇长度、词形。
词类控制:主要选择名词,必要时可以考虑收录少量形容词,其他类别的词汇,如动词、助词、数词、量词等一般不收。
词长控制:一般来说,词汇的长度越长,其先组度越高,表达的主题越专指,检索效果越好;但另一方面,如果词汇过长,一来会降低其作为分词词典抽词的效率,同时大大增加分词过程中的时间消耗,二来一般长词表达的意义通常可以通过两个或多个短词的组配表达出相同的概念,因此,词汇太长也没有必要。本词表将应用于农史文献的自动标引,因此,我们把词汇长度控制在9个汉字以内,对于原先的长词表达的概念用其他的术语组配来表达。如出现在《中国农业百科全书·农业历史卷》中的“珠江三角洲农田水利史”,可以拆分成“珠江三角洲”+“农田水利史”两个词,通过概念组配实现。
词形控制:此处所说的词形不同于叙词表构建中的词形控制,主要是对词汇中出现标点和一些符号的控制。检索过程中很少会有人把标点符号用在检索词中,比如“《氾胜之书》”,一般检索时都是直接用“氾胜之书”,不会加书名号去检索的,因此,在领域词表中只收录“氾胜之书”,不同时收录“氾胜之书”和“《氾胜之书》”;又如“吕氏春秋·上农”,会被拆分成“吕氏春秋”和“上农”两个词语,但在检索扩展中会建立两者之间的关系,以提示用户。
通过以上的规范化处理后,将涉及地名和时代的词汇提出另外收录,最终形成的农史领域词表共收录有词汇12 263个。
(3)术语概念关系识别
术语之间的关系的识别和建立是构建词典的关键所在。相关的研究表明,现在关于术语关系识别的方法主要三种:词汇信息、语法结构和统计信息[15]。
①词汇信息
用词汇信息来发现术语间关系的方法,是利用某些标志性词汇来发现词汇之间的概念关系。如通过“亦称”、“也称为”、“简称”、“包括…”、“分为…”、“之一”等标志性词汇,可以发现术语之间的等同和等级关系[16]。
如:区田法又称区种法,是我国古代人民所创造与总结的抗旱夺高产的耕作法……
通过标志性词汇“又称”,可以提取出“区田法”和“区种法”之间的同义关系,即等同关系。
又如:羊是中国传统“六畜”之一
仓储主要分为常平仓、义仓和社仓3种。
通过标志性词汇“之一”、“分为”,可以发现“羊”与“六畜”、“仓储”与“常平仓”、“义仓”、“社仓”之间的等级关系。
这种方法是依赖于语言文字学上的一些特征来识别术语之间的关系的,只要这种关系在文献中出现一次就能够被发现出来。尤其在词解工具书中,术语释义通常会使用其同义词或上下位词,如《中国农史辞典》中对“丁赋”的释义:
丁赋:亦称丁税、丁钱、丁银、丁税钱、身丁钱。
这种模式在词典中经常出现,为我们采用标志性词汇发现术语间关系,创造了前提条件。但是这种模式的穷举有其不可回避的困难。本研究以此作为辅助手段,列举出18种标志性词汇,从《中国农史辞典》、《经济大辞典·农业经济卷》、《中国农业百科全书·农业历史卷》以及10 000篇农史全文中识别出一部分词汇的等级和等同关系。
这些标志性词汇包括:“亦称”、“又称”、“俗称”、“简称”、“通称”、“亦名”、“又名”、“又叫”、“俗名”、“也称”、“也叫”、“参见”、“分为”、“划分为”、“之一”、“包括”,“一称”,“又作”。
通过这种方式共建立了4 528组词汇之间的等同关系。
②语法结构
以语法结构为基础的词汇关系的发现通常基于短语的偏正结构,分析短语的中心语和修饰语来发现等级关系。如“铁农具”、“木石农具”、“青铜农具”,“农具”是中心语,所以“铁农具”、“木石农具”、“青铜农具”是“农具”这一概念的下位概念,能够发现一些等级关系。但中心词语难以确定,并且未必都符合这种结构,如“农具史”、“农具图”,相对“农具”而言是一种相关关系。因此,限于目前语言学研究的现状,这种方法的可行性不高。
③统计信息
除了上述两种依赖于语言学知识发现术语间关系的方法,以统计信息为基础的方法是目前发现词汇之间关系最为普遍的方法。这类方法利用术语在文献中出现的次数作为统计的信息。当某两个术语在同一文献中出现时,称这两个术语在文献中具有共现关系。如果这两个术语在文献中的共现情形越频繁,则表示这两个术语之间有可能具有越接近的概念关系。但必须说明的是,通过统计信息计算出来的术语之间的关系只是一种在文献中术语的共现关系的显示,不一定能保证都具有语义上的关联,但用在信息检索的扩展提示中是可行的,符合我们构建农史领域词表的要求。
这种统计信息识别法可以分为对称式和非对称式两类[15]。
对称式方法认为术语之间的关系是对等的,即计算出术语Ta对术语Tb的关联值S(Ta,Tb)与术语Tb对Ta的关联值S(Tb,Ta)是相等的。对称式方法中最为著名的研究是利用向量空间模型,以术语在文献中出现的次数作为特征的基础,产生术语的特征向量,并计算每一对术语特征向量的余弦值,作为术语关系的估算值,余弦值较大的术语彼此之间具有概念关系,可以进一步应用。
但事实上,术语之间的关联并不是对称的。比如“均田制”是“土地制度”的一种,但“土地制度”不止“均田制”一种,因此“均田制”对“土地制度”的关联应大于“土地制度”对“均田制”的关联。由此可见,术语之间的关联不具备对称性。这种非对称性能够揭示出术语之间的包含关系。在词典中,上层概念的术语往往对于下层的相关术语具有包含关系,也就是说下层的术语出现的文献中经常会有上层术语的出现。对于给定的两个术语Ta和Tb,如果要计算Ta和Tb的包含关系,可以用在所有出现术语Ta的文献中同时出现Tb的相对频率来估算,如果相对频率超过某一给定的阈值,则可假设Ta对Tb具有包含关系。这个相对频率的计算公式为:
![]()
S(Ta,Tb)表示词汇A对词汇B之间的包含关系;
dab表示词汇A和词汇B同时出现的文献数量;
db表示出现词汇B的文献数量。
当S(Ta,Tb)接近于0的时候,术语Tb的出现与Ta无关;当S(Ta,Tb)接近于1的时候,只要出现术语Tb,必然同时出现Ta,此时可以判断Ta对Tb具有包含的关系。比如,在领域词表中,“土地制度”是“井田制”的上位概念,那么在讨论“井田制”的一组文献中往往会出现“土地制度”这个词,根据公式5-3可以计算出“土地制度”与“井田制”这组词汇的包含关系值接近1。
本研究采用非对称方法来计算农史领域词表中术语间关系。两个词汇在语料库中的同现情况可以分为三个层次:出现在同一句子中;出现在同一段落中;出现在同一篇文章中。显然,层次越低,两个词汇越相关。但对10 000篇全文进行篇章分析,统计词汇,运算量巨大。为了避免计算复杂化,本研究仅对出现在每篇文章中最关键的K个词语进行统计。即用领域词表中的词对每篇文章进行抽词标引,按出现频次从高到低排序,取前K个词汇作为该篇文章的主题内容来分析词汇共现。本文中K取值10。计算领域词表的词汇在文献中的共现频次,采用公式5-3计算出每个词汇与其他词汇的关联度,取关联值大于等于0.4的词汇作为该词汇的相关词。
表5-4反映了与术语“井田制”、“井灌”、“义仓”相关词的情况。
表5-4 基于文献共现的词汇相关性发现示例

由表5-4可以看出,这种基于文献共现发现的词汇关系,包括等级关系、等同关系、相关关系,主要是相关关系。
将通过上述几种方法识别出来的术语关系进行合成,生成一个以揭示等同关系和相关关系为主的农史领域词表,在同义关系控制后,农史领域词表的条目为6 263条。
(4)词汇的组织和显示
在领域词表的组织和显示采用两种方式:一为按字顺编排的循序方式,一为按主题排列的概念阶层方式,多以后者为主。在本研究中,为了便于浏览和显示美观,农史领域词表采用字顺循序编排,双窗口同步显示。如图5-2所示,通过点击左栏概念词表字顺显示表中的任一个词,在右栏同步显示该词汇的相关语词和概念关系。

图5-2 农史领域词表的组织与显示
5.2.3 领域词表性能评测
词量、词汇等同率、参照度、关联比、清晰度、先组度等是测评叙词表词汇性能的几个主要指标。农史领域词表不同于传统环境下的叙词表,是一种自然语言叙词表,我们最初的编制目的有二:一是用来对农史文献信息资源进行主题标引,尤其是用作计算机自动分词词典对农史文献进行自动标引;二是作为后控制词表,用于检索的扩展。根据这两个编制目的,参照叙词表的评测指标,笔者提出用领域覆盖度和入口词比例两个指标对农史领域词表进行测评。
(1)领域覆盖度
所谓领域覆盖度是指领域词表中的词汇能否完整地揭示和表达出农史领域的主题,这是衡量领域词表用于信息标引的能力的指标。农史领域词表在本研究中主要作用之一,就是作为抽词词典用于农史文献的自动标引。笔者用其分别对农史论文全文数据库和题名库进行抽词标引,检验其是否能够将文献的主题概念揭示出来。对10 000篇全文数据自动标引,统计其标出主题的结果总数,并每隔100条取一条记录进行抽样分析,分析其自动标引的结果是否正确、完整。统计结果见表5-5。
表5-5 农史论文全文库自动标引结果测评

采用同样的方法对30 000篇题名数据进行自动抽词标引,分析其标引结果,见表5-6。
表5-6 农史论文题名库自动标引结果测评

从上述结果可以看出,初步构建完成的农史领域词表基本上覆盖了农史领域的主要主题,较全面地收录了农史领域的术语词汇。
(2)入口词比例
入口词比例即词汇等同率,主要是评测词表对同义词和近义词的控制程度。本词表构建的目的之一是用作检索的后控制词表,因此应大量增加入口词,揭示词汇之间的等同关系。
入口词比例=具有等同关系的词汇数/词典总词数
该领域词表的入口词比例达到了52.30%,其中最多的一个词拥有同义词69个,明显高于传统叙词表的入口词比例,《中国分类主题词表》第2版的入口词比例为32%[17]。
总的来说,农史领域词表是一个适用于网络环境中农史信息资源标引和检索的“自然语言叙词表”,是一种基于词汇共现统计来建立词汇之间关联的“共现叙词表”。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











