



8.1 知识组织系统在信息组织中的应用
主题检索和分类浏览是信息资源组织的两个最基本的途径和要求,为了满足这两个要求,必须对信息进行主题标引和分类标引。
分类标引和主题标引是信息内容描述和揭示的两大组成部分,也是信息加工的关键内容。分类标引简称分类或归类,是依据一定的分类体系,对信息资源实体的内容特征进行分析、判断,赋予分类标识的过程。对信息实体赋予分类标识,有助于将各类信息纳入相应的知识范畴,建立相应的分类检索系统,将便于用户根据信息资源实体的知识范畴特征,按照系统提供的分类途径进行查找,从信息集合中获取所需要的信息。
主题标引是采用关键词表或主题词表,依据一定的主题标引规则,赋予信息资源实体语词标识的过程。主题标引在主题分析的基础上,将信息资源中具有检索意义的内容特征转化成相应的主题词(串)或关键词(串),并以这些标引词为标识来组织主题检索系统,以便用户通过语词检索或主题浏览途径从信息集合中获取所需信息。
传统环境下,这两项主要的标引工作均分别由专业的标引人员手工完成。在网络环境中,信息增长的压力促使众多的图书情报学家和人工智能专家投入大量的精力到信息自动标引的研究中,取得了一些进展和成果。
广义的自动标引包括主题标引自动化和分类标引自动化,本书为了便于描述,将主题标引自动化简称为自动标引,而把分类标引自动化简称为自动分类。图8-1揭示了自动标引的方式及其相互之间的关系。
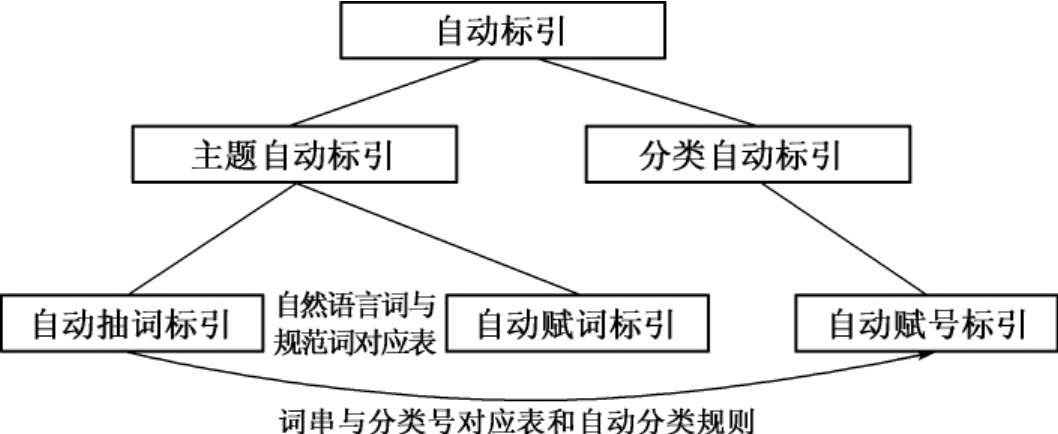
图8-1 自动标引的方式及相互关系
描述是知识组织系统的四大基本功能之一,网络环境中的知识组织系统除了应发挥作为受控词表揭示信息内容的基本功能,还应提供对信息自动标引和自动分类的支持。
8.1.1 基于知识组织系统的自动标引
自动标引包括自动抽词标引和自动赋词标引两种。自动抽词标引是指使用计算机自动抽取文本资源中表达文献内容的相关语词作为主题标识,标引词直接来源于文献本身,不进行规范化控制;自动赋词标引则是在自动抽词标引的基础上,依据自然语言词汇与知识组织系统中受控词汇的对应关系,将抽取出来的关键词自动转化成受控标引词,建立倒排索引文档,用于主题词检索。
自动标引的思路基本上是模仿人工标引。在人工标引过程中,标引人员总是尽量在文中选择能较好地反映文献主题的原文语词,若是赋词标引,再将这些语词转化成预先编制好的词表中的主题词。语词选择往往受到一些因素的影响,如词语在文献中出现的频次、语词出现的位置(题名、文摘、小标题、结论等)及语境。自动标引过程中,计算机模仿人,对电子文本中的词的频率、位置和语境进行统计分析以实现抽词标引。如果是自动赋词标引,则在抽词标引的基础上再借助于规范词表将抽词结果转化成受控词。图8-2反映了近50年来自动标引研究的发展情况。
从图8-2可知,主要有3个领域的研究者对自动标引进行了不同角度的研究[1]:①图书情报领域,主要从资源构建角度进行研究,为主题标引提供了丰富的词表资源,即各种类型的知识组织系统;②语言学领域,从文本分析的角度研究了主题提取的机制与方法,利用词法、句法、语义以及篇章知识进行不同层次的主题提取研究;③人工智能领域,主要从机器学习角度对自动标引进行了大量的研究,如利用启发式知识、标记数据的机器学习、无标记的机器学习、集成学习等方法的运用。知识组织系统是自动标引的资源基础。
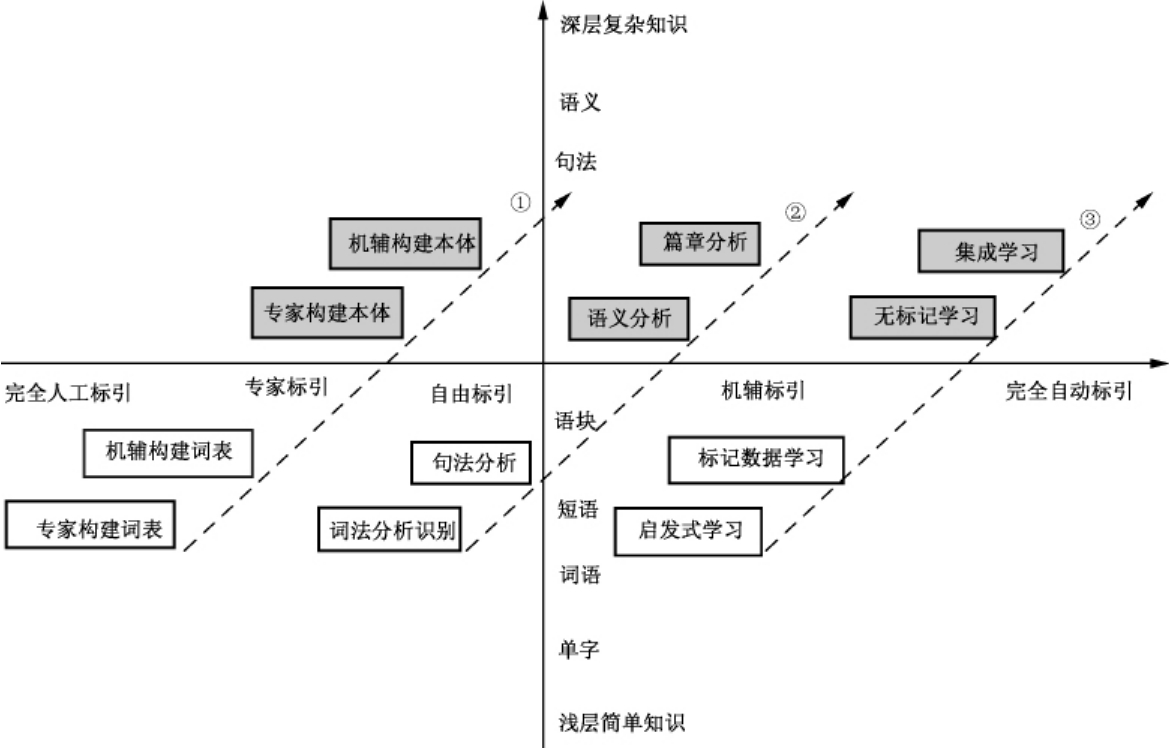
图8-2 自动标引研究路线图
图表来源:章成志.自动标引研究的回顾与展望[J].现代图书情报技术,2007(11):33~39.
自动标引的方法有很多种,从采用的理论来划分,主要有统计法、语言法和人工智能法三种类型,目前取得进展较多的自动标引系统大多采用统计法。统计法依据词汇在文献中的分布特征和规律,找出反映文章主题的标引词,是各类自动标引方法中使用历史最长、运用范围最广的方法。根据统计处理对象的不同和处理方法的差异,统计法又可以分为词频统计标引、加权统计标引法、N-Gram标引法、统计学习标引法、概率标引法等方法,统计标引法较为简单适用,也取得了一些实际的标引效果,同时它也是其他标引方法的重要组成部分,因而应用较为普遍。
自动分词和统计加权是统计标引法中两项最主要的工作。
如何将一篇完整的文章分割成多个词汇来处理,是中文文献自动标引过程中的一个重要环节。因此,中文自动标引必须先处理中文文本的自动切分,即自动分词。严格意义上讲,从信息检索角度来看,自动标引过程中的分词应该是自动抽词,即采用抽词词典,一种简单的词汇列表,从文本中抽取出反映文献主题的词汇,而不是简单地将文本分割成若干词汇片断。所以,目前中文自动标引中使用较多的是词典标引法。词典标引法的原理是:构造一个机内词典(主题词词表、关键词词表或部件词典等),然后设计相应的算法,用文献数据去匹配词典,匹配成功者则可抽出作为标引词标引文献。
基于词典的标引法为了选择出符合文献主题的标引词,往往要进行加权统计,一般从词频、位置和词长等方面进行加权。
词频加权:Luhn提出一篇文章中一个词出现的频次是这个词的重要性的有效测度,将词按其在文献中出现的频次排列,以一定的标准排除高频和低频词,剩下的就是最能代表文献主题内容的词。频次加权建立在比较成熟的语言学统计研究成果之上,具有一定的客观性和合理性,并且被证明是行之有效的。为了使统计加权发挥最佳的标引功能,还要综合一些其他的因素,如位置、词长等。
位置加权:词在文献中出现的位置也会对最终的标引结果产生影响。一般来说,出现在文献题名中的词最有用(当然,一些文学性的题名除外),其次是出现在文献各级小标题或章节目录或文献提要中的词,最后是文献正文中的词。因此,在计算标引词的权值时要充分考虑其出现的位置,进行位置加权。
词长加权:一般来说,中文中较长的词往往反映比较具体、专指的概念,而较短的语词常常表示相对抽象、宽泛的概念,如“农田水利史”要比“水利史”表示的概念更专指、更具体。词越长包含的信息量越多,作为标引词时应赋予的权值也相对高些。
综合词频、位置和词长因素,基于词典进行抽词标引或赋词标引是目前自动标引方法中比较成熟的一种统计标引方法,具体流程见图8-3[2]。
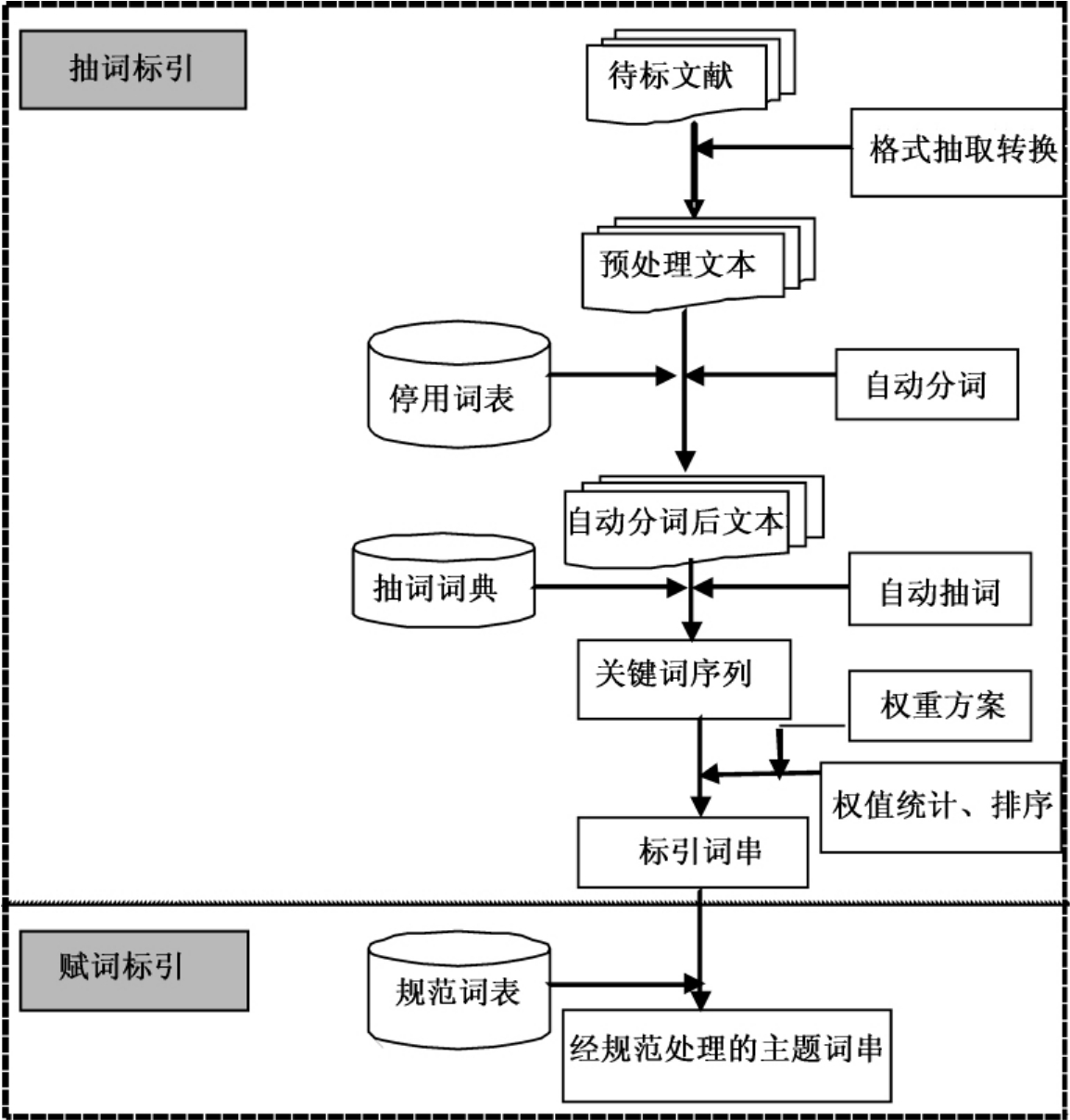
图8-3 基于知识组织系统的自动标引流程图
由图8-3可知,抽词标引的实现较为简单,首先利用停用词表对文献进行简单的分割,再利用抽词词典从文献中抽取出标引词,根据标引词权值加权方案进行权值计算、排序,最后根据预先设置的阈值,选出权值超过预设阈值的语词作为标引词。标引结果为来自文献本身的关键词,专指性好;赋词标引建立在抽词标引的基础上,是对抽词标引结果的后控制,通常借助于受控词表,将来自文献的关键词转化为词表中规范的主题词。目前的自动标引研究多采用抽词标引的方式,很少使用赋词标引。一方面因为用户基本上都使用自然语言检索,采用赋词标引反而不能取得较好的结果;另一方面由于目前缺乏自然语言向受控语言转化的词表和技术。在这一标引过程中,停用词表、抽词词典、规范词表等都可以是简单的词汇列表型知识组织系统。
8.1.2 基于知识组织系统的自动分类
分类是在主题分析的基础上将文献信息分门别类地组织起来。自动分类建立在自动标引的基础上,根据分类体系预先设立与否,可分为聚类和归类两种。所谓聚类就是完全根据文本的内容相关性来组织文献集合,将整个文献集合聚集成若干个类,并使属于同一个类的文献尽量相似,属于不同类的文献差别明显。由于事先没有可以使用的分类体系,这种分类是一种“无监督的学习”,其特点是“先有文献后有类”,并且类目体系处于不停的变动中[3]。聚类在数据挖掘领域中应用非常广泛,对于信息检索,尤其是针对学术信息资源的检索而言,所实施的分类标引多为归类标引,即事先有确定好的分类体系,分类过程就是将文献归入到与其相似度最大的类目中。通常所说的自动分类主要指的也是这种归类标引。
传统的文献分类历史悠久,在文献组织中发挥了相当的作用。自动分类是为适应信息资源激增的需求而迅速发展起来的,成为信息自动化处理中较为活跃的一个领域。计算机界、图书情报界都投入了大量的人力、财力来研究网络环境中的自动分类。目前自动归类的方法主要有两种类型[4]:
第一种是以机器统计学习的算法完成。采用机器学习的方法来自动分类,实际就是将文献中提取出来的标引词视为该文献的特征,通过学习某一类文献集合的特征构建分类器;在分类过程中,将待分类的文献的特征词串(即标引词)与分类器中的各类类目的特征进行计算比较,得出分类概率最大的类目。图8-4是机器统计学习自动分类的步骤图:

图8-4 机器学习自动分类步骤图
资料来源:薛春香,夏祖奇,侯汉清.基于语料和基于标引经验的自动分类模式比较[J].南京农业大学学报(社会科学版),2005,5(4):85~91.
目前采用机器学习进行自动分类的方法有很多种,比如支持向量机、贝叶斯分类、K-近邻分类、神经网络算法等。这种方法被国内外计算机和图书情报领域广泛采用,比较适合于面向主题或行业的粗分类,是自动分类发展的一个主要趋势。
第二种方法是一种基于分类知识库的自动分类方法,依据从大量书目标引记录(元数据)中挖掘出来的标引经验进行自动分类。这种方法利用书目数据库中存在的大量的同时包含主题标引和分类标引信息的标引记录(即分类实例),利用分类法与主题法这两种不同类型的知识组织系统之间的互操作原理,构建分类知识库,即分类号与主题词串的对应表,通过实例匹配算法实现文献自动分类。其分类流程见图8-5。
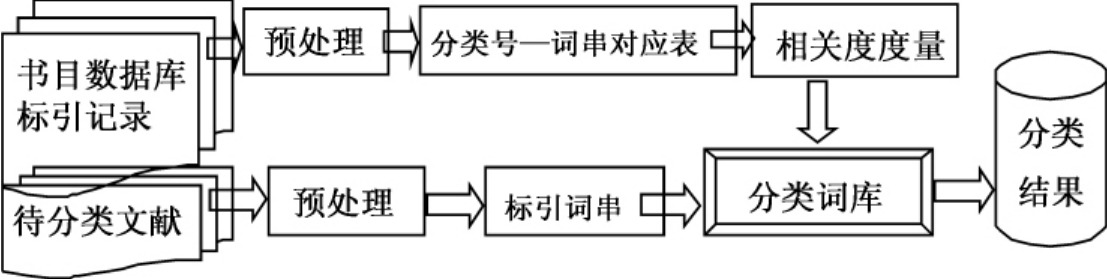
图8-5 基于分类知识库的自动分类步骤图
资料来源:薛春香,夏祖奇,侯汉清.基于语料和基于标引经验的自动分类模式比较[J].南京农业大学学报(社会科学版),2005,5(4):85~91.
这种分类知识库实际上是一个关联丰富标引元数据的分类-主题对应表,是一种分类主题一体化的知识组织系统。这种自动归类方法降低了分类的维度和计算量,算法简单。我们从2002年开始从事这方面的研究[1],并投入到上海图书馆《全国报刊索引》(社科版)数据库的自动分类应用实践中,取得了良好的分类效果。
8.1.3 基于知识组织系统的信息整合
任何一个知识组织系统都会被应用在一个或多个信息资源集合的管理上。传统环境下,知识组织系统与资源集合是相互独立的,通过卡片目录或联机目录建立知识组织系统和文献信息资源库的关联;网络环境中则可以通过超链接技术、数据库等技术将知识组织系统和信息资源库直接进行关联,使两者可以整合在一起,这也是网络环境中用户信息需求的要求。事实上,主题图、本体本身就是概念与资源的结合体,主题图包括主题、关联和信息资源实体,而本体中实例也可以看成是资源的一种知识化。
将知识组织系统与资源集合、信息服务整合在一个共同的平台上,基于知识组织系统提供信息资源内容的展示、导航、检索和统计监测,从而形成广泛意义上的知识组织系统,包括知识组织的语义工具、后台资源和知识产品。
知识组织系统是一个相对固定的知识结构,通过将信息资源不断地添加到其对应的知识组织系统的节点(如类目、术语)下来不断扩展知识组织系统的内涵。譬如,借助于第5章所构建的农史知识组织系统,可以将各种不同类型的农史信息资源进行整合汇集,提供给用户“一站式”的检索服务和知识服务。利用知识组织系统的知识结构和标识,整合农史文献的题录库、全文库、农史工具书(如农史辞典、农史百科全书),今后还将添加图片资料、视频信息,最终形成一个具备信息检索和知识服务功能的农史研究的知识库。图8-6展示了农史知识组织系统与农史资源库的一个简单整合方案。
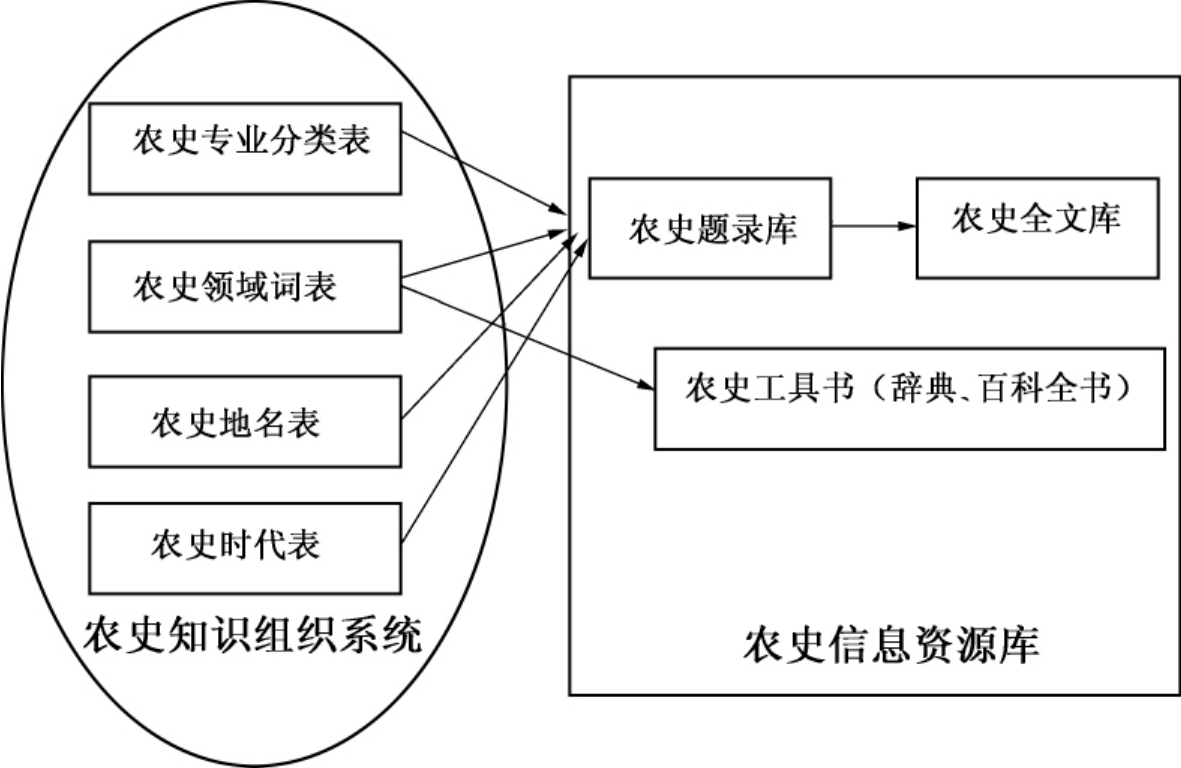
图8-6 农史知识组织系统与农史信息资源库的整合
采用农史知识组织系统中的专业分类表、领域词表、地名表、时代表,对农史文献信息资源进行分类标引和主题标引,则可建立农史知识组织系统中任一元素(或称语义节点)与农史文献信息资源主题的关联。通过知识组织系统中的任一节点,都可以获取相应的文献题录数据,并通过题录数据连接到对应的全文,提供文献检索服务。针对领域词表中的专业术语,采用电子化后的农史释义辞典和农史百科全书提供术语释义服务。农史知识组织系统实现了对农史信息资源的有效组织,而各种类型的农史信息资源是对农史知识组织系统中各种主题的最好阐释,可以从多种途径帮助用户理解农史领域内的概念和知识。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











