



10.4.4 重复博弈下的均衡
在超博弈中,一家公司可以选择永久合作,这时可获取的折现收益是:
或者,该公司可以决定对共享协议采取欺骗行为。如果γ>β/(N-1),那么推论1表明如果一家公司前往中心场所则它将共享知识;因此,只有在除会议时间t以外的期间里出行,欺骗行为才能实现,这必然使该公司在下一次会议的t+1期间被排除掉。这时产生的折现收益是:
如果γ<β/(N-1),还有一个前往中心场所但却不共享知识的欺骗性策略可供选择。在这种情况下,决定不再参与全面合作的公司在会议中将保留知识,因为它在未来将被其他公司排除出局,当前共享知识并不划算。如果除了j以外的所有其他公司都全面合作,那么对于所有的i≠j,有ci=α-(1-r) (β+γ)(N-2);对于公司j,cj=α-(1-r)β(N-1)是参会成本,由式(1)得,公司j采取参会并保留知识策略情况下单个期间的收益为:
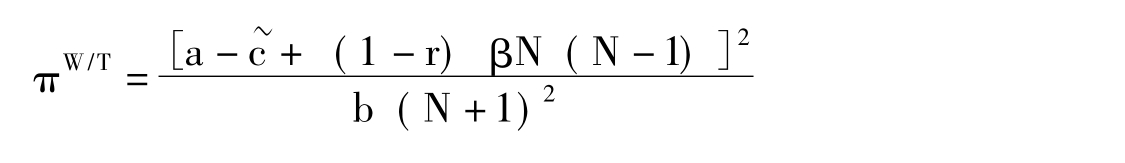
容易看出πW/T>π-;而且,当γ<β/(N-1),也就是πW/T>π-的情况。采用欺骗策略时,公司j的折现收益是:
![]()
下面的命题是描述支持知识交换的极限距离。
命题1:对于前往中心场所参会,如果满足:
那么,知识交换就是重复博弈中的均衡。
命题1表明,互补性强弱对于决定知识交换得以进行的空间距离至关重要。因为在γ=β/(N-1)处,距离极限表达式中有一个拐点。注意在γ= β/(N-1)点,有π+=πW/T,因此DW/T= dC。然而,对于γ<β/(N-1),π+<πW/T,这意味着DW/T<dC;对于γ>β/(N-1),距离极限值变大。下面的命题更详细地刻画了β和γ的变化如何影响DC。
命题2:出行到中心场所的情况下,有a DC/aγ≥a DC/aβ>0,并在γ>β/(N-1)的条件下,有a DC/aγ>a DC/aβ。而且,在γ<β/(N-1)条件下,a DC/aγ和a DC/aβ的值比在γ>β/(N-1)条件下要大。
命题2表明,前往中心场所情况下,无论知识交换是独立型还是互补型的,只要它能更有效地降低成本,更远的距离也会产生知识交换。然而,距离限值更容易对互补强弱做出响应,此外,距离限值在β和γ是凹点。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










