



第四节 数据与核算体系
一、概述
数据以及与之密切相关的国民经济核算体系,是宏观经济模型的重要基础之一。模型对于数据的要求似乎是无限的,永远不会满足;但模型又必须在一定数据条件下才能应用。因此模型受着可能的数据条件的限制,它必须充分利用现有数据。就宏观经济模型的实际应用来说,数据与核算体系的重要性并不亚于经济理论、经济计量技术对宏观经济模型的作用。
首先,数据是模型赖以存在的经济理论得以数量化的基础,相应的核算体系则是经济理论数量化的框架和具体体现。如果说经济理论是宏观经济模型躯体的骨架,那么数据就是这一躯体的细胞。其次,数据与核算体系是宏观经济模型实际应用过程中准确性的根本保证。垃圾式数据的输入,只能得到垃圾式结果的输出。一个严肃的模型工作者,往往要将一半或更多的时间用于数据工作方面。再次,宏观经济模型要能够及时地应用于现实经济问题的研究,要能够迅速地对已出现或将要出现的经济问题做出反应。实现这一目标的根本保证,也是能够迅速准确地按照一定的核算体系采集、处理数据。最后,单独的经济模型由于受研究对象的限制,难免有一定的局限性。宏观经济模型在更大的范围发挥作用的途径是模型之间的交流和连接,而实现交流和连接则首先要求数据与核算体系之间的可交流和可连接性。
宏观经济模型在使用数据时,要考虑数据的内涵性质和外在形式两个方面。数据的内涵性质表现为存量和流量这一对概念,这两个概念的区别将造成模型设定及随机误差项性质的不同。这是第二节讨论的内容。
数据的外在形式表现为对数据系统的一致性的要求。为了保证数据系统的一致性,需要对原始数据进行编辑,而数据编辑的最好形式就是国民收入的核算体系。世界银行的有关专家曾指出数据系统的一致性应包括如下几点[46]:第一,核算体系应以尽可能多的独立数据来源为基础,以保持系统内部的一致性;第二,数据体系应具有直观性,以有助于对经济问题的了解;第三,外贸方面的数据,特别是进出口商品统计,应使用相同的部门分类;第四,建立高质量的价格指数是保持部门水平与总量方面数量一致性的重要条件;第五,应注意以地区和人口分解为基础的社会经济信息的一致性。有关国民收入核算体系的问题是第三节讨论的内容。
二、存量与流量
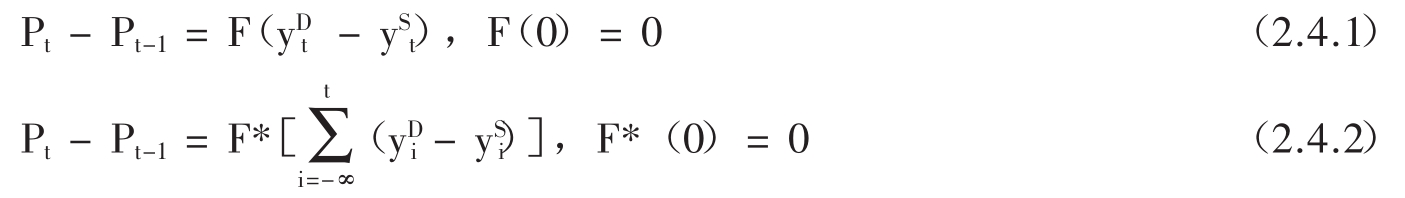
存量和流量是反映数据内涵性质的两个相对概念。早在20世纪40年代末,宏观经济模型方法尚处于初期发展阶段,克莱因就曾指出[47]:“在经济分析中,存量和流量的处理并非总是不相干的。一些简单的动态模型中已表现出存量和流量之间的选择已成为一个基本的问题。”流量反映的是一定时期内各种经济活动的数量度量,而存量反映的是经济活动在某一特定时刻的结果的数量度量。
在宏观经济模型中,选择使用存量变量还是流量变量将影响模型的设定,以及随机误差项的性质。
为了说明存量、流量选择对模型设定的影响,设ySt和yDt分别为t时期对某种商品的供给量和需求量,Pt为t时期的商品价格。为了反映价格对过度需求的变化的影响,可以列出两种方程:(2.4.1)式反映的是价格在流量平衡基础上的调整,而(2.4.2)式反映的则是价格在存量平衡基础上的调整。这是以两种不同的经济理论为基础的。萨缪尔森已经证明了,在连续型函数中,这两种理论模型将会导致完全不同的结果。[48]如果令Z(t)=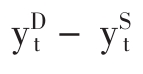 表示t时期的过度需求,则某一时期(T,T + 1)在价格变动条件下能够出清流量市场,即
表示t时期的过度需求,则某一时期(T,T + 1)在价格变动条件下能够出清流量市场,即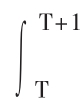 Z(t)dt = 0,并不能保证动态出清市场,即
Z(t)dt = 0,并不能保证动态出清市场,即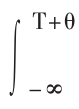 Z(t)dt = 0。对所有的0≤θ < 1,即使在(T,T + 1)时期中,过度需求Z(t)= 0也不能保证出清存量市场。
Z(t)dt = 0。对所有的0≤θ < 1,即使在(T,T + 1)时期中,过度需求Z(t)= 0也不能保证出清存量市场。
在宏观经济模型中,是选择存量变量还是流量变量,还将影响随机误差项的性质。克莱因指出[49]:“在某种意义上,由简单的核算恒等式可将流量变量转换为存量变量,或相反,但是方程和模型的完全的设定,特别是如果要考虑随机设定,则不然了。”一个明显的例子是,在用收入等变量解释对货币流量或货币存量的需求方程中,解释对货币存量需求的方程的随机误差项,显然比解释对货币流量需求的方程的随机误差项,具有更强烈的序列相关性质。当随机误差项具有较强烈序列相关时,将会低估误差项的方差,使得用普通最小二乘法得到的参数估计值在预测中使预测值无效,[50]因而在对存量需求方程的估计中,需要采用差分方法来克服序列相关性的影响。古加拉悌(Gujarati)也曾用一个关于欲被救济者指数(这是一个存量概念的变量)与失业率关系的例子,说明了用存量变量作为被解释变量的方程的随机误差项存在较强的序列相关性。[51]这个例子说明了在处理存量变量方程的随机误差项时,要特别注意误差项的序列相关问题的重要性。
三、核算体系
(一)核算体系的重要性
核算体系是数据的外在形式。它不仅使从各种来源得到的杂乱无章的数据能编辑成有序系统,而且也是科学地采集处理数据的指导原则。当然,宏观经济模型对于核算体系的统一性的要求不是十分严格的,即在模型中仅要求对同一变量或有恒等关系的变量之间使用统一核算口径或体系的数据,而从模型总体来讲,使用完全一致的数据核算口径或体系并不是必要条件(这一点下面还将提到)。但是比较注重数据核算体系严格性的模型,将能更准确地反映社会经济运动现实,更全面地反映经济变量之间的关系。另一方面,在数据核算体系处理上的疏忽,往往会引起人们对模型的迷惑甚至批评。下面就是一个例子:
1964年4月。在英国Bristol大学举行了柯尔斯顿研究会(Colston Research Society)的第十六届学术讨论会。克莱因应邀参加并发表了一篇关于美国SSRC模型的论文。[52]SSRC模型是许多美国经济学家联合研制的布鲁金斯模型的早期形式的用于长期经济分析和预测的简缩版,其中约有150个需要估计参数的随机方程。由于各模块是由不同的学者分别研制的,因此彼此之间的方程设定形式及数据核算口径存在着一定差异。这一点引起了参加讨论的学者的评论。克莱因这篇论文的重要评论人布朗(Brown)在分析SSRC模型与英国的剑桥模型之不同的方式时指出[53]:剑桥模型的主要特点之一是以全面的社会核算概念为基础,有大量的表现社会核算关系的恒等式,从而保证了模型总体有关参数的一致性。而在SSRC模型中,这样的保持总体一致性的恒等式却极少,造成某些总量关系的不统一。布朗列表指出了各部门对几种商品的消费系数的不一致性。
表2-1中各列的和均应为1,而实际结果均不为1。造成这种结果的主要原因就是分别研制模型的美国学者只注意了各块之间估计方法的统一,而忽视了核算体系的统一。关于这一意见,克莱因在回答中认为[54]:“某些内部关系和外推可能彼此不太协调,而我们可以通过将其置于社会核算框架中加以改进。在新的美国模型中我们已经有了一个社会核算(框架)。可能我们应当在这方面做更多的努力。”
表2-1

在简要地讨论世界上流行的两种核算体系——SNA和MPS——之前,需要指出社会核算矩阵(SAM)的重要作用。[55]无论使用哪种核算体系,社会核算矩阵方法都能全面地综合反映出社会经济整体的平衡关系。虽然它在CGE模型中应用得比较广泛,[56]但是它对于宏观经济模型的总量和部门平衡的意义是十分明显的。尽管在宏观经济模型中具体应用SAM可能很困难,而且没有太大的必要,但是它所体现的总体平衡的原则是任何宏观经济模型都不能忽视的。
(二)SNA和MPS
核算体系的产生来源于对复杂的社会经济问题进行分析和研究的必要性。当面对的问题错综复杂时,就需要建立概念和体系以便将问题进行分解和归纳。核算体系就是在建立各种经济活动和经济部门概念的基础上形成的体系。在这方面库兹涅茨做出了奠基性的贡献。他提出的“国民生产总值”(GNP)的概念为现代国民经济核算体系的建立奠定了必要基础。[57]
当代流行的国民经济核算体系,由联合国有关机构总结为两大类:SNA(国民经济核算体系)和MPS(国民经济平衡表体系)。[58]一般来讲,SNA适用于西方市场经济国家,它主要包括:①生产(包括商品分配、商品来源、生产成本三项内容)。②消费(包括国民经济可支配收入及使用,收入的分配和再分配两项内容)。③积累(包括储蓄和投资、资金流量、资产负债表三项内容)。④国外。MPS适用于传统的社会主义中央计划经济国家,它主要包括4个平衡表:①社会产品平衡表(包括社会产品生产、积累、消费平衡表,投入产出表,生产资料供求平衡表,消费品供求平衡表四项内容)。②综合财政平衡表(包括社会产品和国民收入生产、分配和再分配平衡表,国家财政信贷资金综合平衡表,居民货币收支平衡表三项内容)。③国民财产平衡表(包括固定资产平衡表、流动资产平衡表、国民财产平衡表三项内容)。④劳动力平衡表(包括社会劳动力资源和分配平衡表、专业人员资源和分配平衡表两项内容)。关于SNA和MPS两种核算体系的比较,主要考虑:①交易者单位,②生产,③最终消费,④资本形成,⑤进出口,⑥增加值与原始收入等几个方面。关于这两种核算体系的详细介绍和比较研究,国内已有大量的文献,这里不再赘述。[59]
SNA和MPS最大的不同在于二者对国民生产活动衡量范围的认定。SNA以“三要素”论为基础,它认定的国民生产活动范围要比MPS广泛。而MPS则以“劳动价值论”为基础,认为价值形成仅仅同物质产品的生产有关,只有生产物质产品的劳动才是创造价值的劳动。另一个主要差异在于统计计算方法方面。SNA综合使用生产法、分配法和支出法来衡量国民生产活动水平,而在三者所得结果之间发生差异时,以支出法的结果为基准。而MPS则主要使用生产法来衡量国民产品生产总量。[60]从这两个方面来看,SNA要比MPS包括更广泛的内容,对社会经济活动的描述更全面、更准确,也更灵活。
(三)宏观经济模型与核算体系改革
我国的传统核算体系,基本上可纳入MPS体系,但它又有着自己的综合平衡的特点。钱伯海同志在这方面有过精湛的论述,[61]杨坚白同志等也从马克思主义再生产理论方面对此进行过深入研究,[62]为中国的核算体系的发展奠定了理论基础。当前,我国关于国民经济核算体系的研究进入了一个新阶段,经济体制改革的深入发展对进行核算体系改革方面的学术研究提出了紧迫的任务。1986年召开的“国民经济核算体系理论与方法论讨论会”便是一个标志。[63]学术争论的焦点是,在经济体制改革条件下,核算体系是继续沿用MPS还是采用SNA,或者走第三条道路。1988年出版的《国民经济核算若干理论问题》[64]一书反映了各方面的观点。其中,一种观点认为,“不赞成照抄照搬西方的国民经济核算体系,也不赞成笼统地使用国民生产总值(GNP)指标。”[65]另一种观点认为,原有的“核算体系,已经到了非改不可的程度了”。[66]还有的观点认为,“随着我国社会生产力的发展和经济体制改革的不断深入,有必要研究和采用一些新的核算方法。”[67]
作为一个宏观经济模型问题的研究者,我自然倾向于核算体系向SNA靠拢。因为这样至少有助于宏观经济模型的国际比较,特别是某些重要的经济参数的估值的比较,并有助于加强宏观经济模型的国际联结。PROJECT LINK的国际联结就是通过各国模型的进出口部门按照SITC标准分类才得以实现的。尽管各国模型的国内部分并没有使用统一的核算体系。[68]SNA体系的发展和完善是与经济计量理论的发展,与宏观经济模型理论和应用研究的发展密切相关的。使用宏观经济模型方法,分析和预测社会经济问题,需要一个完善的社会核算框架。核算体系新内容的出现,也是由于用模型方法研究经济问题的需要,例如资金流量核算方法的出现。[69]
本节的目的不是研究核算体系是否需要转换或改革,以及怎样转换和改革。这里仅需要指出,由于使用完全一致的数据核算口径或体系并不是研制和使用宏观经济模型的必要条件,经济计量学理论仅对数据提出概率统计性质的假设,而没有任何关于变量之间必须有统一核算体系的假设。例如,在估计农业产出时,完全可以使用自然灾害程度作为解释变量之一,因此核算体系的改革和完善只会给模型的研制和使用带来方便。另一方面,核算体系的变动必然会迫使已有的宏观经济模型的结构和模块、方程做某种程度的变动,然而在应用电子计算机的条件下,完成必要的变动并不存在严重的困难。总之,宏观经济模型所具有的将经济行为关系做随机性处理的特点,使得它对于各种核算体系或核算体系的混合具有适应性。同时,科学的、合理的核算体系是宏观经济模型理论研究和实际应用进一步完善的基础之一,因此它欢迎任何促进核算体系科学化、合理化的变革。就宏观经济模型应用的要求来说,“从正确和错误的角度来争论两大核算体系,是没有意义的,唯一的就看它适用不适用。”[70]在这里,宏观经济模型的任务是怎样在一国实行的核算体系条件下发挥自身的作用,并从模型的理论研究与实践中提出关于核算体系改革的意见。
四、借用数据
在利用宏观经济模型进行经济分析、特别是进行预测性的分析时,往往会遇到数据不足或根本没有合适的数据的问题。在这种情况下,借用数据是一种值得考虑的方法。借用数据方法有两种:
第一种是直接借用,即将其他国家的有关数据或参数值用来作为本国模型中无法估计的参数的参数值。这种借用有以下三种应用:第一,技术参数。例如,某种新的生产技术的使用将在某种程度上改变投入产出系数。它对产出和结构将会产生怎样的影响,可以利用已经采用这种新技术的国家的有关技术参数进行分析。第二,经济技术参数。例如,有关产业部门的资金产出率,在不同国家的相同发展阶段存在着某种程度的相似性。联合国的专家曾将20世纪50年代日本的资金产出系数与40年代美国的资金产出系数作过比较,发现在许多部门之间存在着较强的相似性。[71]第三,行为方程的结构参数。例如,消费方程的边际消费倾向、生产方程的替代弹性、外贸方程的相对价格弹性等。
将直接借用数据作为本国模型参数估计值的对比参考信息显然是有意义的,它有助于为分析检验模型理论基础、方程设定及参数估计值是否正确提供进一步分析的线索。在我国进行经济体制改革时期,社会经济运行从机制到结构都有较剧烈的变动,宏观经济模型面临的重大困难就是数据的缺乏。在这种情况下,谨慎地借用数据不失为一种补救办法。直接借用数据对发展中国家模型的意义更为显著。一些发展中国家已经采用过这种方法,如印度。[72]直接借用数据,特别是借用结构参数必须极其谨慎,需要以全面的理论分析和国情比较研究为基础。
第二种是综合借用,即将若干个国家不同经济发展阶段的有关数据串联起来,用以分析某种经济行为长期运动的普遍规律。例如,对消费形式和消费结构变化普遍规律的研究。使用综合借用数据较为成功的例子是一些美国和日本学者所进行的部门生产率增长的研究。[73]他们所使用的方法对于在我国进行经济增长和产业结构变化的长期趋势研究是有借鉴意义的。
借用数据要求核算体系的统一。怎样结合我国的国情,从理论和应用技术上进行探索,是一个具有实际意义的研究课题。
五、小 结
本节仅讨论了几个与宏观经济模型有关的数据及核算体系的问题,远不能概括宏观经济模型中数据问题的全部。正如第一章第四节中所指出的,数据分析问题已成为当今经济计量理论发展中的八个重要专门问题之一。汇集当代经济计量理论研究最新成果的《经济计量学手册》中有五章专门讨论这方面的问题,占总篇幅的七分之一。[74]限于篇幅,我们不能在这里逐一讨论。需要指出的是,除了这些内容之外,怎样从经济信息理论的角度研究数据和核算体系问题,已成为宏观经济模型数据问题研究的一个方面。国内已有一些学者开始了这方面的研究工作。[75]
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












