



§6.4 医学决策支持方法
在医学决策支持系统中,根据医学知识库中的知识和规则做与诊断或治疗有关的医学决策时,必然会用到推理。推理机相当于医学决策支持系统的大脑,推理机制的恰当与否直接影响到医学决策支持系统的效率与效果。推理机是指基于知识的推理的计算机实现,即在推理过程中解释和执行用某种语言表示的一系列推理规则。
人类的智能活动有多种思维方式,人工智能作为对人类智能的模拟,相应也有多种推理方式,从不同的角度来看,推理方式可以分为演绎推理、归纳推理、默认推理,确定性推理、不确定性推理,单调推理、非单调推理,启发式推理、非启发式推理和基于知识的推理、直觉推理等多种方式。下面主要介绍在医学决策支持系统中常用到的推理策略和方法。
一、正向推理与反向推理
(1)正向推理
正向推理是以已知事实作为出发点的推理,又称为数据驱动推理。正向推理从病人数据库中提供的主诉及实验室检查等事实出发,检查知识库中是否存在可用于对这些数据进行推理的规则。如果存在可用规则,就执行这些规则,推理的结果被添加到数据集中,如果后面的规则依赖于这些新的推理数据,那么后面的规则将被激活。
(2)反向推理
在反向推理中,推理机制是从知识库中选择规则开始,随后检查病人数据库中是否有可供推论的数据。推理机制实际上是从单一规则(目标规则)开始的,然后依据已知的病人数据评估该目标规则的前提是否为真。如果没有数据可以证实这一规则的前提为真,反向推理器就到知识库中寻找其他规则。如果其中一个规则为真,系统就会得出结论:此目标规则的前提为真。如果发现存在这些有用的规则,系统就会利用病例资料分析哪一个规则为真。这种目标驱动的推理过程反复进行,直到证实目标规则为假,或者目标的所有前提都为真。
有一些推理机结合了正向和反向推理。数据很少时,最好从数据开始,因为这些数据可以选择性地启动知识库中相应的规则。如果有很多数据,就不用正向的推理机制,以避免启动无数的规则,这种情况下反向推理的效率更高。
另外,结合正向和反向推理的优点,人们又提出了双向推理机制。双向推理是指正向推理与逆向推理同时进行,在推理过程中的某一步骤上“碰头”。其基本思想是:一方面根据已知事实进行正向推理,但并不推到最终目标;另一方面从某假设目标出发进行逆向推理,但并不推至原始事实,而是让它们在中途相遇,即由正向推理所得的中间结论恰好是逆向推理此时所要求的证据,这时,推理就可以结束,逆向推理的假设就是推理的最终结论。双向推理的困难在于“碰头”的确立和判断。另外,如何权衡正向推理与逆向推理的比重,即如何确定“碰头”的时机也是一个困难问题。
二、确定性推理与不确定性推理
确定性推理是指推理时所用的知识都是精确的,推出的结论也是确定的,其值或者为真,或者为假,没有第三种情况出现。不确定性推理是指推理时所用的知识不都是精确的,推出的结论也不完全是肯定的,其值位于真与假之间。
在医学中我们常常会遇到不严格、不精确的、模糊的知识,比如病人向医生主诉“最近头有点晕”,这一描述中“最近”的时间性和“晕”的程度都是非常模糊的概念。在有的专家系统中,产生式规则本身也有不确定性,比如,有一条产生式规则:“如果患者发高烧且常流清鼻涕,则患者感冒”。这条规则的两个前件“发高烧”和“常流清鼻涕”都是模糊的概念,难以明确“发高烧”的体温边界和时间值边界,也难以明确“常流清鼻涕”的时间频度边界。因此,在应用这些不精确事实和知识时,不确定性推理必不可少。不精确知识的表示和推理现在已成为人工智能领域的一个重要的研究课题。
根据不确定性测度算法的不同,不确定推理主要有下面三种。
(1)基于概率的不确定推理
概率论是处理不确定性的经典理论,在不确定推理中,把能使某个结论为真的证据组成一个集合,把这样的一个集合也称为一个事件,包含在一个事件集合中的元素都能使对应的结论为真,那么,就可以用事件发生的概率来描述和计算推理的不确定性测度,这就是基于概率的不确定推理。
(2)基于可信度的不确定推理
基于概率的不确定推理虽然具有概率论严密的理论依据,但是它要求给出知识的概率,即使富有经验的领域专家也难以直接给出,因此使其应用受到了限制。基于可信度的不确定推理是E.H. Hortliffe等人在确定性理论的基础上提出的一种不确定推理方法,并首先在MYCIN中得到了成功的应用。
如果用信任度MB(h,e)表示证据e出现时,对结论h成立的信任程度的增加量,用不信任度MD(h,e)表示证据e出现时,对结论h成立的不信任程度的增加量,那么可信度CF(h,e)的计算公式为:
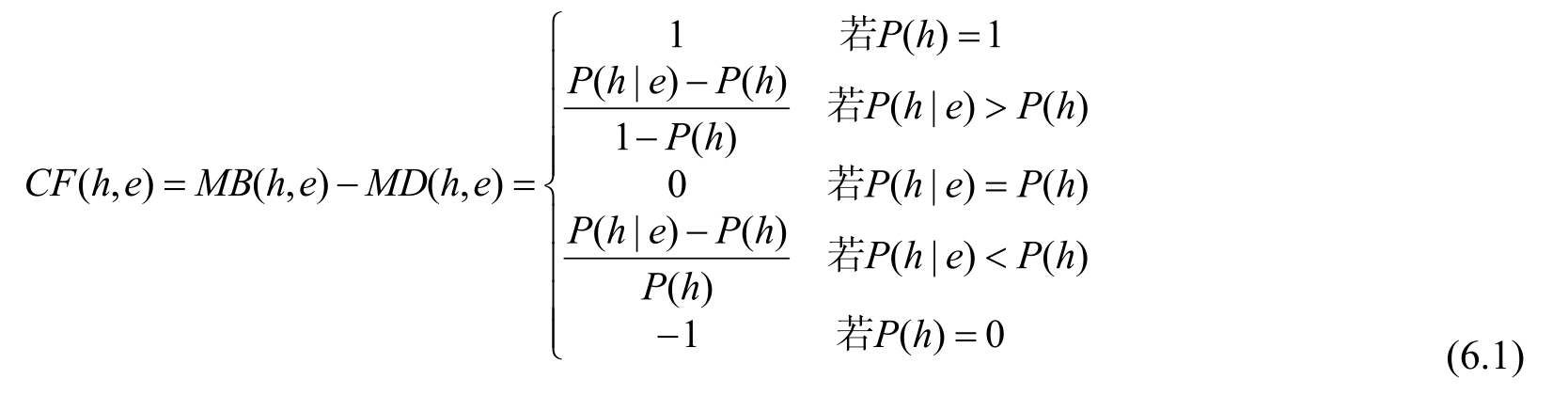
当已知)(hP和)|(ehP时,通过公式6.1就可以计算出CF(h,e)。但是,在实际应用中,获得)(hP和)|(ehP的值是比较困难的,相反,如果设定一定的规则,CF(h,e)的值反而比较容易通过领域专家给出。设定CF(h,e)的值的原则是:若相应证据e能增加结论h为真的可信度,则使CF(h,e)>0,证据e越是支持h为真,就使CF(h,e)的值越大;反之,使CF(h,e)<0,(证据e越是支持h为假,就使),(ehCF的值越小;若证据e与h无关,则使CF(e,h)=0。医学专家根据拥有的专业知识和实践经验,不难对领域知识给出可信度。用可信度表示不确定性知识的方法比较直观、简单,效果也比较好。
(3)基于模糊理论的不确定推理
模糊理论通过隶属度来定义对象x属于模糊集合A的程度,若隶属度越接近于1,则x属于A的程度越大,反之就越小。而模糊规则可以表示为下面的形式:
![]()
其中,E是用模糊命题表示的模糊条件,它既可以是由单个模糊命题表示的简单条件,也可以是由多个模糊命题构成的组合条件;H是用模糊命题表示的模糊结论;CF是模糊规则的可信度因子,它既可以是一个确定的数,也可以是一个模糊数或模糊语言值;λ是规则的阈值,用于指出规则可被使用的限制。
三、机器学习方法
在医学决策支持方法中还有一类重要的方法,就是决策系统智能地从样本中学习和积累经验,再将学习到的知识和经验用于目标问题的解决和推理之中,这就是机器学习方法。机器学习将知识的获取和推理融为了一体,基于机器学习方法构建决策支持系统是未来专家系统发展的必然趋势。一个机器学习的系统模型可以简单地表示为图6.6。其中,环境(Environment)向系统提供学习信息;学习元(Learning unit)对这些信息进行整理、分析、归纳或类比,生成新的知识元或改进知识库的组织结构;执行元(Execution unit)以学习后得到的新知识库为基础,通过一定的推理算法或规则,执行一系列任务,并将执行结果报告学习元,以完成对新知识库的评价,指导进一步的学习工作。
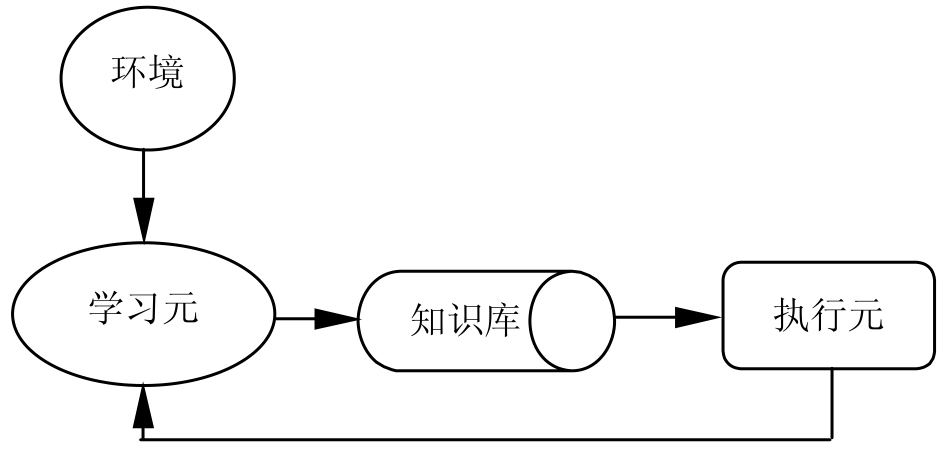
图6.6 机器学习系统模型的框图
机器学习的方法有很多种,而且机器学习的研究正处在发展的高峰时期,各种新思想、新方法和新技术不断涌现,最重要的、应用最多的机器学习方法主要有信息论方法、基于范例的推理、人工神经网络和遗传算法等等,这些方法的详细介绍见第七章相应内容。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









