



5.2.4 关键程序的设计及部分原代码
关键程序的设计及部分原代码见5.2.7节。
1.SJHM系统数据库结构表
本系统所用数据库的结构及数据记录7180条,如表5-1、表5-2所示。
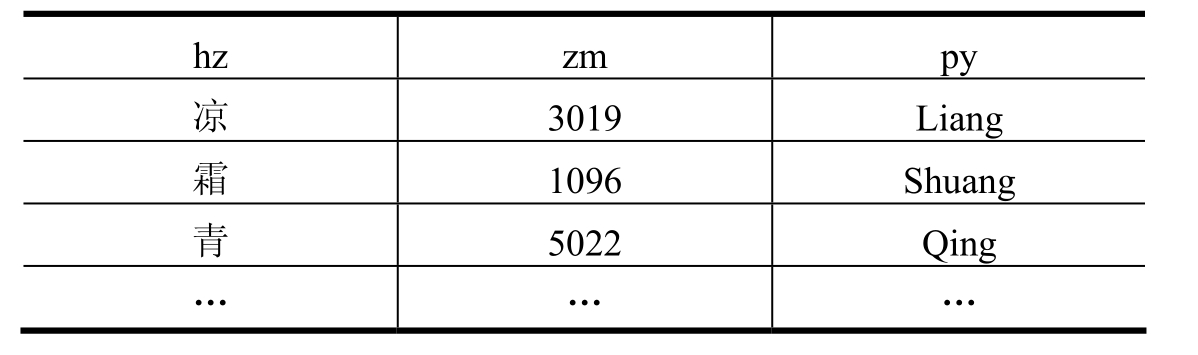
表5-1 Zm_k.dbf数据库结构

表5-2 Zm_k.dbf 字码库
2.“编辑菜单”与“界面”的设计
为使界面美观、使用功能强,特设计了浅色“底纹”的系统界面和“编辑菜单”。


3.文本输入窗口和按钮设计


4.“查找”模块的设计
当点击[查找]键后,系统开始“查找”,并按成都大学图书馆取码规则自动生成著者号,其程序设计如下:


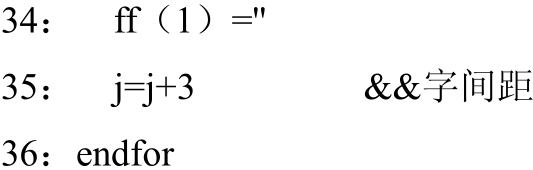
上述第5行与第36行采用了较简洁的计数循环语句。每次循环从第2个字节起,到m个字节结束,步长2。当变量达到m值就结束循环。
5:for m=2 to m step 2
……
36:endfor
第6行采用了功能强大的结构化查询语言SQL(即Structured Query Language的缩写)。比如:
6:select ZM,HZ,PY where HZ=substr(kpw,m-1,2)from \SJHM\S_DBF\ZM_k into ARRAY ff
通过对Zm_k.dbf数据库中的查找,将符合条件记录的各字段,分别追加到ff的数组变量中。即:ff(1)为四角号码(ZM)、ff(2)为汉字(HZ)、ff(3)为拼音(PY)。
本程序中使用的alltrim()和substr()为截取函数,前者用于删除变量中前后的空格;后者用于截取变量中的子串。比如在substr(ff(1),1,2)函数中,1是为ff(1)变量中取字符的起始位置,2为截取ff(1)变量中字符的个数。
程序会严格按照“成都大学图书馆著者号的取码规则”自动提取。①当输入的责任者为一个字时,就先取上方左右角,再取下方左右角,即直接将变量ff(1)存入剪贴板中。②当输入责任者为两个字(单名)时,各取第一、第二字的左右上角。③第10~32行语句,当输入的责任者为三个字时,程序将分别提取第一字左右上角的数字,见第13行,第二、第三字的左上角的数字,见第18、23行,经重新组合(hh),便直接将其存放到剪贴板中,见第24、25行。如:

当编目员输入著者为“郑智星” ,点击“查找”按钮后,在窗口中分别显示“郑(8782)” 、“智(8660)” 、“星(6010)”三字的四角号码和拼音,以及生成的“著者号”为8786,系统将此号自动存入“剪贴板”中,如图5-4所示。
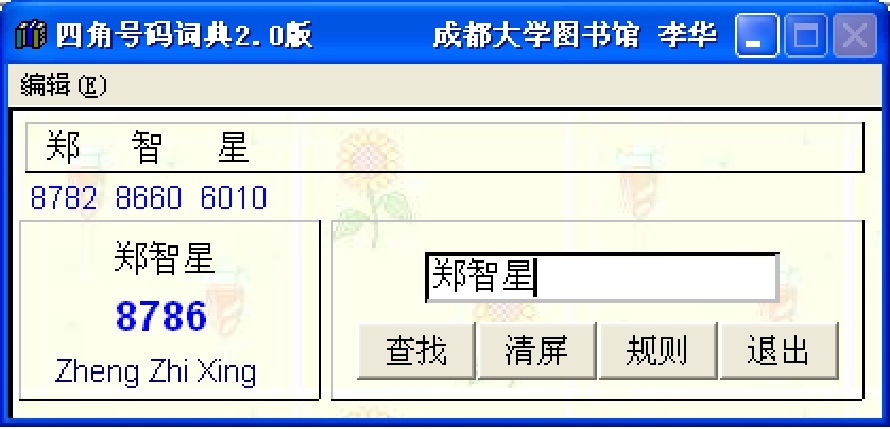
图5-4 生成著者号
在图书馆编目子系统中,如将200字段■f子字段中“刘韬”的著者选定、复制,并粘贴到“四角号码词典”中的著者输入框中,经系统“查找” ,瞬间生成的“著者号”为0252,同时也将该号自动存入剪贴板中,编目员只需在编目子系统905字段■d处,点击“粘贴”即可,如图5-5所示。
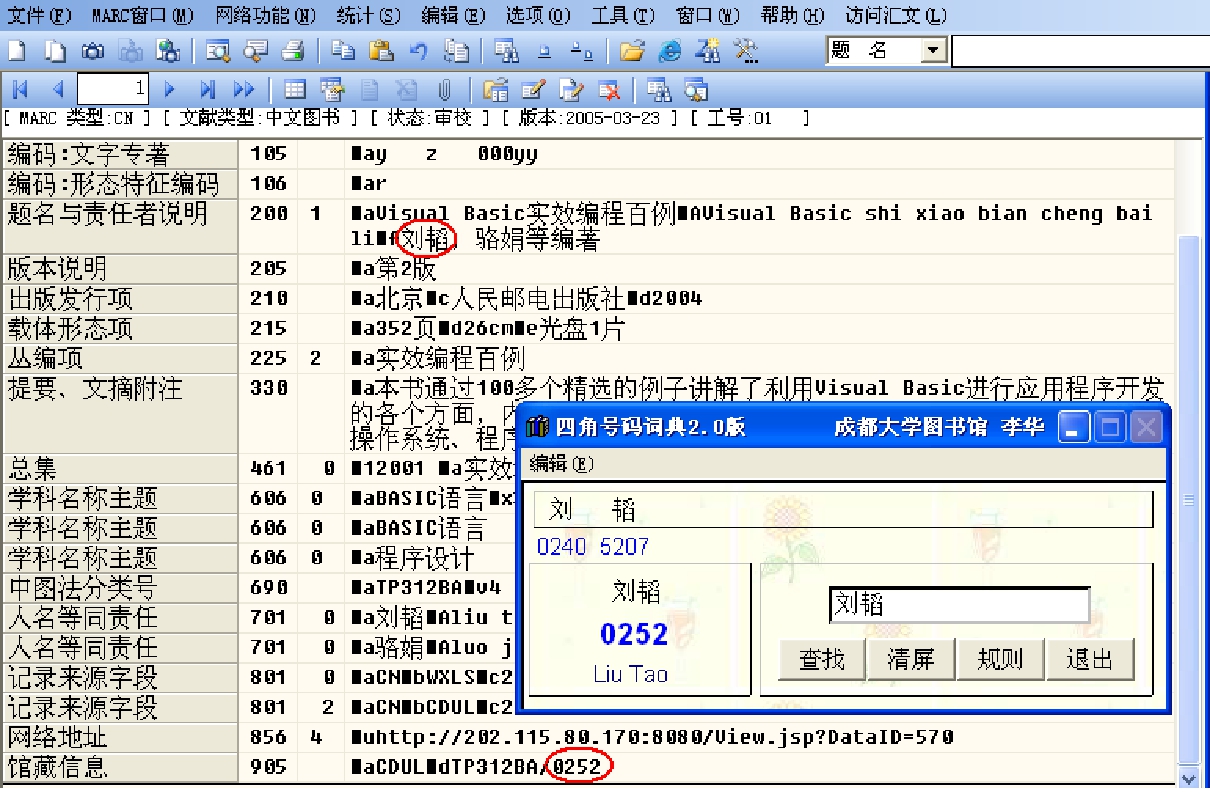
图5-5 在编目子系统中的应用
如果所输入的汉字在4~10个,则著者号就不会生成,只在窗口的上部显示所输汉字的四角号码。即体现词(字)典功能,如图5-6所示。
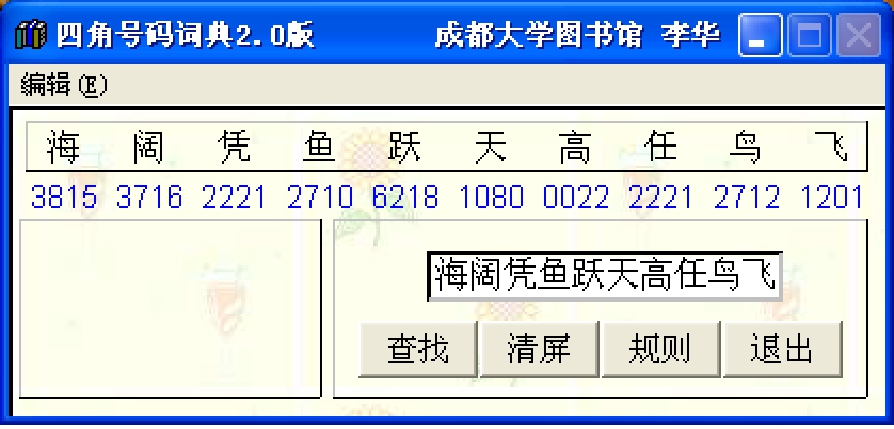
图5-6 四角号码词典功能
为了适应部分编目人员的工作习惯,在不影响使用功能的前提下,特对本系统的“界面”又进行了全面“优化”,使之缩减到只有原系统“界面”的1/3。使用更具人性化、工具化、便捷化,工作效率更高,针对性更强,如图5-7所示。

图5-7 调整后界面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









