



信息抽取技术的分类与展望
陆伟 龙泉
武汉大学信息资源研究中心 武汉 430072
【摘要】由于因特网上不断增加的海量信息资源及信息检索技术的局限性,信息抽取近年来获得了越来越多的关注。信息抽取是一种利用计算机技术在大量结构内容各异的文档中查找所需信息,并以结构化形式存储以实现更有效的数据查询与管理的技术。本文提出了一种信息抽取技术的分类方式,并对各类中有代表性的系统作了简要介绍和比较,指出了目前信息抽取研究领域存在的问题并在此基础上提出了未来发展的建议。
【关键词】信息抽取 分装器 信息检索
The Category and Future of
Information Extraction Technique
Lu WeiLong Quan
Center for Studies of Information Resources,Wuhan University,430072
【Abstract】With the increasingly amount of information on the web and the limitation of information retrieval,the research on information extraction is becoming more and more attractive.It is a technique that searching for the needed information by computer technology,then produces structured information ready for data searching and management.In this paper,we introduce a kind of category for information extraction technique,give a brief survey of some representative systems in each category,compare them using a standard,point out the problems in this area and put forward the suggestion for future development.
【Keywords】Information ExtractionWrapperInformation Retrieval
近年来,随着Internet的发展与普及,Web已成为信息发布和获取的主要场所,有着内容和形式日益多样的海量信息资源,这些资源往往以数字形式隐含在种类丰富复杂的自然语言文本中。如何准确地从这些文本中抽取与任务有关的信息成为研究人员关注的焦点。另一方面,80%的网页通过后台数据库生成(称为隐藏网页)[1],我们通常采用的信息获取方式(如搜索引擎等检索工具)所使用的关键词匹配技术无法从此类网页中获取数据。由于上述问题的存在,为了更好地找到我们需要的信息,必须使用新的检索方法——信息抽取(Information Extraction)。本文将分类介绍多种信息抽取工具,以明确当前信息抽取领域的研究现状、成果、研究热点及发展趋势。
1.信息抽取概况
从自然语言文本中获取结构化信息的研究始于20世纪60年代中期,以两个长期的、研究性的自然语言处理项目——纽约大学的字符串语言项目和耶鲁大学关于语言理解的研究为代表[2];而自动信息抽取技术则是于20世纪80年代才逐渐发展起来。关于信息抽取的概念有多种描述方式,如Eikvil认为信息抽取是把文本里包含的信息进行结构化处理,变成表格一样的组织形式,输入信息抽取系统的是原始文本,输出的是固定格式的信息点;李保利等提到:信息抽取的主要功能是从文本中抽取特定的事实信息……被抽取出来的信息以结构化的形式描述,可以直接存入数据库中,供用户查询以及进一步分析使用。结合多种定义方式,可以得出信息抽取包含的两个主要任务,即抽取所需要的信息和将抽取出的信息以统一标准的格式存储。因此,我们可以将信息抽取定义为:信息抽取是一种利用计算机技术在大量结构内容各异的文档中查找所需信息,并以结构化形式存储以实现更有效的数据查询与管理的技术。
20世纪80年代末以来,信息抽取技术蓬勃发展。这一方面得益于在线和离线文本数量的几何级增加,另一个更重要的方面则是多个国际会议所起到的推动作用,如消息理解会议(Message Understanding Conference,MUC)[3]、自动内容抽取(Automatic Content Extraction,ACE)评测会议[4]、多语言实体任务会议(Multilingual Entity Task Evaluation,MET)以及文档理解会议[5](Document Understanding Conferences,DUC)等。其中,MUC、MET与DUC是由美国国防高级研究计划委员会发起的,MUC之于信息抽取,正如TREC之于信息检索,它的任务主要是建立信息抽取系统的评价指标体系;MET主要针对日语、汉语以及西班牙语等多语种新闻文献进行命名实体抽取;DUC则是一个对“文本概括”进行研究测评的项目。由美国国家标准技术研究所(NIST)组织的ACE主要针对普通文本、由自动语音识别ASR得到的文本和由光学字符识别OCR得到的文本这3种来源的信息进行抽取技术的研究。这些国际会议对于信息抽取的研究内容、信息抽取方式的分类、信息抽取系统的评价等都起到了重要的促进作用。
2.信息抽取技术的分类
根据不同标准,信息抽取技术的分类方式也呈现出多样性。如Siefkes[6]根据抽取方法的不同将信息抽取分为:基于规则学习的方法,基于知识的方法和基于统计的方法;Eikvil根据处理页面的类型将信息抽取系统分为处理结构化、半结构化页面的系统和处理半结构化、非结构化页面的系统;Chia-Hui等[7]则认为信息抽取系统可根据用户与系统的交互方式分为手工构造的、监督下的、半监督的和无监督的系统;Laender[8]根据分装器生成中用到的主要技术将数据抽取工具分为6类,分别是:分装器开发语言,针对HTML页面的工具,基于自然语言处理的工具,分装器归纳工具,基于模型的工具和基于本体的工具。
根据抽取原理的不同,本文将信息抽取分为基于规则的信息抽取,基于统计的信息抽取和多策略混合方法3大类,并对各类方法中有代表性的系统进行介绍。
2.1基于规则的信息抽取
基于规则的信息抽取侧重于系统对抽取规则的学习。由于规则学习主要由分装器来解决,因此,该方法也可以看作是基于分装器的信息抽取。分装器是一种软件构件,负责将隐含在HTML等文档中的信息提取出来,并转换成能够被进一步处理的以某种数据结构存储的数据[9]。一个分装器只能处理一种特定信息源,如果要从多个信息源中抽取信息,则需要建立一系列分装器程序库。由于自动化程度的差异,构造分装器有两种方式,即基于知识工程的途径和采用机器学习的途径。基于知识工程的方法由各领域专家针对特定信息源手工编写抽取规则,这种方法不仅需要较高的专业技巧,而且费时费力、易于出错,不能适应处理对象所属领域的变化;采用机器学习的方法则主要通过学习已经标记好的样本来获取规则。当遇到新的Web页面时,抽取规则与页面文本进行匹配,然后抽取出相应的数据片段。这种方法要比知识工程方法快,且不需要非常专业的规则编写人员,但只有拥有足够数量的训练数据才能保证其处理质量。
下面将规则学习方法细分为关系学习方法,半自动的抽取方法,手工构造分装器的方法,全自动的抽取方法和针对HTML页面的信息抽取方法,重点介绍其中的常用方法。
2.1.1关系学习方法
关系学习可以分为自顶向下和自底向上的算法两类。其中,自顶向下的算法由最一般的常识性规则开始,通过引入反例,修改规则,使规则逐步精确;而自底向上的算法首先选择一个初始的训练集,然后产生能够覆盖这些训练集的规则,然后逐步对这个规则进行修改,使之能够覆盖其他的训练实例。关系学习方法是规则学习中重要的一类,能比大多数其他的规则学习和统计方法获得涵盖更多及更灵活的文本的有效关系规则。
WHISK[10]采用了关系学习方法中的自顶向下算法且融合了主动学习算法,事先只需要用户对一小部分实例进行标注,能处理结构化、半结构化文本及自由文本,是一种非常灵活的信息抽取方法,其目标是实现句子层上的多槽抽取。在进行信息抽取时,系统首先找到一个最宽泛的能覆盖实例的种子规则,然后一次加一个条件,直到错误率为零,或者满足一个事先设定的标准为止。学习过程一直进行,直到能覆盖所有该被覆盖的抽取字串,最后把那些过适规则删除掉。训练实例上的标记将指导抽取规则的生成,并且检验规则的效果。如果规则被成功应用到一个实例上,那么该实例则被认为被规则“覆盖”了。如果抽取出来的词组与实例上的标记吻合,则认为该词组的抽取是正确的。
除了WHISK之外,SRV(Sequence Rules with Validation)[11],Rapier(RobustAutomatedProductionofInformationExtraction Rules)[12][13]等也采取了关系学习方法来进行信息抽取,不同点在于SRV和Rapier操作的对象是整个文档。
2.1.2半自动的信息抽取
半自动的信息抽取在一定程度上需要人工参与,IEPAD[14]、OLERA、NoDose[15]和DEByE[16]等系统均属于此类,这些系统各有其优势及缺陷。
IEPAD[17]是最早从未标记的Web页面中归纳抽取模式的信息抽取系统之一,采用了称为PAT树的数据结构,能够通过发现重复模式解决分装器学习的问题。但不足之处在于,IEPAD只能从多个数据记录中进行规则的学习。OLERA解决了IEPAD只能处理多个数据记录的问题,能够从包含单一数据记录的页面中学习抽取规则,而它只能从用户处获取粗糙实例。NoDose和DEByE是基于模型的信息抽取工具。采用该方法进行信息抽取时,需要为感兴趣的对象定义原型目标结构,在网页中为符合该结构的内容定位。NoDose采用图形用户界面,用户可以将文档按层次分解,列出感兴趣的部分并描述其语义,但用户必须将以自上而下的方式分离整个文档。DEByE也为分装器生成提供了交互式图形用户界面。与NoDose不同的是,用户使用DEByE时只需标记出原子(属性)值用以组织嵌套表格,同时,DEByE采用了属性配对模型(Attribute Value Pair patterns,AVPs)将原子抽取出来并存储到嵌套对象中。
2.1.3手工分装器构造的信息抽取
TSIMMIS[18]是最早为人工构造Web分装器提供框架的方法之一。其目标是以一体化的方式获取不同信息源的信息并保证所获取信息的一致性。该方法的核心是一个分装器,输入分装器的是一个说明文档,该文档根据程序员的指令序列声明了所需数据在页面中的位置及如何将数据包装到目标对象中。在进行数据抽取时,由基于说明文档的抽取器对HTML文档进行解析来定位并抽取数据,之后,TSIMMIS以包含了数据、结构信息和结果目录的对象交换模型(Object Exchange Model)输出数据。
Minerva[19]也是一种人工构造的信息抽取系统,由用户为每个Web站点编写分装器程序。编程语言可以是perl,java或其他为特定任务设计的语言。由于采用这种类型的信息抽取工具需要用户有丰富的计算机及编程知识,因此成本也相对较高。
由Brigham Yong University开发的BYU系统[20]建立在由专家手工构造的本体的基础上,通过对预先定义的本体的解析,系统能抽取并组织输入文档或页面中的数据以自动产生数据库。通过这种方法产生的分装器灵活且适应性强,能在页面结构发生变化的情况下继续工作,并能处理同一领域多种来源的信息。
2.1.4基于分装器归纳的信息抽取
分装器归纳法是采用机器学习生成分装器方法中比较有效的一种。采用这种方法时,分装器生成被描述为一种归纳学习问题,可以看作对现象的一种概括。如果归纳出的规则能解释观察到的实例,或者在新实例出现时能做出准确的预测,那么,这种归纳就是成功的。
由Kushmerick开发的WIEN(Wrapper Induction Environment)[21]是最早且最有影响力的分装器归纳工具,也是分装器归纳的术语第一次被提出。该方法不只局限于某一领域,也不只适用于HTML文本,而是适用于所有包含表格结构信息的文本。WIEN主要针对具有HLRT结构,即头分隔符、左右分隔符(每个待抽取事实的左右)和尾分隔符的页面,在输入标记好目标数据的实例页面后,系统将上述分隔符与“HLRT分装器模型”定义的分装器空间中的分隔符进行匹配,直到找到一个与标记页面一致的分装器。WIEN的缺陷在于,其所产生的分装器无法处理嵌套结构或半结构化数据的变化。
除WIEN之外,SoftMealy[22]、STALKER[23]、BWI(Boosted Wrapper Induction)[24]等也是有代表性的分装器归纳系统,有兴趣的读者可以阅读相关参考文献。
2.1.5针对HTML页面的信息抽取工具
针对HTML页面的抽取工具主要利用HTML文档的结构特征完成数据抽取任务。在进行抽取前,抽取工具将文档转化为表现HTML层次结构的解析树,之后由系统自动或半自动产生抽取规则并应用到解析树。采用这种方法的比较有代表性的系统是W4F(The World Wide Web Wrapper Factory)[25]。W4F将分装器生成过程分为3个阶段:描述如何获取文档;描述需要抽取哪些数据;声明存储数据的目标结构。每个阶段都需要用户的参与。当解析树构造完成后,用户可以通过W4F提供的图形化向导编写抽取规则,以便在解析树的各个节点中定位并抽取数据。这里需要指出的是,W4F同时也是半自动的信息抽取系统,由于其对HTML页面的针对性颇具代表性,因此在这一节单独介绍。
2.1.6非监督学习(全自动)方法
全自动的信息抽取是在没有人工介入和训练的情况下实施的。Nikolaos等[26]提出了一个全自动的框架STAVIES来构造通用分装器,使信息抽取系统能在不考虑页面结构的条件下用于任何类型信息的抽取。该系统由转换模块和抽取模块组成,抽取模块用于为由页面生成的树形结构中的信息定位,转换模块将树中被选择的节点映射到初始HTML文档的元素上。Omini[27]也是一个全自动的抽取系统,它将页面解析为树形结构,并采用子树抽取算法为包含了用户感兴趣的对象的最小子树定位。采用这种方法,不仅能抽取出相邻的数据记录,还能抽取页面中不相邻的数据记录。
2.2基于概率的信息抽取
概念理论是为了提高推理的准确性而引入的,基于概率的信息抽取更多的利用了文本的语义信息和自然语言处理技巧,现在越来越多的研究将概率机器学习引入到了信息抽取领域。
最早由Judea Pearl于1988年提出的贝叶斯网络(Bayesian Network)实质上就是一种基于概率的不确定性推理网络,它是用来表示变量集合连接概率的图形模型,提供了一种表示因果信息的方法。BIEN(Bayesian Information Extraction Network)是利用贝叶斯网络进行信息抽取的方法。在预处理阶段,系统对词语进行词干提取和词性标注,并将句子分离为扁平句法单元(名词,动词或其他短语)。如果需要其他的限定条件,则可以通过字长、地名标识符等地名辞典提供。
隐马尔可夫模型(Hidden Markov Model,HMM)提供了一种基于训练数据的概率自动构造识别系统的技术。该模型易于建立,不需大规模的词典集与规则集,且适应性好,抽取精度高。Freitag等[28]提出了利用每个空槽的内部结构、前缀和后缀为每个被抽取的目标空槽手工构造独立HMM的方法,利用了HMM在序列问题抽取上的优势。
条件随机域模型(Conditional Random Fields)是另一种条件概率有限状态模型。它能使用不同类型的特征为观察到的数据建模,通过训练,根据输入的不标准转换概率实现最大条件概率的输出。如McCallum&Jensen[29]提出的可用于信息抽取和数据挖掘的一组标准概率模型—抽取-挖掘随机域。该方法主要用于处理相关数据,允许自下而上的信息抽取或自上而下的数据挖掘,且能通过比较中间结果同时改进两种操作的准确度。
2.3多策略混合方法
当采用单一方法进行信息抽取时,系统通常只考虑文档的某一个方面,如HTML标签,词典信息。这就使得在对某些类型的文档进行操作时产生不适应的情况。为尽量避免上述问题的发生,研究人员尝试将多种抽取方法混合起来。如IE2[30]在解决共指消解问题时采用了简单的手工规则编写及决策树算法这两种不同的策略,将决策树算法作用于由手工编写规则抽取出的侯选结果的子集;TEG(trainable extraction grammar)[31]是一种基于统计的机器学习和知识库的信息抽取的混合模型,它能够在句子层抽取实体和关系,通过从练习集中得到的统计来显著减少人力劳动的数量,从而保持并改进知识库系统的高精确水平,可以用于任何信息抽取领域。
2.4信息抽取系统比较
本节选取了几个重要的评价指标,对上文所介绍的信息抽取系统的性能进行了比较分析。这几种指标分别是:系统自动化程度;系统所能处理的页面类型;抽取规则的类型;采用的学习算法。
(1)手工构造的信息抽取系统(BYU、TSIMMIS、Minerva等)由专家来编写抽取规则,需要较高的专业技巧;半自动的信息抽取系统(NoDosE、DEByE、W4F等)由用户准确或大致标记出待抽取的数据,不需要专家支持;全自动的信息抽取系统(Omini)除了选择合适的抽取模式之外,不需要用户参与。手工与半自动信息抽取系统比较(如表1所示)。
表1 手工与自动信息抽取系统比较表
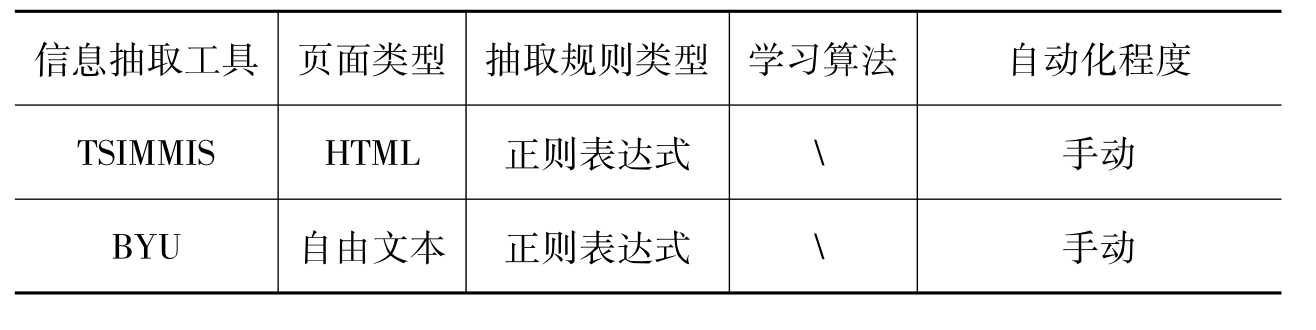
(2)从页面类型来看,根据结构化程度的不同,页面文本主要有3种组织形式,分别为:自由文本,半结构化文本和结构化文本。大多数手工构造或半自动的抽取系统(如Softmealy,SRV,WHISK,TSIMMIS等)对页面结构的限制不多,能够根据字串特征来产生抽取规则,可以处理多种页面的信息抽取。而全自动的抽取系统(如Omini)则主要针对模板页面的抽取,主要利用通用的页面结构模板,难以扩展到对自由文本的处理。W4F等针对HTML页面的抽取系统很大程度上依赖于DOM树的应用,因此,只适用于HTML页面。
(3)在半结构化尤其是模板页面中,我们通常都能在待抽取的信息周围找到通用字串,因此,大多数面向这类页面的信息抽取系统(如WIEN,W4F,SoftMealy,TSIMMIS等)都通过正则表达式规则来识别相关信息的起始和结束位置。当输入的信息为自由文本时,很难找到通用字串,这时就需要结合更多特征,如词性标签和词长。因此,一阶逻辑规则被用在了自由文本的信息抽取中(如SRV和Rapier)信息抽取系统比较(如表2所示)。
表2 信息抽取系统比较表
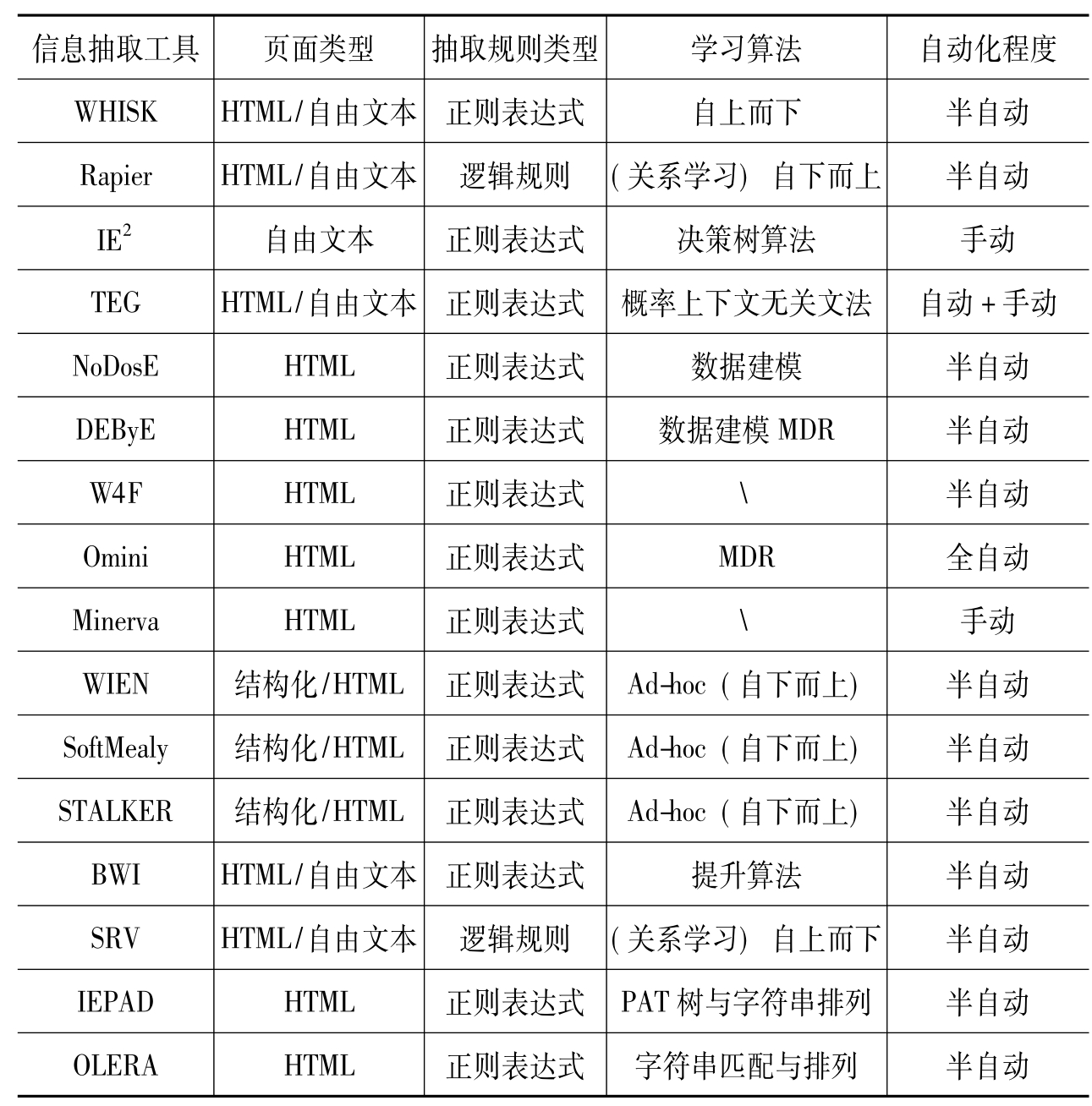
(4)手工构造的信息抽取系统由人工编写程序,明确表示了页面中的数据位置及包装数据的方式,因此不需要学习算法。WHISK,SRV和RAPIER采用了关系学习算法,能识别出待抽取信息的上下文及限制符;DEByE和NoDosE需要用户的参与,主要工作集中在用户接口的设计,抽取规则的学习十分简单,如对所需信息前缀和后缀的识别;STALKER、SoftMealy、WIEN采用了Ad-hoc归纳方法来进行规则学习,与DEByE和NoDosE不同,它们关注于规则学习技术和抽取器的结构;半自动或全自动的抽取系统主要采用数据挖掘技术来实现模式查找,如IEPAD使用的PAT树技术和字符串排列技术,OLERA使用的近似字符串匹配技术。
3.信息抽取技术展望
上一节我们对目前典型的信息抽取技术作了分类介绍,接下来将从不同角度探讨信息抽取技术存在的问题及发展方向。
(1)构造可适应性信息抽取系统
目前的信息抽取大多依赖于对应特定信息源的抽取规则或分装器,不能适应文档结构的变化,一个有效的信息抽取系统必须能解释形式各异的HTML页面且不间断地适应变化;识别各种页面结构且根据知识对信息抽取技术进行改进;实现各种领域及数据对象类型的用户化。上文提到的WIEN、WHISK等系统在构造分装器上均采用了机器学习方法,增强了系统对新领域的适应性、对错误产生时的可修复性及易维护性。另一方面,我们也必须认识到,尽管Web服务为数据交换和信息整合提供了另一种方式,但它们始终需要程序人员的参与,无法避免编程和标注等工作消耗的劳动力。因此,只要提供了合适的特征,手工编写规则的系统(如TSIMMIS、Minerva、BYU等)还是能够处理各种输入信息。
(2)面向语义的信息抽取系统
随着语义网的发展,跨站点的信息抽取将显得愈发重要,我们需要以某种方式将结构化与非结构化信息集成。在本文介绍的系统中,WHISK、WIEN等能够处理多种文本,TSIMMIS、IEPAD、No-DosE、DEByE、W4F等系统只针对HTML文本,而IE2只能处理自由文本。因此,如何将各种系统的特征互相整合,结合基于统计的抽取方法在利用语义信息方面的优势,是未来的一个研究方向。
(3)以XML的格式输出信息
KUSHMERICK[32]等提出,大多数互联网信息都是以HTML的形式存在,通过浏览器供我们使用。而在很多情况下,这些页面不具有良好的格式,从这些文档中抽取数据无异于非结构化文档的抽取任务。在未来,大多数网页内容都将以XML的格式存储,这种格式对不兼容的系统间的数据交换起到了重要作用,使终端用户和应用程序能自动处理更多的Web页面。因此,关于HTML到XML的转化的研究值得我们给予更大的关注。
(4)与信息检索相结合
信息抽取与信息检索在目标及使用的技术方面存在着差异。信息抽取的目标是从大量文档中找到所需要的信息并以结构化形式表现,主要采用了文本处理和基于规则的处理方法;而信息检索的目标则是从文档集合中找到相关文档,通常利用统计及关键词匹配等技术,不需要对文本进行深入分析理解。两者的互补与结合能构造出更强大的文本处理工具。
4.结论
这篇论文介绍了信息抽取的基本知识,将信息抽取方法分为基于规则的信息抽取、基于统计的信息抽取和多策略混合方法3类,描述了其中较有代表性的系统,并从4个方面进行比较,分析了信息抽取系统的自动化程度、可以处理的页面类型、采用的抽取规则及学习算法,最后提出存在的问题及未来的发展方向:未来的信息抽取系统应该是与信息检索技术相结合、具有更强适应性的、面向语义及XML的系统。
【参考文献】
[1]Lawrence S,Giles C.L.Searching the World Wide Web[J].Science,1998,280(4):98-100.
[2]Gaizauskas R,Wilks Y.Information Extraction:beyond Document Retrieval[J].Journal of Documentation,1997.
[3]Hammer J,McHugh J.Garcia-Molina.Semi-structured Data:the TSIMMIS Experience[C].In Proceedings of the 1stEast-European Symposium on Advances in Databases and Information Systems(ADBIS),St.Petersburg,Rusia,1997.
[4]Automatic Content Extroction(Ace)Evaluation[EB/OL].[2007-12-08].http://www.itl.nist.gov/iad/894.01/tests/ace/.
[5]Document Understanding Conferences[EB/OL].[2007-17-28].http://duc.nist.gov/.
[6]Christian Siefkes,Peter Siniakov.An Overview and Classification of Adaptive Approaches to Information Extraction[J].Data Semantics,2005,Vol.4(172-212).
[7]Chia-Hui Chang,Mohammed Kayed,Moheb Ramzy Girgis,Khaled Shaalan.A Survey of Web Information Extraction Systems[J].Knowledge and Data Engineering,2006(10):1411-1428.
[8]Alberto H.F.Laender,Berthier A.Ribeiro-Neto.A Brief Survey of Web Data Extraction Tools[J].ACM SIGMOD Record,2002,31(2).
[9]Wiederhold G.Mediators in the Architecture of Future Information Systems[J].IEEE Computer,1992,25(3):38-49.
[10]S.Soderland.Learning Information Extraction Rules for Semistructured and Free Text[M].Machine Learning,1999.
[11]Freitag D.Information Extraction from HTML:Application of a General Learning Approach[C].In Proceedings of the Fifteenth Conference on Artificial Intelligence(AAAI-98):517-523.
[12]M.E.Califf,R.J.Mooney.Relational Learning of Patternmatch Rules for Information Extraction[C].In Proceedings of the ACL Workshop on Natural Language Learning,1997.
[13]M.E.Califf.Relational Learning Techniques for Natural Language Information Extraction[D].Ph.D.thesis,Department of Computer Sciences,University of Texas,Austin,August 1998.Technical Report AI98-276.
[14]Chang C.H,Lui S.C.IEPAD:Information Extraction Based on Pattern Discovery[C].Proceedings of the Tenth International Conference on World Wide Web(WWW),HongKong,2001: 223-231.
[15]同[13].
[16]Laender A.H.F,Ribeiro-Neto B,DA Silva A.S.DEByE-Data Extraction by Example[J].Data and Knowledge Engineering,2002,40(2):121-154.
[17]同[14].
[18]Hammer J.McHugh,Garcia-Molina.Semi-structured Dat:the TSIMMIS Experience[C].In Proceedings of the 1stEast-European Symposium on Advances in Databases and Information Systems(ADBIS),St.Petersburg,Rusia,1997.
[19]Crescenzi V,Mecca G.Grammars Have Exceptions[J].Information Systems,1998,23(8):539-565.
[20]Embley D,Canpbell D,Jiang S,et al.Conceptual-modelbased Data Extraction from Multiple Record Web Pages[J].Data and Knowledge Engineering,1999,31(3):227-251.
[21]Kshmerick N.Wrapper Induction:Efficiency and Expressiveness[J].Artificial Intelligence Journal,2000,118(1/2):1568.
[22]Hsu C.N,Dung M.T.Generating Finite-state Transducers for Semi-structures Data Extraction from the Web[J].Information Systems,1998,23(8):521-538.
[23]I.Muslea,S.Minton,C.A.Knoblock.Hierarchical Wrapper Induction for Semistructured Information Sources[J].Autonomous Agents and Multi-Agent Systems,2001,4(1/2):93-114.
[24]Freitag D,Kushmerick N.Boosted Wrapper Induction[C].In Processings of the Seventeenth National Conference on Artificial Intelligence.
[25]同[23].
[26]Nikolaos K,Papadakis,Dimitrios Skoutas,Konstantinos Raftopoulos,Theodora A.Varvarigou.STAVIES:a System for Information Extraction from Unknown Web Data Sources through Automatic Web Wrapper Generation Using Clustering Techniques[J].Knowledge and Data Engineering,2005,17(12): 1638-1652.
[27]D.Buttler,L.Liu,C.Pu.A Fully Automated Object Extraction System for the World Wide Web[C].In Processings of 2001 Int'l Conf.Distributed Computing Systems(ICDCS'01),2001: 361-370.
[28]D.Freitag,A.L.McCallum.Information Extraction Using HMMs and Shrinkage[C].In Processings of the 16thNational Conf on Artificial Intelligence,1993:31-36.
[29]Lafferty J,Mccallum A,Pereira F.Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C].In Proceedings of the 18thInternational Conference on Machine Learning(ICML),2001.
[30]C.Aone,L.Halverson,T.Hampton,M.Ramos-Santacruz.SRA: Description of the IE2System Used for MUC[C].In Proceedings of the Seventh Message Understanding Conference(MUC-7),1998.
[31]Benjamin Rosenfeld,Ronen Feldman,Moshe Fre-.Sko.TEG—a Hybrid Approach to Information Extraction[M].ACM,2004.
[32]Kushmerick N.Wrapper Induction:Efficiency and Expressiveness[J].Artificial Intelligence Journal,2000,118(1/2):1568.
【作者简介】

陆伟,男,1974年生,博士,副教授,武汉大学信息资源研究中心专职研究员。1992年考入武汉大学科技情报专业,2002年毕业获情报学博士学位并留校从事教学科研工作。2005年3月至2006年8月被国家留学基金委公派访学英国伦敦城市大学从事XML检索博士后研究工作。近年先后在国内外发表论文30余篇,参与编著3部。曾主持国家社科基金等纵向项目3项,参加并实际负责大型纵横向项目多个。目前主要研究方向为半结构化多媒体信息检索、Web智能挖掘、专家检索、数字图书馆等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












