



中文文本分类与框架分析
张李义 张前磊
武汉大学信息资源研究中心 武汉 430072
电子科技大学图书馆 成都 610054
【摘要】文本分类作为处理和组织大量文本数据的关键技术,可以在较大程度上解决信息无序的问题,方便用户准确地定位所需的信息,近年来得到了学术界广泛和深入的研究。本文首先对中文文本分类领域进行了细致的需求分析,探讨了软件体系结构的模式及其在文本分类框架中的应用,重点介绍GoF设计模式在框架中的应用。
【关键词】文本分类 设计模式 机器学习
Text categorization and
framework analysis
Zhang LiyiZhang Qianlei
Center for Studies of Information Resources of Wuhan University,Wuhan,430072 Library of university of electronic science and technology of China,Chengdu,610054
【Abstract】As a key technology of processing and organizing large scale text information,text categorization provides a solution to the problem of information disorder and helps users to locate the information they want accurately.Currently,text categorization has become an active research field.Firstly,this paper gives a delicate requirement analysis for the Chinese text categorization fields,especially in the domain analysis field.Then,it analyzes the patterns of software system architecture and describes the application of GoF design mode in the text categorization field.
【Keywords】Text CategorizationDesign PatternsMachine Learning
信息技术的高速发展使人类社会的信息量成指数级增长,而在这些数字信息中,文本形式的信息占有极其重要的地位。如何有效地组织和管理这些信息,并快速、准确、全面地从中找到用户所需要的信息是当前信息科技领域面临的一大挑战。
文本分类作为处理和组织大量文本数据的关键技术,可以在较大程度上解决信息无序的问题,方便用户准确地定位所需的信息和分流信息。文本分类已成为信息过滤、信息检索、搜索引擎、文本数据库、数字图书馆等领域的技术基础,有着广泛的应用前景。因此,文本分类已作为一项具有很大实用价值的关键技术,得到了国内外研究人员的广泛关注,也取得了很大进展。
文本分类研究的难点在于研制一些关键的算法,如文本表示中的权重计算方法,特征选择算法,特征抽取算法,机器学习算法及分类器的设计等,当前文本分类方面的研究也主要集中于这些算法的研制上。当研究人员设计了一个新的算法后,为了实验新的算法并评估新算法的性能,往往需要设计和实现一个完整的文本分类系统,其工作量是巨大的但却并非必要的,因为不同的文本分类系统之间存在着许多共同的需求和相似的结构,多个研究人员在设计和实现文本分类系统的工作中可能很大一部分都是重复性的,比如两个研究特征选择算法的研究人员所做的文本分类系统可能除了特征选择部分以外其他部分的代码的功能都是相同的。这种重复性的工作消耗了研究人员大量的时间和精力,使他们无法将更多的精力投入到实质性的问题上。
因此,本文将从可复用系统设计的角度来研究文本分类的问题,研究重点和目标不在于改进文本分类某一个步骤的算法,而是构建一个中文文本分类框架,以改变目前文本分类研究人员构建实验系统的方式,使文本分类的研究人员不必为了实验一个新的算法而从头设计和实现一个文本分类系统,而只需对框架进行扩展和配置即可。同时,也可以使应用系统开发人员不必深入地理解文本分类的原理和算法而快速地将文本分类功能集成到系统中。
1.国内外研究现状
20世纪90年代以来,信息技术的迅猛发展,以及大量计算机可读形式的文字信息的急剧增加,为基于机器学习的文本分类方法准备了充分的资源。在这种情况下,基于机器学习的文本分类逐渐取代了基于知识工程的方法,成为文本分类的主流技术。基于机器学习的文本分类,需要将文本表示为易于被计算机处理的形式,目前主要利用向量空间模型(Vector Space Model)。在向量空间模型的基础上,国内外的研究人员对文本分类关键算法,如文本表示中的权重计算方法、特征选择算法、特征抽取算法和机器学习算法等进行了大量的研究并取得了可观的成果,其中许多研究成果都已投入实际应用。另外,在分类器的设计上和对文本分类系统的性能评估问题上也有大量研究成果。
考虑到文本分类特征空间的高维性和文档向量的稀疏性对分类效率的影响,在文本分类中,常用的特征降维方法有两类,一类是特征选择(Feature Selection),它是基于阈值的统计方法,如特征频度(Term Frequency)[1]、文档频率方法(Document Frequency)[2]、信息增益方法(Information Gain)[3]、互信息方法(Mutual Information)[4]、相关系数(Correlation Coefficient)[5]、CHI方法[6]、期望交叉熵(Expected Cross Entropy)[7]、文本证据权(Weight of Evidence for Text)[8]等;另一类是特征抽取(Feature Extraction),由原始的特征空间经过某种变换构建正交空间中的新特征的方法,如主分量分析方法[9]和潜在语义索引方法[10]等。基于阈值的统计方法具有计算复杂度低,速度快的特点,尤其适合做文本分类中的特征降维[11]。文本分类的另一个研究热点是分类器的设计及相应的机器学习算法。现在广泛应用的基于向量空间表示和统计学的分类算法包括Naive Bayes法、Rocchio法、KNN方法、决策树、神经网络法、支持向量机(SVM)法、基于投票的方法等[12]。
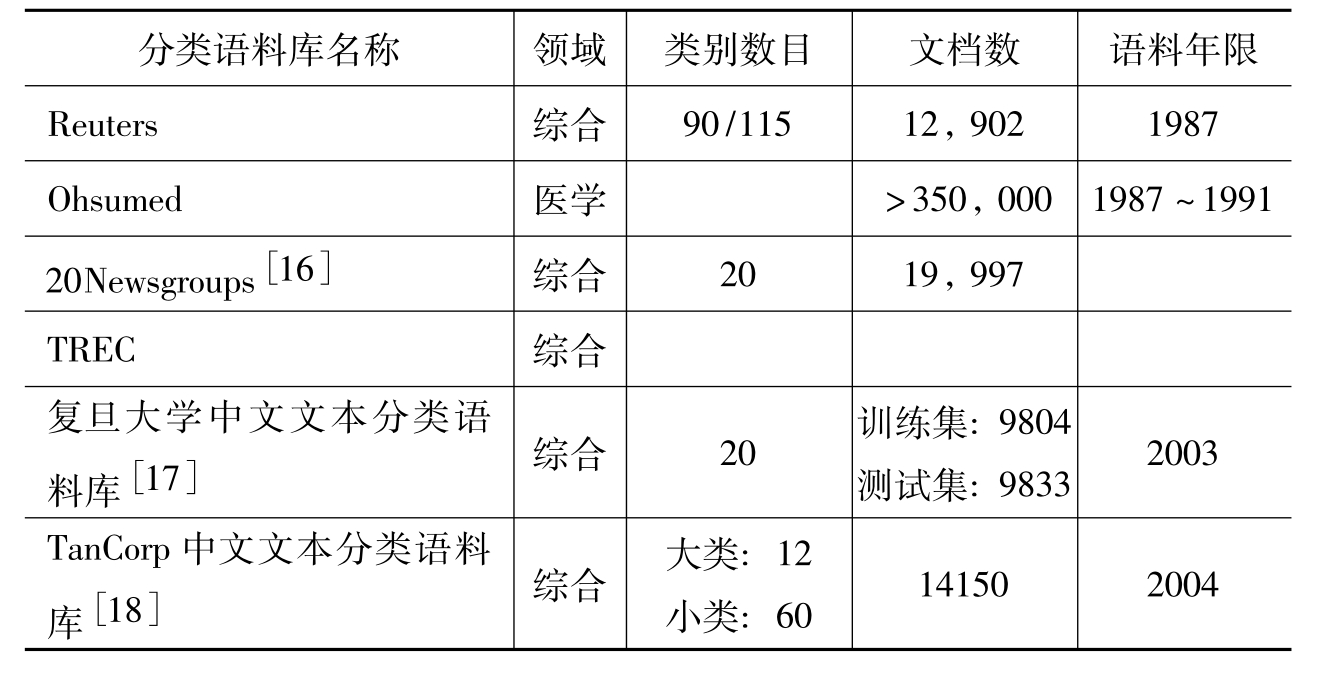
国内从20世纪90年代中期开始文本分类领域的研究,复旦大学和中科院计算所对TREC测试中的分类任务进行了长时间的跟踪和研究,北京大学和清华大学较早在搜索引擎“天网”和“网络指南针”上研究网页分类技术。国内在文本分类的研究上明显的不足之处是缺乏公认的权威的分类语料库。对于文本分类实验来说,分类语料库的选择是非常重要的。在英文文本分类方面,有Reuters[13],TREC(Text Retrieval Conference)[14],Ohsumed[15]等一些标准权威的分类语料库。而在中文文本分类方面,目前还没有一个公认的权威的分类语料库。国内的研究人员很多都是自行收集文档建立语料库并进行实验,这样做一方面要消耗不少精力,另一方面这样得到的结果很难与其他同行的结果进行比较。表1列出了国内外典型的分类语料库。
表1 分类语料库
在应用系统框架的设计方面,软件工程学界已经积累了大量的实践经验,并有诸多专著论述,其中一个共同点就是强调设计模式在框架设计中的应用,因为一个使用设计模式的框架比不用设计模式的框架更可能获得高层次的设计复用和代码复用。成熟的框架通常使用了多种设计模式,设计模式有助于获得无须重新设计就可适用于多种应用的框架体系结构。
另外,框架的设计强调松散耦合的重要性,因为框架规定了应用的体系结构,应用的设计便依赖于框架,所以应用对框架接口的变化是极其敏感的。当框架演化时,应用不得不随之变化,这使得松散耦合变得重要,否则框架的细微变化都会引起应用系统的大的修改。
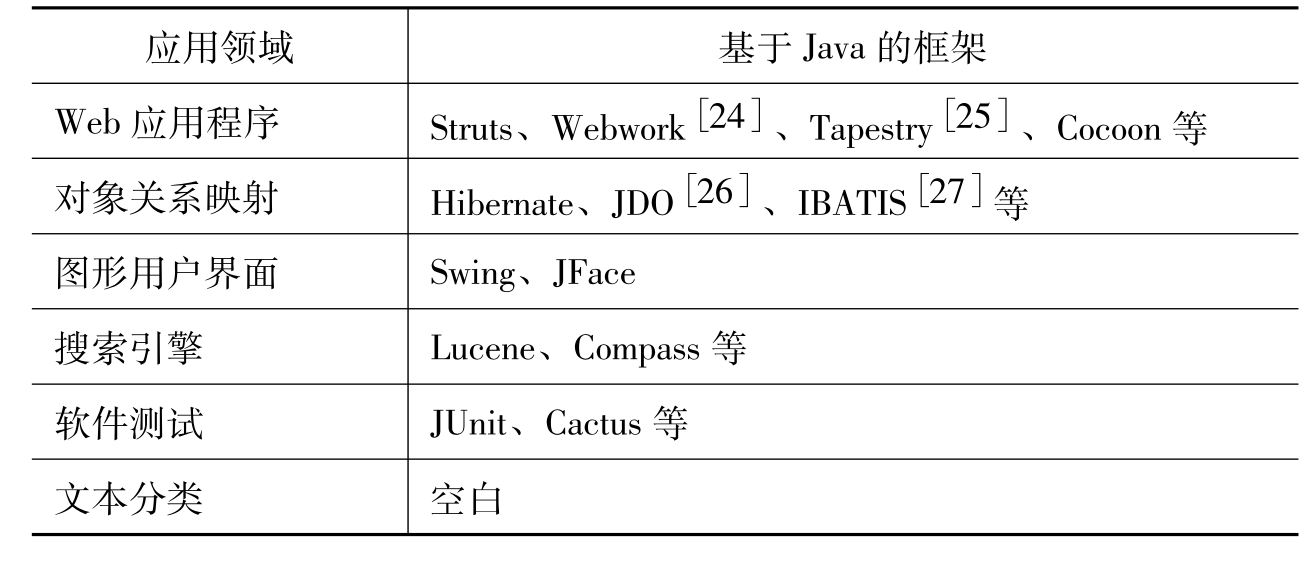
在Java开发社区,优秀的应用系统框架层出不穷,在Web开发方面有Struts[19],在对象关系映射方面有Hibernate[20],在单元测试方面有JUnit[21],在图形界面编程方面有JFace[22],在全文检索方面有Lucene[23],等等。但是,在文本分类方面,却没有相应的框架。表2列出了基于Java的一些典型的框架。
表2 基于Java的应用系统框架
对于文本分类框架,国内尚无相关文章论述,国外也只有少量的研究工作及成果,如澳大利亚悉尼大学开发的AICategorizer,它是一个基于Perl语言的文本分类框架。新西兰Waikato大学开发的Weka,是一个基于Java的数据挖掘开源软件,包含了一些机器学习算法和模式分类算法。此外,国外的研究人员开发了一些与分类相关的工具箱或程序库,其中一些是用Java语言开发的,或者用其他语言开发但提供Java接口,如JTextCat,但这些工具箱或程序库很少是专为文本分类而设计的。
2.中文文本分类及相关软件分析
面向对象分析可以在不同的抽象层次上进行:在企业级,面向对象分析可以和信息工程方法结合;在业务范围层次,可以定义一个描述某特殊的业务范围(或产品或系统范畴)的工作的对象模型;在应用层次,对象模型着重于特定的客户需求。中间抽象层次的面向对象分析活动称为领域分析,领域分析是软件工程师了解问题的背景的过程,其中“领域”指的是客户希望使用软件的一般性商业或技术领域。领域分析的目标是发现或创建那些可广泛应用的类,使得它们可以被复用。在某组织希望创建可广泛地用于整个应用范畴的可复用类(构件)库时,需要进行领域分析。对于面向对象的领域分析,应该以公共对象、类、子集合和框架等形式在特定应用领域中标识、分析和规约公共的可复用的能力。
2.1文本分类基本知识
文本分类一般分为训练和测试两个阶段。为了建立一个高性能的分类器,训练和测试需多次反复,组成一个反馈系统。完整的文本分类过程一般包括5个步骤:建立数据集、文本表示、特征降维、机器学习及训练分类器、性能评估[28]。图1显示了文本分类系统中的主要活动。
(1)确定分类语料库及预处理
这一步主要是选择或自行创建分类语料库,并进行预处理,包括处理乱码和非文本内容、机器内码转换、删除无效文本、对于中文文档需要进行分词、处理词干(Stemming)及停用词(StopWords)、按一定比例划分训练集和测试集。
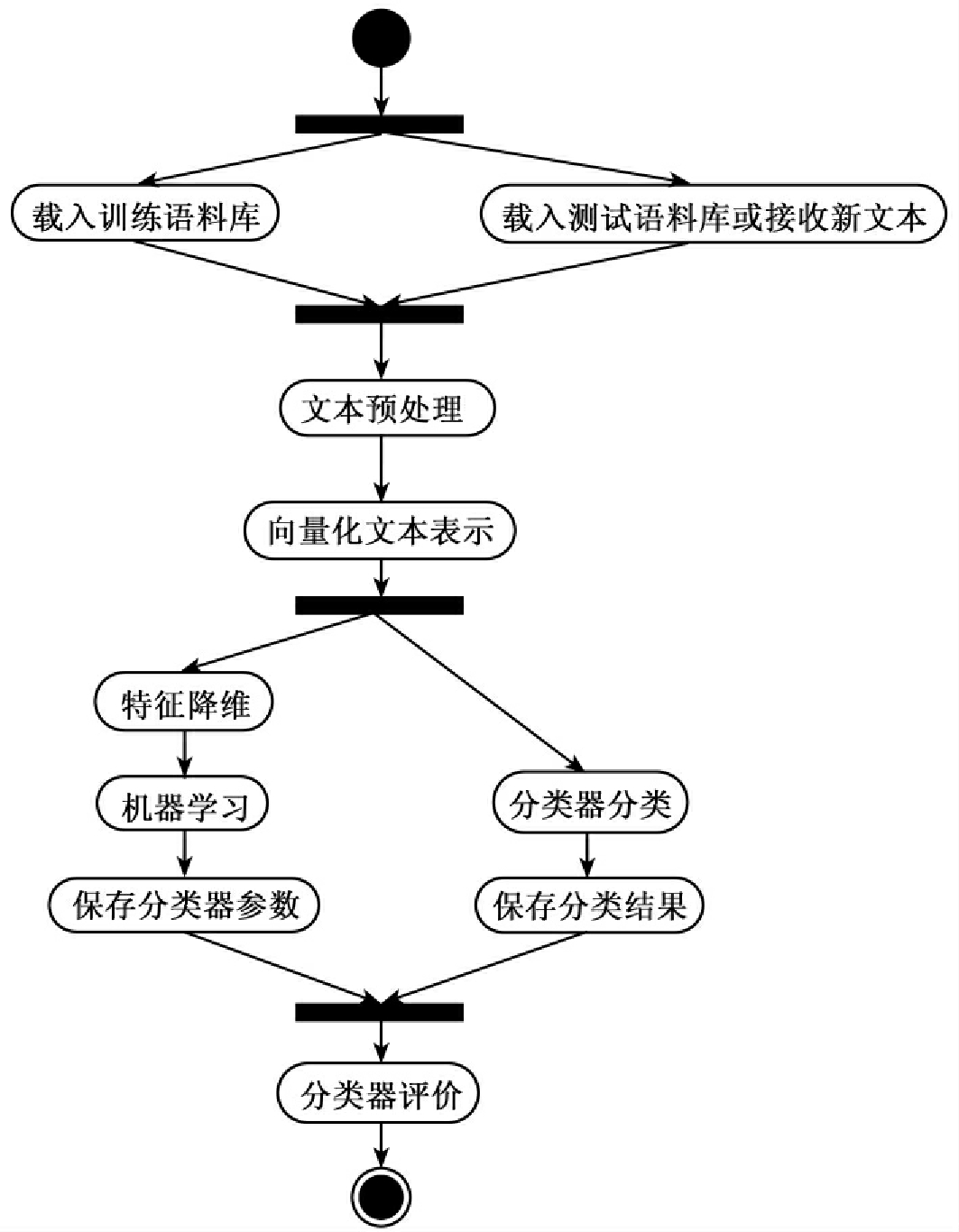
图1 文本分类活动图
(2)文档表示
文档表示又可称为文本标引,它确定特征单位,并按一定的描述模型对文本进行标引,其作用是将文本的内容按照一种计算机能够理解的格式用特征描述出来,使机器能够对文本进行处理和运算。
现有文本分类技术的前提假设是特征和文档类别概念密切相关。在这一假设下,通常有两种文档表示模型,即布尔模型和向量空间模型。
向量空间模型中,一篇文档表示为特征空间中的一个向量,这个向量也称为文档向量。文档向量中每一维对应于文档中的一个特征,它的权值计算方式通常采用TFIDF方法。TFIDF方法是Salton和McGill在1983年提出的。文档间的相似度计算主要通过计算文档向量的余弦相似度来得到。
布尔模型可以看作是向量空间模型的一个特例,它根据特征项是否在文档中出现而取权值为1或0。使用二值特征的分类效果在许多情况下并不比考虑特征频率的差。
决策树方法、关联规则方法和Boosting方法是基于布尔模型的;而KNN方法、SVM方法、LLSF方法则是基于向量空间模型; Bayes推理网络分类方法则考虑了文档中词之间的依赖关系。
(3)特征降维
文本分类问题的最大特点和困难之一是特征空间的高维性和文档向量的稀疏性。在中文文本分类中,通常采用词条作为最小的独立语义载体,原始的特征空间由可能出现在文章中的全部词条构成。而中文的词条总数超过20万,这样高维的特征空间对于几乎所有的分类算法来说都偏大,这不仅会影响分类的效率,甚至还可能超出机器或算法的处理能力。于是,寻求一种有效的特征降维方法,降低特征空间的维数,生成一个更紧凑的特征空间,提高分类的效率和精度,成为文本自动分类中需要解决的重要问题。
在文本分类中,常用的特征降维方法有两类,一类是特征选择,它是基于阈值的统计方法,如特征频度,文档频率方法,信息增益方法,互信息方法,相关系数,CHI方法,期望交叉熵,文本证据权等,另一类是特征抽取,它是由原始的特征空间经过某种变换构建正交空间中的新特征的方法,如主分量分析方法和潜在语义索引方法等。基于阈值的统计方法具有计算复杂度低,速度快的特点,尤其适合做文本分类中的特征降维。
(4)机器学习与分类器分类
文本分类算法是根据一个文档的特征向量计算该文档的类别。现在广泛应用的基于向量空间表示和统计学的分类算法包括Naive Bayes法、Rocchio法、KNN方法、决策树、神经网络法、支持向量机(SVM)法、基于投票的方法等。分类器就是在给定的分类体系下,将文本分配到已经存在的类别中去的工具。它提取需要被分类的文本中所具有的特征性特点,将这些特征和经过训练阶段从训练样本集中提取的每个类别的一套特征相比较,最后确定其所属类别。
不同的文本分类算法对应于不同的分类器,分类算法就是分类器的设计方法,分类器是对分类算法的实现,不同的分类器对应的机器学习过程也不同。在训练集上进行机器学习,即需要从训练文档集中每一类别的所有文档特征向量生成类别的特征信息,从而确定分类器的各个参数,建立分类器。机器学习的依据是文本的内容,不能依据文本的其他元信息。在文本分类中,类型符号只是一些标记。
(5)性能评估
采用一定的评价指标,对机器分类的结果进行评价。不符合要求时,需要返回到前面的某一步骤,调整参数,重新再做。由于文本分类从根本上说是一个映射过程,即是将未标明类别的文本映射到已有的类别中,该映射可以是一一映射,也可以是一对多的映射,所以评估文本分类系统的标志是映射的准确程度和映射的速度。映射的速度取决于映射规则的复杂程度,而评估映射准确程度的参照物是通过专家思考判断后对文本的分类结果(这里假设人工分类完全正确并且排除个人思维差异的因素),与人工分类结果越相近,分类的准确程度就越高,这里隐含了评估文本分类系统的两个指标:准确率和查全率。
准确率是所有判断的文本中与人工分类结果吻合的文本所占的比率。其数学公式表示如下:
准确率(Precision)=分类的正确文本数/实际分类的文本数
查全率是人工分类结果应有的文本中与分类系统吻合的文本所占的比率,其数学公式表示如下:
查全率(Recall)=分类的正确文本数/应有文本数
准确率和查全率反映了分类质量的两个不同方面,两者必须综合考虑,不可偏废。因此,存在一种新的评估指标:F1测试值,其数学公式如下:
F1测试值=(准确率×查全率×2)/(准确率+查全率)
另外有微平均和宏平均两种计算准确率、查全率和F1测试值的方法:
微平均:计算每一类的准确率、查全率和F1测试值。
宏平均:计算全部类的准确率、查全率和F1测试值。
所有文本分类系统的目标都是使文本分类过程更准确,更快速。
2.2相关软件分析
相关软件包括商业软件和开源软件。商业的文本分类软件如Accumo因为不开放源代码,所以其分类技术和软件的设计策略是无法知道的,故它对于研究工作来说往往缺乏价值。而文本分类的目标包括了对文本分类研究的支持,所以,以下主要讨论的是开源的相关软件。
(1)Weka
Weka是新西兰Waikato大学开发的一个基于Java的数据挖掘开源软件,它包含了一个用于数据挖掘的机器学习算法集,还包含了一系列的工具,通过这些工具可以进行数据集的预处理、分类、回归分析、聚类、关联规则分析,以及这些处理的可视化。
Weka项目的主要目标是构建一个数据挖掘领域的理论上的框架,使研究人员能更有效地使用机器学习算法来研究新的问题,并为研究新的机器学习算法提供基础设施。
对于文本分类研究人员和应用系统开发人员来说,Weka有以下不足:首先Weka并不适合建立一个实际的文本分类应用系统,它主要是一个理论上的框架。Weka共有超过600个的类,对于构建应用系统来说不够简洁易用,而一些针对实际应用的优秀框架如Lucene,JUnit,Struts,它们的类数目都不多,简洁而又功能强大,易于构建灵活而强健的应用程序。其次,Weka专注于机器学习和数据挖掘,其分类器的设计并非专为文本分类而设计,而是考虑到更加广泛的模式分类问题。
(2)Bow
Bow(又称为Libbow)是卡内基梅隆大学开发的一个基于C语言的工具箱,用于统计语言建模,统计文本分析,文本检索(Arrow),文本分类(Rainbow)和文本聚类(Crossbow)。Rainbow是基于Bow工具箱的一个文本分类可执行程序,主要使用Na6ve Bayes分类方法进行文本分类。Bow存在的一个明显的问题是没有好的文档。
(3)LibTextCat与JTextCat
LibTextCat是一个子程序库,它实现了Cavnar和Trenkle所描述的基于N-Gram模型的文本分类技术。但LibTextCat实现的是轻量级的文本分类,它主要用于文本的语言猜测(Language Guessing)。在这个应用上,LibTextCat的精确性表现近于完美。
LibTextCat是用Perl语言编写的,JTextCat是LibTextCat的一个Java接口。
(4)中科院文本分类系统
该系统是一个用C++开发的具有图形界面的文件软件,可以在网上获取源程序,但并无规范的文档。该系统性能强大,包含KNN分类器和SVM分类器,支持中文和英文文档的分类,并支持6种特征选择方法,用户还可以自定义特征空间的维数。该系统的安装文件还包含了一个示例分类语料库。
该系统是文本分类系统的一个很好的范例。但对于文本分类的研究人员和应用系统的开发人员来说,该系统则有诸多不足:首先是编程语言的限制,必须使用C++作为开发语言;其次,文本分类的研究人员要实验自行设计的算法必须修改其源程序,而该系统并无规范的文档,且没有把系统的变化点和不变点封装起来,在这种情况下修改源程序是困难而不安全的。
(5)AICategorizer
AICategorizer是悉尼大学开发的一个专为文本分类而设计的框架。该框架由Perl语言编写,这也正是它很难获得广泛应用的主要原因。
3.设计模式与文本分类框架
3.1设计模式与框架
面向对象的设计模式中,一个模式有4个基本要素:模式名称、问题(描述了应该在何时使用模式)、解决方案(描述了设计的组成部分,它们之间的相互关系及各自的职责和协作方式)、效果(描述了模式应用的效果及使用模式应权衡的问题)。不同于设计模式,框架并不是一种通用的设计规则,它是由可提供某个特定问题域功能的一些类和接口组成的。通常的,一个框架会采用多个模式。如最著名和应用最广的GUI框架——MVC框架就包括了Observer模式、Strategy模式、Composite模式等。
设计模式与框架最主要的不同在于如下3个方面:一是设计模式比框架更抽象,框架能够用代码表示,而设计模式只有其实例才能表示为代码。二是设计模式是比框架更小的体系结构元素。设计模式和框架对体系结构的关注程度是不同的。设计模式是微型体系结构,框架是子系统的体系结构。绝大多数情况下,功能完全的系统会引入多个框架。而一个典型的框架包括了多个设计模式,而反之绝非如此。三是框架比设计模式更加特例化。框架总是针对一个特定的应用领域,而GoF的23种设计模式几乎能被用于任何应用。
另一方面,设计模式对于框架的设计来说非常重要。一个使用设计模式的框架更可能获得高层次的设计复用和代码复用。成熟的框架通常使用了多种设计模式,设计模式有助于获得无须重新设计就可适用于多种应用的框架体系结构。
当框架和它所使用的设计模式一起写入文档时,我们可以得到另外一个好处。了解设计模式的人能较快地洞悉框架,甚至不了解设计模式的人也可以从产生框架文档的结构中受益。加强文档工作对于所有软件而言都是重要的,但对于框架其重要性显得尤为突出。设计模式通过对框架设计的主要元素做更明确的说明可以降低用户学习框架的难度。
3.2常用模式与应用
(1)Strategy模式及其应用
Strategy模式又称Policy模式,主要用于定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。这里的算法并非狭义的数据结构或算法理论中所讨论的KMP、快速排序等算法,而是指应用程序设计中不同的处理逻辑,前面所说的狭义的算法只是其中的一部分。
当存在以下情况时可考虑使用Strategy模式:
·许多相关的类仅仅是行为有异。“策略”提供了一种用多个行为中的一个行为来配置一个类的方法。
·需要使用一个算法的不同变体。例如,你可能会定义一些反映不同的空间/时间权衡的算法,当这些变体实现为一个算法的类层次时,可以使用策略模式。
·算法使用客户不应该知道的数据。可使用策略模式以避免暴露复杂的、与算法相关的数据结构。
一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现。将相关的条件分支移入它们各自的Strategy类中以代替这些条件语句。更具体的应用实例包括:以不同的格式保存文件;以不同的方式对文件进行压缩或其他处理;以不同的方式绘制/处理相同的图形数据,等等。
Strategy模式使得算法与算法的使用者相分离,减少了二者间的耦合度,使得算法可独立于使用它的客户而变化;同时,由于设计粒度的减小,程序的复用性也得到了进一步提高,分离出来的算法可以更好地适应复用的需要。
但是,Strategy模式无法隐藏任何信息,客户代码通常要知道有多少种策略可供选择,并且要提供某种选择标准,这就把算法的决定权交给了客户程序设计人员或用户。为了把任意数量的不同参数传递给不同的算法,要开发一种Context接口和策略方法,这样的接口要足够大,以传递大量参数,包括一些特定算法所不用的参数。
(2)Composite模式与语料库
Composite模式将对象组合成树形结构以表示“部分—整体”的层次结构,使用户对单个对象和组合对象的使用具有一致性。该模式的关键是一个抽象类或接口,它既可以代表组件,又可以代表组件的容器,同时它也声明了所有的组合对象共享的一些操作。组合体内这些对象都有共同接口,当组合体一个对象的方法被调用执行时,Composite将遍历整个树形结构,寻找同样包含这个方法的对象并实现调用执行。
以下情况使用Composite模式:
·表示对象的部分——整体层次结构
·希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
对于文本分类系统来说,需要一个分类语料库,并将其按一定的比例分为训练文档集和测试文档集,分类器的学习需要先用训练文档集对其进行训练,然后再用测试文档集对其进行测试和评价。不管是训练文档集还是测试文档集,都需要对其进行预处理,而分类语料库含有多个目录,每个目录下面可能是若干个文档,也可能是若干个目录,也可能是既有文档也有目录。分类语料库也可以用一个目录来表示。于是整个语料库都可以用目录树来表示。另外,语料库中的文档允许用不同的文件格式,如XML,PDF,Word,HTML,纯文本文档(Plain Text)等类型。
对于上述语料库的结构,一个简单的实现方法是为XML、PDF这样的文档定义一些类,另外定义一个类作为这些类的容器类(Container)。然而,这种方法存在一个问题:使用这些类的代码必须区别对待单个的文档对象和文档的集合对象,而实际上在框架中大多数情况下可以认为它们是一样的。对这些类区别使用,则会使程序变得更加复杂。文档集树形的层次结构让我们想到用Composite模式来建模。Composite模式描述了如何使用递归组合,使得用户不必对这些类进行区别。
Composite模式的关键是一个抽象类或接口,它既可以代表单个的文档,又可以代表文档的容器。在我们的框架中这个接口就是TC_Document,它声明一些与特定文档对象相关的操作,如get-Categories,同时它也声明了所有的组合对象共享的一些操作,例如一些操作作用于访问和管理它的子部件。语料库应用Composite模式的类层次结构如图2所示。
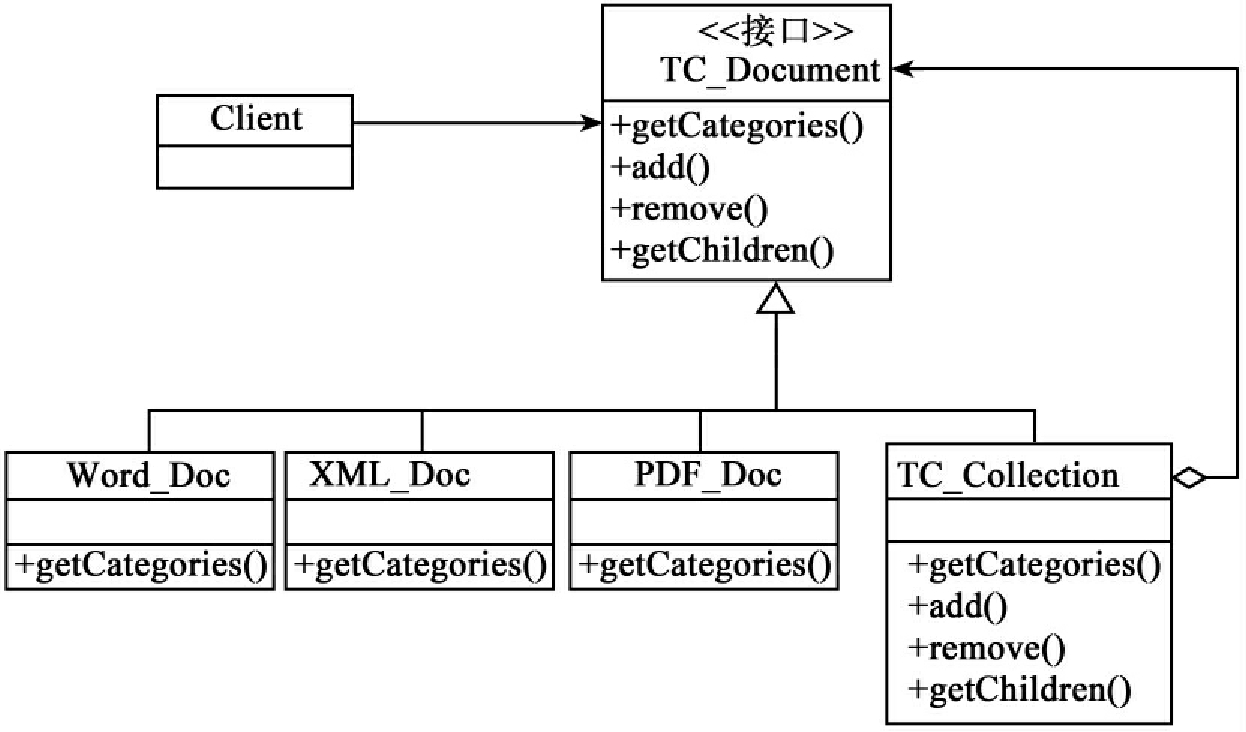
图2 语料库应用Composite模式的类层次结构
子类PDF_Doc、XML_Doc和Word_Doc等定义了一些单个的文档对象,这些类实现getCategories方法,分别作用于PDF文档,XML文档,Word文档。由于这些对象属于叶子类,没有子类,因此它们都不执行与子类有关的操作。
(3)Fa9ade模式与自定义中文分词
Fa9ade模式为子系统中的一组接口提供一个一致的界面。Fa9ade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用,即希望简化现有系统的使用方法时,需要定义自己的接口。
以下情况适用于Fa9ade模式:
·需要为一个复杂子系统提供一个简单接口时。子系统往往因为不断演化而变得越来越复杂。大多数模式使用时都会产生更多更小的类。这使得子系统更具可重用性,也更容易对子系统进行定制,但这也给那些不需要定制子系统的用户带来一些使用上的困难。Fa9ade可以提供一个简单的缺省视图,这一视图对大多数用户来说已经足够,而那些需要更多的可定制性的用户可以越过Fa9ade层。
·客户程序与抽象类的实现部分之间存在着很大的依赖性。引入Fa9ade将这个子系统与客户以及其他的子系统分离,可以提高子系统的独立性和可移植性。
需要构建一个层次结构的子系统时,使用Fa9ade模式定义子系统中每层的入口点。如果子系统之间是相互依赖的,可以让它们仅通过Fa9ade进行通讯,从而简化了它们之间的依赖关系。
目前,国内已有几种Java接口的中文分词组件,可以把每种中文分词组件封装起来作为一种策略。一般的用户可以根据需要进行选择和配置,对另外一些用户来说,可能希望采用自定义的中文分词系统,框架需要能处理这种情况。因为我们对中文分词应用了Strategy模式,所以要自定义中文分词,则首先必须考虑实现中文分词策略所定义的接口。
仔细观察已有的中文分词策略,容易发现在每个具体的中文分词组件的接口下,都隐藏了多个具体的类。要理解这些类之间的关系,我们需要先理解中文分词的原理。中文分词系统实现的基本思想可以描述为:首先对输入的中文文本进行预处理,将其分割成一系列的汉语字串。在词语粗分阶段,得出N个概率最大的粗切分结果。然后,利用结构规则或统计的方法识别未登录词,并计算其概率,加入到切分词图中,视其为普通词处理。最终利用HMM模型进行词性标注排歧,优选出最大概率的文本切分标注结果。
如图3所示,分词系统包含的3个主要功能模块是:词语粗切分、未登录词识别、标注排歧。系统中的预处理模块主要实现的功能是:提取输入文本中包含的标点符号、空格、回车换行符、英文单词等自然分割信息符号,并直接将它们作为切分词图中的一部分;根据输入文本中存在的自然分割信息,将文本分割成一系列的汉语字串,交由词语粗切分模块进行进一步的处理。

图3 分词流程取例
容易看出,分词系统可以划分为多个子功能的集合,这对应了多个类的集合。有些特殊的应用程序可能会需要直接访问这些类,但是大多数的用户并不需要关心未登录词识别、标注排歧等细节。对这些用户来说,分词系统中功能强大但层次较低的接口只会使它们的任务复杂化。
为了对用户屏蔽这些类,现有的分词组件提供了一个高层的接口,这个接口对应分词策略的接口。每一个具体的分词策略都相当于是一个外观。如果分词组件的接口和分词策略的接口不同,可以通过Adapter模式进行适配。
分词组件提供的高层接口对客户屏蔽了具体的类,因而减少了客户处理的对象的数目并使得子系统使用起来更加方便。对于使用自定义中文分词系统的用户来说,他们不仅需要通过实现分词策略接口从而强制性地为自定义中文分词系统提供一个高层接口外,还可能需要直接访问自定义中文分词系统中具体的类。因此,自定义中文分词系统可以应用Fa9ade模式,具体的策略类就是它的外观。
(4)Singleton模式及其应用
Singleton模式保证一个类有且仅有一个实例,并提供了一个访问该实例的全局访问点。对于一些类来说,只有一个实例是很重要的。虽然系统中可以有许多打印机,但却只应该有一个打印假脱机(Printer Spooler),只应该有一个文件系统和一个窗口管理器。另外,在很多操作中,比如建立目录、数据库连接都需要这样的单线程操作。Singleton让类自身负责保存它的唯一实例,这个类可以保证没有其他实例可以被创建(通过截取创建新对象的请求),并且它可以提供一个访问该实例的方法。
以下情况适用Singleton模式:
·当类只能有一个实例而且客户可以从一个众所周知的访问点访问它时。
·当这个唯一实例应该是通过子类化可扩展的,并且客户应该无需更改代码就能使用一个扩展的实例时。
Singleton模式可以应用到语料库这个层次上,使得这个语料库的唯一实例是类的一般实例,但该类被写成只有一个实例能被创建。做到这一点的一个常用方法是将创建这个实例的操作隐藏在一个类操作即一个静态方法后面,由它保证只有一个实例被创建。这个操作可以访问保存唯一实例的变量,而且它可以保证这个变量在返回值之前用这个唯一实例初始化。这种方法保证了单例在它的首次使用前被创建。
在Java中可以使用Singleton类的静态方法GetInstance来定义这个类操作。Singleton类还定义了一个静态属性Corpus,它包含了一个指向它的唯一实例的引用。
对于分类语料库,我们定义了一个CorpusController类,类中实现Singleton模式的代码如下:
public class CorpusController{
private CorpusController(){}
private static CorpusController corpus;
public static synchronized CorpusController getInstance
(){
if(corpus==null){
corpus=new CorpusController();
}
return corpus;
}
}
使用Singleton模式有如下优点:因为Singleton类封装它的唯一实例,所以它可以严格地控制客户怎样及如何使用它;Singleton模式是对全局变量的一种改进,它避免了那些存储唯一实例的全局变量污染名空间;Singleton类可以有子类,而且用这个扩展类的实例来配置一个应用是很容易的。
(5)Factory Method模式与分类器对象的创建
在软件系统中,经常面临着“某个对象”的创建工作,由于需求的变化,这个对象的具体实现经常面临着剧烈的变化,但是它却拥有比较稳定的接口。为了应对这种变化,软件设计者们提出了一种封装机制来隔离出“这个易变对象”的变化,从而保持系统中“其他依赖该对象的对象”不随着需求的改变而改变。这就是Factory Method模式。
Factory Method模式定义一个用户创建对象的接口,让子类决定实例化哪一个类。Factory Method使一个类的实例化延迟到其子类。在框架中,使用抽象类定义和维护对象之间的关系。这些对象的创建通常也由框架负责。框架必须实例化类,但是,它只知道不能被实例化的抽象类。Factory Method模式主要用于工具包和框架中。
Factory Method模式的结构如图4所示:
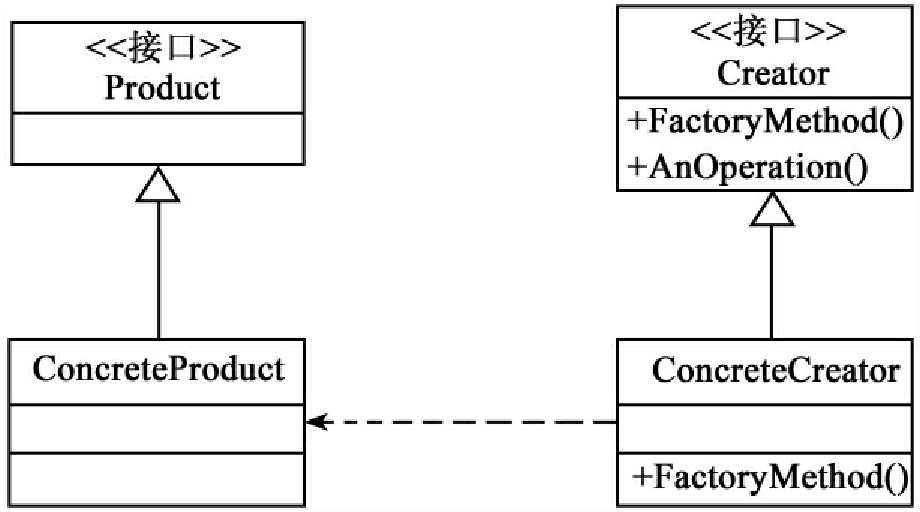
图4 Factory Method模式的结构
Product定义工厂方法所创建的对象的接口;ConreteProduct实现Product接口;Creator声明工厂方法,该方法返回一个Product类型的对象;ConcreteCreator重定义工厂方法以返回一个ConcreteProduct实例。
在下列情况下可以使用Factory Method模式:
一是当一个类不知道它所必须创建的对象的类的时候;
二是当一个类希望由它的子类来指定它所创建的对象的时候;
三是当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化的时候。
(6)Manager模式与类别管理器
Manager模式将类实例的管理封装到了单独的管理对象中,其中考虑了独立于类的管理功能的变体和不同对象类的管理者重用。设计主要的对象类时,经常需要以同样的方式处理该类的所有实例,如搜索带有特定属性的实例需要访问所有实例集合。因此,使用类变量和类方法可能会过多地限制灵活性。根据需要创建将在客户组件之间共享的对象,如GUI框架中的字体描述对象。一般说来,创建这种字体对象的操作需要耗费相当高的代价,因为存在有大量字体,所以预先创建所有字体对象是不可能的。用户经常想以相同的方式控制类的所有对象的生存时间。但是,想要除去永久对象在内存中的拷贝,用户需要跟踪使用的对象。
Manager模式提供了以下的解决方案:引入一个分离的组件管理者,它将管理对象集合看作一个整体。管理者组件处理与访问、创建或删除管理对象相关的问题。要求特定管理对象的客户从管理者处取出一个对象引用,然后在客户组件之间与主要的对象完成所有的交互。不再需要主对象时,客户组件将主对象返回给管理者。管理对象按客户要求执行任务,在这种模式下将它们称为主体。
分类语料库必然包含多个类别的文档,对于文本分类框架,我们必须对关于类别的信息进行管理。为了明确框架的设计和准确地定义类的职责,我们首先对分类语料库中的类别做出几个假设:一是语料库顶级目录下的一个文件夹代表一个类别,文件夹和类别一一对应,一个类别仅有一个文件夹和路径;二是一篇文档可以属于多个类别,但根据假设一的限制,当一篇文档可以属于多个类别时,该篇文档需要在其所属的每个类别中都存在一份拷贝,也即意味着不同文件夹中可能存在相同的文档。
可以用一个Category类的实例来表示一个或多个文档的类别。Category类的责任包括:存放一个类别的名字,存放该类别所在文件夹的路径,存放该类别可用于分类的类别特征信息和统计信息。机器学习会产生每个类别的特征信息和参数,Category对象应保存该类的这些信息。对于Category类来说,框架经常需要以同样的方式处理该类的所有实例,如对分类器进行训练时,需要访问其所有实例集合。因此,如果使用类变量和类方法可能会过多地限制灵活性。要改变管理对象的方式而不改变类本身是不容易的,在Java中必须重新编译所有文件,即使它们没有受到管理改变的影响。而如果管理这些对象的代码也共享,而不被复制,将会很有帮助。
对于Category而言,Category Manager又充当了工厂的角色,Create_category方法就是工厂方法模式的应用。如果想获取主体类层次结构的实例,管理者需要获取欲对哪个子类进行实例化的信息。这一信息可以由客户作为参数给定,也可以在创建时进行计算。另外,Category Manager应该也只具有一个实例,所以对Category Manager我们也可以使用Singleton模式。
(7)Adapter模式与开源资源的利用
Adapter模式将一个类的接口转换成客户希望的另外一个接口,使原本由于接口不兼容而不能一起工作的那些类可以一起工作,即我们需要一种方法,为一个内容合适但接口不匹配的对象创建一个新的接口。
以下情况应该使用Adapter模式:
一是需要使用一个已经存在的类,而它的接口不符合你的需求。
二是需要创建一个可以复用的类,该类可以与其他不相关的类或不可预见的类(即那些接口可能不一定兼容的类)协同工作。
三是需要使用一些已经存在的子类。但是不可能对每一个都进行子类化以匹配它们的接口。对象适配器可以适配它的父类接口。这种情况仅适用于对象Adapter。
对于软件的重用,有两个重要的原则:一是增强设计的可重用性,二是充分利用可重用组件。对于文本分类框架来说,在强调可重用设计的同时,也要重视利用一些现有的可重用资源。在Java开源领域,已经存在一些与文本分类相关的工具箱或程序包,如Weka。利用现有的可重用资源一方面可以降低框架开发的投入,另一方面被广泛使用的可重用组件往往也是有着优秀的设计和经过了实践检验的产品,利用它们可以提高框架的可靠性。
但是,在框架中应用这些可重用组件的时候,会产生一个问题,就是接口的不匹配问题。比如说对于中文分词,我们应用了Strategy模式,把每种分词组件所实现的分词算法作为一种策略封装起来,于是对于每一个具体的分词策略,都需要实现同样的分词策略接口,但是各个分词组件提供的接口不太可能全部相同,于是就产生了矛盾。于是我们需要一种方法,为这个内容合适但是接口不匹配的对象创建一个新的接口。利用Adapter模式,我们可以使用一些已经存在的子类而不需要对每一个都进行子类化以匹配它们的接口,对象适配器可以适配它的父类接口。文本分类框架中应用了大量的设计模式,许多设计模式都要求某些特定的类派生自同一个类。如果已经有现成的类,比如开源的工具箱中的类,我们可以使用Adapter模式将它与适当的抽象类或接口相匹配。
(8)Bridge模式与文件类型转换
Bridge模式的意图是将抽象部分与它的实现部分分离,使它们都可以独立地变化。在这里“实现部分”是指抽象类的对象和用来实现抽象类的派生类的对象,而不是抽象类的派生类。
以下一些情况适合使用Bridge模式:
一是不希望在抽象和它的实现部分之间有一个固定的绑定关系。例如这种情况可能是因为在程序运行时刻实现部分应可以被选择或切换。
二是类的抽象以及它的实现都应该可以通过生成子类的方法加以扩充。这时Bridge模式使你可以对不同的抽象接口和实现部分进行组合,并分别对它们进行扩充。
三是对一个抽象的实现部分的修改应不对客户产生影响,即客户的代码不必重新编译。
在文本分类框架中,允许分类语料库中包含不同文件类型的文档,如XML文档,PDF文档,WORD文档等等。为了方便后续的处理,在预处理过程中我们在分词之前就应该对这些文档进行转化,可以将这些不同文件类型的文档全部转化为纯文本文件。对于不同类型的文档,以及文档的集合,可以定义一个共同的接口TC_Document,PDF_Doc类、TC_Collection类、Word_Doc类和XML_Doc类都实现了TC_Document接口。
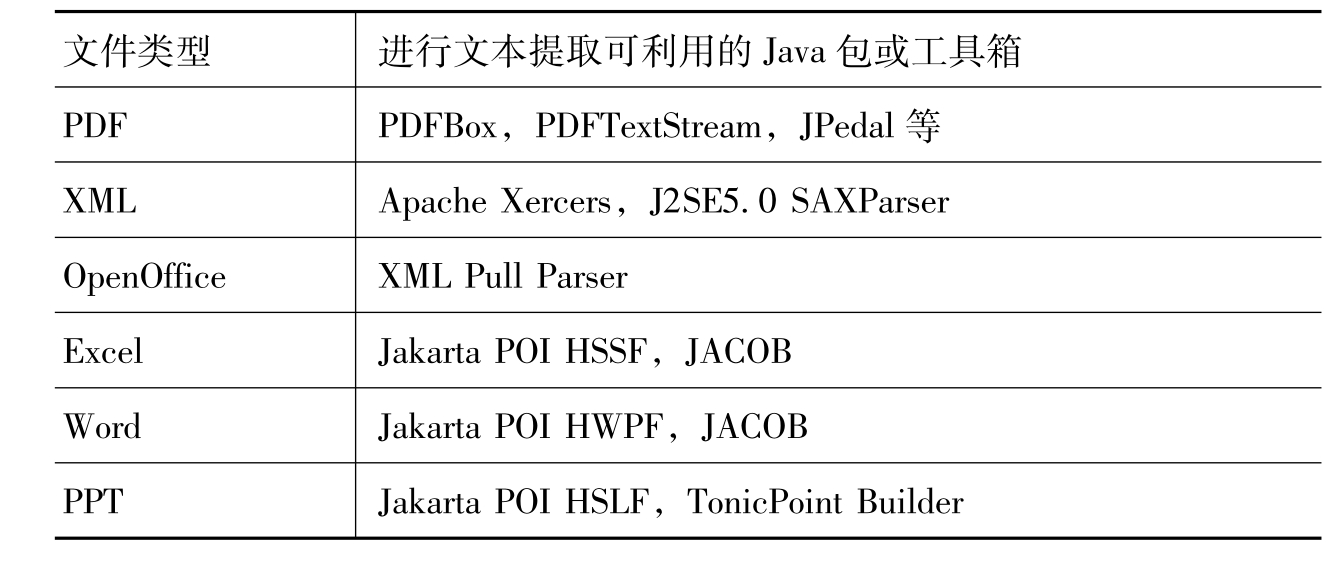
对于TC_Document接口,定义一个文件类型转换的方法Transform,在实现TC_Document接口的每个子类中实现Transform方法,这样便可以实现不同类型文档的转化。但是对于这种实现方式,我们只考虑了每种文件类型对应一种转换程序,事实上,对于PDF文档和XML文档等广泛使用的文件类型,在Java社区已经存在多种优秀的转化工具箱或相关的包,它们各有优势,不同的用户可能希望采用不同的转化方式。表3提取不同类型文件的文件可利用的Java包或工具箱。
表3 提取不同类型文件的文件可利用的Java包或工具箱
作为一个框架,必须考虑到可扩展性,因此要求对实现TC_Document接口的每个子类,可以有不同的Transform方法的实现。为了满足这样的要求,我们可以用类的继承来实现,但是这会引起类爆炸的问题,并且设计模式的一条重要原则就是优先使用对象组合而不是类继承。继承是为每种变化使用不同的适用性变化,而对象组合则是将变化转移到使用或拥有变化的对象中。继承机制将抽象部分和它的实现部分固定在一起,使得难以对抽象部分和实现部分独立地进行修改、扩充和利用。
我们需要有一种方式来分离抽象部分的变化和实现部分的变化,这样类的数量只会线性增加。这就是Bridge模式的真正意图:将抽象部分与它的实现部分分类,使它们都可以独立地变化。
设计模式的另一条重要原则是:发现并封装变化点。过去,开发者通常依靠继承树来为这些变化点定位。但是,这条原则告诉我们,应该尽可能使用对象组合。其意图是可以在独立的类中包含变化点,从而使未来的变化不会影响现在的代码。达到这一目的的方法之一是:将所有的变化点都包含在自己的抽象类中,然后观察抽象类彼此之间如何发生关联。
于是,应该首先识别出什么在发生变化。容易看出,上述问题的一个变化点就是文件类型的转化方法Transform,于是我们可以考虑用Transformer接口对其进行封装。我们仍然用TC_Document接口来封装文档的概念,文档有责任知道如何转化自己的类型。另一方面,Transformer对象负责文件类型的转化。我们通过在类中定义方法来表示这些责任。应用Bridge模式后,类层次结构如图5所示。
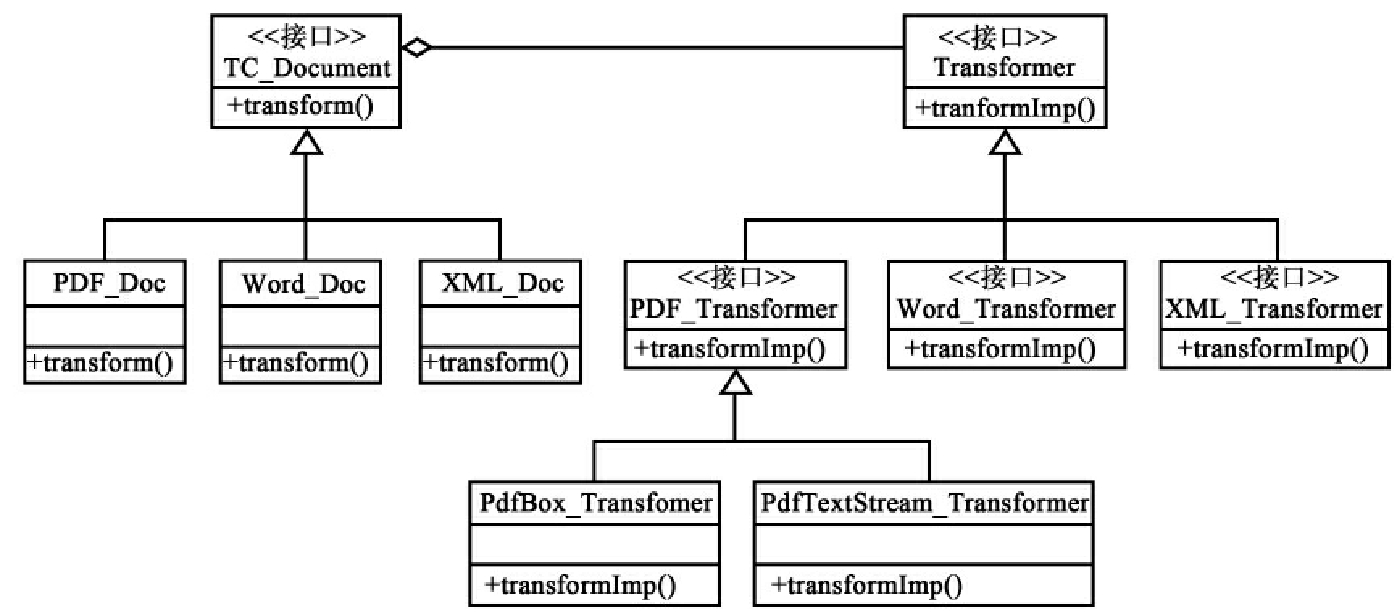
图5 文件类型转换与Bridge模式
应用Bridge模式后,接口与实现分离有助于分层,从而产生更好的结构化系统,系统的高层部分仅需知道TC_Document和Transformer即可。同时,可以对客户程序隐藏实现细节。
4.总结
中文文本分类框架的设计与实现,对于相关研究人员快速地构建文本分类实验系统,对于应用系统开发人员快速地将文本分类功能集成到应用系统中,具有很大的现实意义。本文从文本分类系统的需求分析出发,探讨了文本分类框架的设计和实现中的一些策略性的问题。在有些方面需要进行进一步的研究:
(1)框架进化。框架进化模式对文本分类框架的迭代进化有诸多启发。该模式认为有必要开发3个用户认为可以帮助建立框架的应用程序。最初的设计可能为单应用程序所接受,但推广到多应用程序的能力只有在实际创建它们并决定哪些抽象可以重用后才能实现。我们的文本分类框架尚未经过多应用程序的实际构建,所以这是以后应该做的工作之一。
(2)测试。测试是确保交付的软件正常运行的最好办法。每个开发者都会执行某种类型的测试,以确保新写的代码能正常工作。测试同编码活动越接近,从代码获得反馈就越快。单元测试是开发活动的一部分,这是一种细粒度的测试,很多公司明确要求开发者在提交功能模块的同时也要提交相应的测试用例。对文本分类框架来说,单元测试最有吸引力的地方就是它可以帮助优化设计,容易使用意味着良好的设计。另外,单元测试用例可以当作文档使用。
(3)分类器的组合。分类器设计的常用方法是确定一组合理的候选模型,使用带有类别标签的训练集对分类器进行训练,然后使用测试集估计其性能,选用给出最好性能的分类器。用这种方法可以得到应用在整个特征空间上的单个“最佳”分类器。面对复杂的数据集,对若干个分类器的结果进行组合可以获得优于单个分类器的性能。本文的文本分类框架尚未考虑到分类器的组合问题,这是又一个可扩展的地方。
【参考文献】
[1]Alan Shalloway,James Trott.Design Patterns Explained:a New Perspective on Object-Oriented Design[M].Addison-Wesley Professional,2001.
[2]James O.Coplien,Douglas C.Schmidt.Pattern Language of Program Design[M].Addison-Wesley Professional,1995.
[3]同[2].
[4]同[2].
[5]Frank Buschmann,Regine Meunier.Pattern-Oriented Software Architecture,Volume 1:A System of Patterns[M].John Wiley&Sons,1996.
[6]同[2].
[7]Ted Husted,Vincent Massol.Junit in Action[M].Manning Publications,2003.
[8]同[7].
[9]Martin Fowler,Kent Beck.Refactoring:Improving the Design of Existing Code[M].Addison-Wesley Professional,1999.
[10]同[9].
[11]同[7].
[12]Robert C.Martin.UML for Java Programmers[M].Prentice Hall PTR,2003.
[13]同[12].
[14]Desmond Francis D'Souza,Alan Cameron Wills.Objects,Components,and Frameworks with UML:the Catalysis Approach[M].Addison-Wesley Professional,1998.
[15]David J.Hand,Heikki Mannila.Principles of Data Mining[M].The MIT Press,2001.
[16]Kirk Knoernschild.Java Design:Objects,UML,and Process[M].Pearson Education,2001.
[17]Ian Sommerville.Software Engineering[M].Addison Wesley,2000.
[18]同[17].
[19]Cay S.Horstmann.Object-Oriented Design&Patterns[M].Wiley,2003.
[20]Kjersti Aas,Line Eikvil.Text Categorization:a Survey[M].Addison-Wesley Professional,June 1999.
[21]James W.Cooper.Java Design Patterns:a Tutorial[M].Addison-Wesley Professional,2000.
[22]Ji He,Ah-Hwee Tan,Chew-Lim Tan.A Comparative Study on Chinese Text Categorization Methods[C].PRICAI 2000 Workshop on Text and Web Mining.
[23]Clemens Szyperski.Component Software:beyond Object-Oriented Programming[M].Addison-Wesley Professional,1997.
[24]Steven John Metsker.Design Patterns Java Workbook[M].Addison-Wesley Professional,2002.
[25]I.Jacobson,M.Griss,P.Jonsson.Software Reuse:Architecture,Process and Organization for Business Success[M].Addison-Wesley Professional,1997.
[26]Leszek A.Maciaszek.Requirements Analysis and System Design:Developing Information Systems with UML[M].Addison-Wesley,2001.
[27]Ricardo Baeza-Yates,Berthier Ribeiro-Neto.Modern Information Retrieval[M].Addison-Wesley,1999.
[28]代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].2004,18(1):26~32.

【作者简介】
张李义,男,安徽安庆人,1965年出生,工学博士,教授,管理科学与工程专业、电子商务专业的博士生导师,教育部高等学校电子商务专业教学指导委员会委员、湖北省电子商务学会秘书长、武汉大学信息管理学院信息系统与电子商务系主任、美国信息系统协会(AIS)会员。主要从事信息管理系统开发与控制、电子商务理论与应用、信息检索等方面的教学与研究工作。发表论文近50篇,被SCI、EI、ISTP等国际权威检索机构收录论文15篇,在科学出版社等国内重要出版社出版学术著作与教材6本。先后主持国家社会科学基金项目1项、教育部重点研究基地重大项目1项、国家商务部委托项目2项及多个湖北省教学改革项目,主持10余项企业委托项目。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











