



6.1 主成分分析
通过各种手段量测到的样品信息在数学上通常可以用矩阵的形式记录、表达。例如,含有p个波长点的n个牛奶样品的近红外光谱的吸光度就可以表达成一个行数为n、列数为p的矩阵
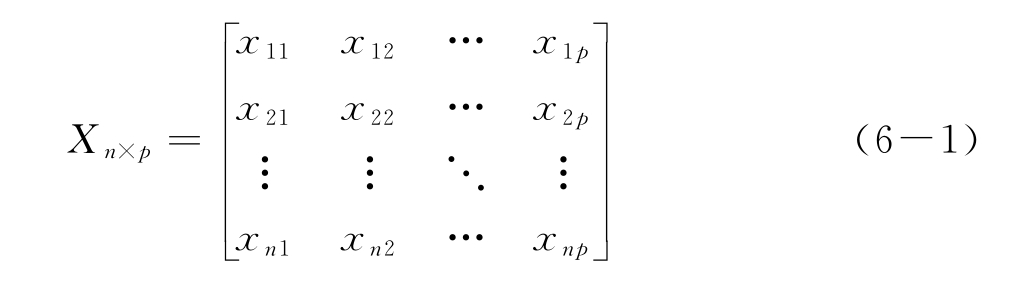
一条近红外光谱通常含有上千甚至几千个光谱点,此时方程(6-1)中的变量数p远远大于样本数,所以在用样品的光谱信息进行其定量或定性分析时,通常需要对光谱进行信息压缩以减少模型中自变量的个数。
所研究对象通常由一些特定的物理、化学等性质(假设有p个)来描述,当有n个研究对象时,这些性质也可以表述成方程(6-1)所示的矩阵形式。当这些性质间有时并不独立、具有相关性时,相当于方程(6-1)中的有些列是相关的;当方程(6-1)所描述的某些样本很相似时,其对应的物理、化学性质也很相似,相当于方程(6-1)中的有些行有很强的相关性。从线性代数的角度来说就是这些数据矩阵中存在相关或接近相关的行或列。因而这类数据矩阵可以由一些数量少于原始变量个数的、完全独立的新变量重新表示(即进行降维),以消除原始变量间存在的相关性,克服由此造成的运算不稳定、矩阵病态等问题。
例6-1 亮氨酸和异亮氨酸是两个同分异构的氨基酸,在合成亮氨酸的反应中副产物异亮氨酸因其结构与亮氨酸高度相似,两个化合物的分离十分困难,欲采用紫外分光光度法分析确定反应产物中目标化合物亮氨酸的含量。
亮氨酸、异亮氨酸溶液在适当条件下与茚三酮反应,生成有色配合物。以试剂空白作参比,采用口径为1cm的比色皿、在530~590nm范围内每隔4nm可测得亮氨酸和异亮氨酸溶液的紫外光谱如图6-1所示。
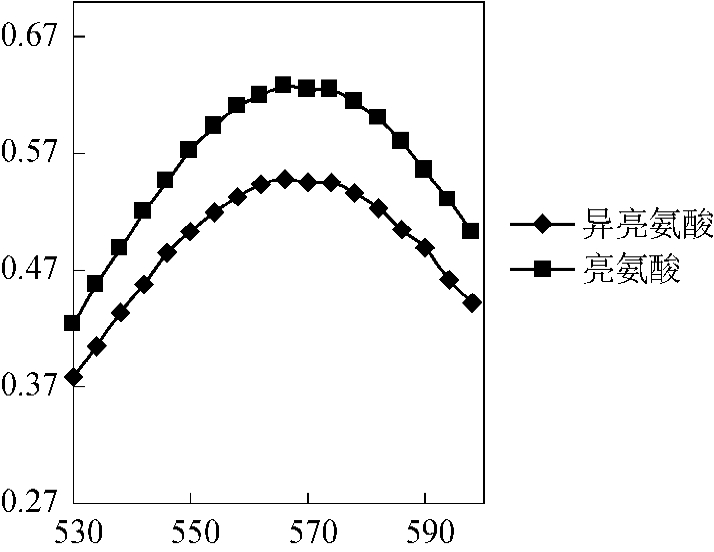
图6-1 亮氨酸、异亮氨酸的紫外光谱
配制不同浓度的亮氨酸、异亮氨酸组成的16个混合样品(设其浓度矩阵为X16×2),测得其在546~594nm 12个波长点下的紫外吸光度(记其吸光度矩阵为Y16×12)。根据多组分、多通道Lambert-Beer定律有
![]()
根据上式的关系,采用最小二乘多元线性回归可以求得吸光系数矩阵B
![]()
将16个样品浓度矩阵X16×2与吸光度矩阵Y16×12代入上式可以求出

为检验方程(6-4)所给出的吸光系数矩阵B2×12是否准确、可信,配制三个亮氨酸、异亮氨酸的混合样本采用相同的方法显色,且分别测定这三个样本在对应波长点下的紫外吸光度,记为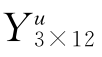 。
。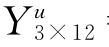 =
=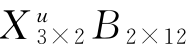 ,此式中的
,此式中的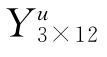 与
与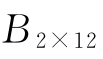 已知,将
已知,将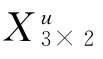 作为未知变量矩阵,求解该方程可得
作为未知变量矩阵,求解该方程可得
![]()
将方程(6-4)与三个检验样本的吸光度矩阵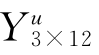 代入上式,可以求得三个检验样本中亮氨酸与异亮氨酸的浓度,与实际浓度的比较见表6-1。
代入上式,可以求得三个检验样本中亮氨酸与异亮氨酸的浓度,与实际浓度的比较见表6-1。
表6-1 三个混合物样品中亮氨酸、异亮氨酸的预测浓度与实际浓度
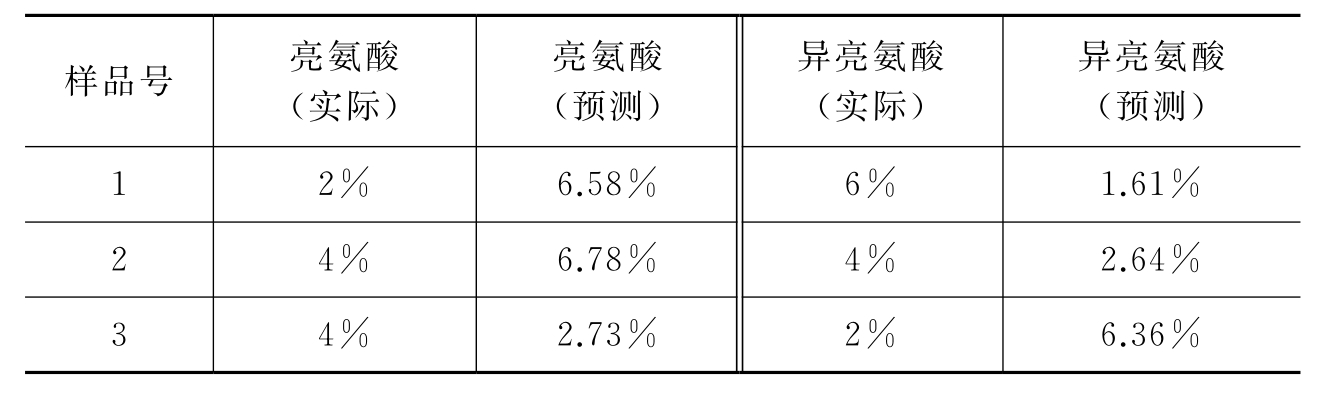
显然,根据方程(6-5)预测的亮氨酸与异亮氨酸的浓度与实际值的误差太大。根据图6-1可看出,亮氨酸与异亮氨酸的紫外吸收曲线形状十分相似,不难想象,由亮氨酸、异亮氨酸按照不同比例配制的16个用于建模的混合样品的紫外光谱也具有高度的相似性,这意味着矩阵Y16×12中的行接近相关,因而会导致根据方程(6-3)求得的吸光系数矩阵B2×12中的两个行矢量相关度较高,使得根据方程(6-5)求未知样本的浓度矩阵时矩阵(BBT)求逆运算误差较大,造成预测结果的不理想。
从本例可以看出,当原始数据矩阵中的信息存在较高的相关性时,不对其进行信息压缩和抽提、不消除原始信息间的相关性就直接用其建模和预测会造成分析结果的荒谬与不可信。
主成分分析(Principal Component Analysis,PCA)是一种常用并有效的信息压缩方法,它从多个样本构成的变量协方差矩阵出发,采用特征分解的方法获取方差最大的虚拟主成分来代替原有变量,得到的新变量——主成分得分,主成分之间相互独立、互不相关,可消除原始数据中存在的相关性和信息冗余。因此,PCA在多变量统计分析和光谱信息压缩、抽提等领域得到了广泛的应用。
PCA经常与其他方法相结合使用,如神经元网络——主成分方法,是通过对输入变量进行主成分分析后再将主成分作为神经元网络的输入信号进行建模、模式识别等分析;主成分回归则是对原始变量进行主成分分析后,用主成分得分替代原始变量进行回归分析;在模式识别中,PCA在很多模式识别方法中得到应用;多元灰色与黑色物系的分辨也经常用到PCA技术。因此,主成分分析是一种非常有用的信息抽提方法,它可以化繁为简,将众多的信息(变量)压缩成若干个新的虚拟变量,使问题得以简化。该方法在很多领域有广泛的应用,本章将对其进行专门介绍。带*的章节有助于读者理解主成分分析的数学本质与原理,略去该部分仍可掌握该方法的使用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











