



在生产和科学研究中,对某一个或一组变量x(t)进行观察测量,将在一系列时刻ti,(i=1,…,n)(t为时间变量且t1<t2<…<tn)所得到的一组离散数字序列集合x(t1),x(t2),…,x(tn),称之为时间序列,这种具有时间意义的序列也称为动态数据.这样的动态数据在自然、经济及社会等领域都是很常见的.如在一定生态条件下,动植物种群数量逐月或逐年的消长过程、某证券交易所每天的收盘指数、每个月的GNP、失业人数或物价指数等.
时间序列建模的基本步骤是:
1.用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据.
2.根据动态数据作相关图,进行相关分析,求自相关函数.相关图能显示变化的趋势和周期,并能发现跳点和拐点.跳点是指与其他数据不一致的观测值.如果跳点是正确的观测值,在建模时应考虑进去;如果是反常现象,则应把跳点调整到期望值.拐点则是指时间序列从上升趋势突然变为下降趋势的点.如果存在拐点,则在建模时必须用不同的模型去分段拟合时间序列,例如采用门限回归模型.
3.辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据.对于短的或者简单的时间序列,可用趋势模型和季节模型加上误差来进行拟合.对于平稳时间序列,可用通用AMRA模型(自回归滑动平均模型)及其特殊情况的自回归模型、滑动平均模型或组合ARMA模型等进行拟合.当观测值多于50个时一般都采用ARMA模型.对于非平稳时间序列则要先将观测到的时间序列进行差分运算,化为平稳时间序列,再用适当模型去拟合这个差分序列.
时间序列分析主要用于:系统描述,根据对系统进行观测得到的时间序列数据,用曲线拟合方法对系统进行客观的描述;系统分析,当观测变量取自两个以上变量时,可用一个时间序列的变化去说明另一个时间序列的变化,从而深入了解给定时间序列产生的机理;预测未来,一般用ARMA模型拟合时间序列,预测该序列未来值;决策和控制,根据时间序列模型可调整输入变量使系统发展过程保持在目标值上.
时间序列的趋势分析是研究时间序列的发展趋势,其方法的共同之处是假设时间序列的发展具有“惯性”,其变化在某段时间内大致沿着某一基础(趋势)线变化,趋势的预测采用各种各样的平滑法进行.时间序列的分析和预测,根据其变化趋势的不同分为水平时间序列和趋势变化序列.前者指的是时间序列的n个数据点都位于一根水平方向的直线上,或稍微复杂一些;这些散点在某条直线的上上下下,形成的折线几乎成一条水平直线,时间序列折线围绕水平直线向前展开.后者指的是时间序列如果受到某些因素的影响,会使得序列相应的期望值随时间的变化而变化.倘若这样的动态变化比较长期且变化具有方向性,那么该序列为趋势时间序列.
水平时间序列分析、预报、因时间序列没有上升或下降的趋势,对其未来的预测可以以历史资料的均值为基础.其中典型的有一次滑动平均模型和一次指数平滑模型.
趋势时间序列分析是在某一时刻t的随机观察变量值yt构成的期望数值列E(yt)=f(β1,β2,…,t).其中,f(β1,β2,…,t)在研究的时间范围内明显呈现上升或下降的趋势.其中典型的有线性回归、二次滑动平均、一次平滑、二次指数平滑和三次指数平滑.
对于随机无趋势时间序列,一次滑动平滑是一种修正的简单预测平均数,它是对已有观察值赋予等价的权.当预测时刻t时,常会有这样的感觉:以前的那些观察信息,越靠近时刻t的应当对t时刻有越大的影响,至少历史数据似乎不应当对t时刻有相同的权重.基于这样的朴实思想,新的修正手法将对不同时刻的历史数据赋予不同的权.于是,在一次滑动平均模型中,可由最近的n个时段求得平均值,以它作为t时刻的预测值.因此一次滑动平均模型可以表示为:
一次指数平滑方法就是时刻t+1的预测值可以看成是原先时刻t的预测值与时刻t-1的新的观察值这两者的加权平均.其模型可以表示为:
时间序列的周期性演变是自然、社会中常见的现象,其中季节性的起伏可作为这方面的代表.在社会、经济活动中,季节性变化通常以一年、一个季度、一个月或者一周为周期.例如,每年商店出售空调,在夏季达到一年的高峰,年复一年都呈现这样的规律,这是由于夏季温度高的缘故.在时间序列中用于处理周期性时间序列的模型主要有两类:季节性水平模型和季节性交乘趋势模型.
20世纪70年代G.E.P.Box和G.M.Jenkins的TimeSeriesAnalysis:ForecastingandContorl 一书的问世,对时间序列分析方法应用产生了很大的影响.该书作者提出用简单的差分自回归滑动平均模型(ARMA)来分析时间序列资料,并用它来进行预报和控制.与前面介绍的平稳时间序列、周期时间序列模型相比,Box-Jenkins的建模方法在数学上较为完善,预测的精度较高.
ARMA建模的思路是:假设所研究的时间序列是由某个随机过程产生的,用实际统计序列去建立、估计该随机过程的自回归滑动平均模型,并用此模型求出预测值.可见,时间序列分析包括以下步骤:分析时间序列的随机特性;用实际统计序列数据构造预测模型;根据最终所得到模型作出最佳预测.
在进行时间序列分析组建预测预报模型时,往往希望模型具有更强的代表性,既包括p阶自回归,又包括q阶移动平均的混合模型.这样的模型称为自回归-移动平均模型,有如下形式:
上式左边是模型的自回归部分,非负整数p称为自回归阶次,实参数(Φ1,Φ2,…,Φp)称为自回归系数;右边是模型的移动平均部分,非负整数q称为移动平均阶次,实参数(θ1,θ2,…,θq)称为移动平均系数.其中参数估计可以通过最小二乘估计、最小平方和估计、极大似然估计等方法迭代求出参数的估计值.一般可以通过统计软件进行求解,比如SPSS,DPS等软件.在DPS 软件中,集成了时间序列的求解模块,可以直接用该软件求解.
例6-8 旅游需求的预测预报
我国的旅游资源极其丰富,是一个国际旅游大国.合理规划、正确地预测和预报旅游需求,对于促进我国各地区的经济发展和文化交流有着重要意义.
现在要求选择合适的旅游城市或地区,对旅游需求的预测和预报建立数学模型,来帮助有关部门进一步规划好旅游资源.具体地说:
1.对所选的旅游城市或地区,根据能够查到的关于旅游需求的预测预报资料,并结合从相关旅游部门了解到的情况,分析旅游资源、环境、交通、季节、费用和服务质量等因素对旅游需求的影响,建立关于旅游需求预测预报的数学模型.
2.可以利用国内外已有的与旅游需求预测预报相关的数学建模资料和方法,分析这些建模方法能否直接移植过来,作出合理、正确的预测预报;如果不行的话,请对这些方法的优缺点作出评估,并提出改进的办法.
【解题思路】
由于我国旅游数据统计不完善,影响旅游的因素错综复杂,想找到影响预测的主要因素比较困难,用时间序列法进行客流量预测,在移动平均法的基础上,利用一次指数平滑技术,分别用不同的权,得到三组预测值.影响旅游需求的因素涉及客源地、目的地等诸多因素,如人口规模、个人可支配收入、旅游资源丰度、吸引力、供给形象、距离、旅游价格、交通费用等.
设时间序列为y1,y2,…,yt,…;简单移动平均公式可以表示为:
Mt为t期移动平均数,N为移动平均数的项数.这公式表明当t向前移动一个时期,就增加一个新近数据,并同时去掉一个远期数据,得到一个新的平均数.由于它不断地“吐故纳新”,逐期向前移动,所以称之为移动平均法.
由于可以平滑数据,清除周期变动和不规则变动的影响,使长期的趋势显示出来,因而可以用于预测.预测公式为: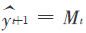 ,即以第t期的移动平均数作为第t+1期的预测值.
,即以第t期的移动平均数作为第t+1期的预测值.
S(1)t实际上是时间序列y1,y2,…,yt,…的加权平均,加权系数依次为a,a(1-a),a(1-a)2,….按几何级数衰减,越近的数据,权数越大,越远的数据,权数越小,权数之和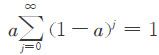 ,符合指数规律,又具有平滑数据的功能.
,符合指数规律,又具有平滑数据的功能.
预测模型为 ,也就是以第t期的平滑值为第t+1期的预测值.
,也就是以第t期的平滑值为第t+1期的预测值.
在指数平滑法中,加权系数的选择很重要,a的大小规定了新的预测值中新的数据和原预测值所占的比重.a值越大,新的数据所占的比重就越大,原预测值占的比重就越小,反之亦然.可得: .
.
可以看出,新的预测值是根据预测误差对原预测值进行修正得到的.a值的大小体现了修正的幅度,a值越大,修正幅度越大;a值越小,修正幅度越小.因此,a值既代表预测模型对时间序列数据变化的反应速度,同时又决定了预测模型均匀误差的能力.
在预测过程中不考虑任何新的信息,若选取a=0,则 ,即下期预测值就等于本期预测值.若选取a=1,则
,即下期预测值就等于本期预测值.若选取a=1,则 ,即下期预测值就等于本期观察值,完全不相信过期的信息.这两种极端情况很难作出正确的预测.因此a值应根据时间序列的具体性质,在(0,1)中选择.具体如何选择一般可按以下原则:波动不大并且比较平稳,则a值应取小一点,如0.1~0.3,以减少修正幅度,使预测模型能包含较长时间序列的信息;如果时间序列具有迅速且明显的变动倾向,则a值应取大一点,如0.6~0.8,使预测模型的灵敏度高一些,以便能迅速跟上数据的变化.在实际应用中,可多取几个a值进行试算,看哪个误差小,就用那一个.
,即下期预测值就等于本期观察值,完全不相信过期的信息.这两种极端情况很难作出正确的预测.因此a值应根据时间序列的具体性质,在(0,1)中选择.具体如何选择一般可按以下原则:波动不大并且比较平稳,则a值应取小一点,如0.1~0.3,以减少修正幅度,使预测模型能包含较长时间序列的信息;如果时间序列具有迅速且明显的变动倾向,则a值应取大一点,如0.6~0.8,使预测模型的灵敏度高一些,以便能迅速跟上数据的变化.在实际应用中,可多取几个a值进行试算,看哪个误差小,就用那一个.
一般来说初始值对以后的预测值影响比较大,这时需要研究如何正确确定初始值.最简单的做法是取最初几期的平均值作为初始值.以印度1995—2004年来华旅游的人数为例,分别取a=0.2,0.5,0.8,得到预测值如表6-11所示.
表6-11 印度近10年来华人数(万)预测表
由表6-11得到年度平均误差0.359,0.261,0.204,误差较大,预测值偏小,把预测值加上误差值,进行两次调整: ,得到调整表6-12.
,得到调整表6-12.
表6-12 印度近10年来华人数(万)调整表
由表6-12可知,在两次误差调整以后,不考虑2003年非典的影响,在a=0.8时,近年的误差在5%左右,效果良好.即使有了2003年的影响,2004年的误差也只有5%,基本没有受到奇异点的影响.
仅用时间序列的一次指数平滑预测一种方法来解决该问题略显单薄,它忽略了影响旅游流的其他因素,直接对客流量进行预测,并根据相近几期的差异来平滑近期数据,使预测值接近真实值.但是预测有其本身的滞后性,存在一定的误差.所以还应对模型进行进一步探讨分析,例如其他指标和因素的影响,建立某种评价指标等.
下面利用时间序列分析模型对北京市旅游需求进行预测.
线性指数平滑方法是一种重要的时间序列预测法,它的基本思想是先对原始数据进行处理,处理后的数据称为平滑值,然后再根据平滑值计算构成预测模型.该模型可以克服移动平均方法对最近N个观察值等权看待的不足,通过将各期观察值按时间顺序加权的方法可以从最近的观察值中提取更多关于未来的有用信息.根据平滑次数的不同,可以分为一次指数平滑、二次指数平滑、三次指数平滑等,在本模型中重点运用较为常见的二次指数平滑方法.其基本的计算方法如下:对于一组时间序列{yi}(i=1,2,…,T),其一次指数平滑值、二次指数平滑值表示如下:
其中α为加权系数,一般地,0<α<0.3.
针对预测问题,运用线性趋势的指数平滑方法,其预测模型为:
运用上述方法对1978—2000年海外来京旅游人数(如表6-13所示)进行时间序列分析,利用线性指数平滑方法预测2001—2005年人数相对误差如表6-14所示,对2001—2005年的旅游人数进行预测得到线性趋势如图6-4所示.
表6-13 1978—2005年北京接待海外旅游人数(万)表
表6-14 线性指数平滑方法预测2001—2005年人数相对误差
图6-4 2001—2005年旅游人数线性指数平滑方法预测
计算结果表明,最后5年的预测相对误差较大,主要是出现奇异点(如1989年旅游人数)时,线性指数平滑模型无法及时调整加权系数造成的,同时奇异点的出现造成了相对误差的平均化.为克服这一点,下面对模型进行改进.
所利用的方法是在二次指数平滑方法的基础上,不断根据反馈信号来调整加权系数,使预测模型更加符合实际变化规律.其基本思想是:在每一个周期t,定义两个误差信号:Et=γet+(1-γ)Et-1,At=γet+(1-γ)At-1,其中Et为平滑误差,At为平滑绝对误差,et=yt ,为t-1时期对t时期的预测值,γ也是加权系数,一般取γ=0.1或0.2.
,为t-1时期对t时期的预测值,γ也是加权系数,一般取γ=0.1或0.2.
定义t期跟踪信号Ct为: ,由于预测误差et完全由随机误差造成,因此可认为et服从均值为0的正态分布,则E(Et)=0.故在模型正确的情况下,有Ct∈-1,1.令α=Ct,这样加权系数α就可以根据Ct的变化进行逐期自动调整,使预测模型不断适应实际过程的变化.通过此方法对2001—2005年海外来京人数做出预测误差如表6-15所示.
,由于预测误差et完全由随机误差造成,因此可认为et服从均值为0的正态分布,则E(Et)=0.故在模型正确的情况下,有Ct∈-1,1.令α=Ct,这样加权系数α就可以根据Ct的变化进行逐期自动调整,使预测模型不断适应实际过程的变化.通过此方法对2001—2005年海外来京人数做出预测误差如表6-15所示.
表6-15 自适应指数平滑方法预测2001—2005年人数相对误差
自适应指数平滑方法在不出现奇异点时,预测值与真实值相当接近.但是当特殊情况出现时,自适应指数平滑方法对真实情况的反映仍然比较欠缺,甚至自适应能力出现较大波动.
自回归模型的基本思想是将当前值看做是过去观测值yt-1,yt-2,…,yt-p的线性组合.基本形式表示为:y=Φ1yt-1+Φ2yt-2+…+Φpyt-p+εt.
其中Φ1,Φ2,…,Φp为模型参数;εt为白噪声序列且εt~N(0,σ2ε)反映其他随机因子的干扰.
移动平均模型的基本思想是当前值yt看做是过去各期白噪声εt-1,εt-2,…,εt-p的线性组合.基本形式表示为:yt=εt-θ1εt-1-θ2εt-2-…-θqεt-q,其中θ1,θ2,…,θq为模型参数.
自回归移动平均模型在建立一个实际时间序列的模型时,常可以把前两种模型结合起来,得到ARMA 模型.一般情况下,p,q≤3.该模型的基本式为:yt-Φ1yt-1-Φ2yt-2-…-Φpyt-p=εt-θ1εt-1-θ2εt-2-…-θqεt-q.
积分自回归移动平均模型是在实际情况中时间序列常常出现一种不稳定性,即齐次非平稳性.可以通过对这样的时间序列进行一次或者多次差分,就可以将非平稳时间序列转化成平稳时间序列.
定义差分算子: ,则差分算子与移位算子之间存在以下关系:
,则差分算子与移位算子之间存在以下关系: ,同样高阶差分可以表示为
,同样高阶差分可以表示为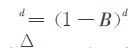 .
.
对于参数d的确定通常运用观察法使差分后的序列保持平稳,一般地,d≤2.对于p,q的确定,常常通过模式识别的方式对ACF(自然回归系数)和PACF(偏相关系数)的分析,确定p,q的可能取值.通过对p,q的有限组合,计算出各组的AIC(信息准则拟合优度)或SBC(贝叶斯准则拟合优度)值,最后取出拟合优度最小的p,q组合.
在本模型中,首先通过差分的方法使研究的时间序列成为稳定性时间序列.通过观察,当d=2时,处理后的时间序列保持平稳.运用SPSS软件可以得到ACF、PACF 图,根据这两个图可以得出可能的p,q组合.通过对可能的p,q进行组合得到的结果如表6-16所示.
表6-16 不同p,q,d组合的AIC值
可以看出,(1,2,1)ARMA的AIC值最小.因此本模型中确定的参数为p=1,d=2,q=1.此时,表达式对应系数为Φ1=-0.29,θ1=0.952,常数项c=0.511.
ARMA方法预测计算出2001—2005年预测相对误差如表6-17所示.
表6-17 ARMA方法对2001—2005年预测人数相对误差
ARMA方法从精度上有如下优势:
●当趋势平稳,不出现奇异点时,预测结果与真实值较为接近;
●奇异点出现时,ARMA方法可以及时调整,使今后几年的预测误差迅速降低,其适应性较自适应指数平滑方法更加明显.
在实际预测中,为了使预测更加准确,决策者往往要考虑实际情况,对奇异数据进行处理,称这种方法为“滤波”.在本模型中,通过较为简单的线性插值的方法对1989年和2003年的数据进行“滤波”处理,并用自适应指数平滑方法和ARMA方法对处理后的数据进行再预测.数据滤波后指数平滑方法和ARMA方法的预测值对比差如表6-18所示.
表6-18 数据滤波后指数平滑方法和ARMA方法的预测值对比差
针对数学建模问题中的随机类问题,本章先后介绍了一般概率模型、排队论模型和时间序列模型.在实际生活中充满了随机不确定性问题,在全国大学生数学建模竞赛中虽然排队论、时间序列问题并不常见,但是作为基本模型的一种,还是需要各位掌握的,尤其是排队论模型与时间序列模型非常重要.时间序列主要用于预测,也可以作为第1章内容的补充.随机数学内容非常丰富,它包括概率论、随机过程、数理统计等有关随机性的实际问题,涉及面非常广,本章和下一章只涉及一些随机数学的基本内容和实例,感兴趣的学生可以进一步参考相关书籍.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









