



5.6.1 声纹识别简介
声纹(Voice Print)是用电声学仪器显示的携带言语信息的声波频谱。人的语言产生是人体语言中枢与发音器之间一个复杂的生理物理过程,身体在讲话时使用的器舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。每个人的语音声学特征既有相对稳定性,又有变异性,不是绝对的、一成不变的。这种变异可以来自生理、病理、心理、模拟、伪装,也与环境干扰有关。
声纹识别(Voiceprint Recognition简称“VPR”),也称说话人识别,就是根据人的声音特征,识别出某段语音是谁说的。声纹识别分为话者辨认和确认。辨认是从有限的话者集合中分辨不同的人,系统性能随着话者集合增大而降低;确认是系统只给出接受或拒绝两种选择。从电视讲话判定说话人,如萨达姆是否是其本人,就属于确认的过程,它的难度往往更大一些。
声纹识别类似于指纹识别。指纹经过数字化处理以后,以人的手指表面皮肤纹理图像的形式存储于计算机。假如我们从犯罪现场提取罪犯的指纹,然后和计算机的存储资料对比,或者与嫌犯的指纹对比,就可以确定罪犯的身份或者犯罪证据。同样声音也携带着每个说话人的个体信息。所谓声纹是指能唯一识别某人或某物的声音特征。例如,在上面的例子中,无论萨达姆在何时、何地发表不同内容的讲话,他的声纹始终是不变的,因此可以此断定一种声音是不是其本人发出的。当然,是事先录好还是现场直播,则另当别论。
然而,只是理解声纹还是不够的,人们还需要准确地知道声纹的具体参数,才能准确地从很多人中辨认出说话者是谁,或者是什么东西发出的声音。如何提取声纹,怎样提取才能保证识别的准确性,有了声纹如何比对,怎样处理和分离海量声频数据中的其他不相关信息,都是这项技术实现的难点。
其实声纹识别(Speaker Recognition)是一种广义的语音识别。在司法、公安、通信、机要等领域具有重要的应用价值。近年来,这一技术发展迅速,已经出现了一些实用系统。
目前,声纹识别一般利用包含话者语音波形中特有的个体信息(声纹),自动识别话者身份。从学术研究的角度上讲,它属于统计模式识别和人工智能应用领域。
从处理的语言内容上看,声纹识别又分成限定文本和非限定文本两种。如果说无论美国总统布什说什么,系统都能认出是他而不是别人,这就是非限定文本识别,这种识别更难一些。目前最流行的用于识别的短时谱特征是LPC(Linear Predictive Coefficients)及MFCC(Mel Frequency Cepstral Coefficients)。当然技术的发展有两面性,伴随语音技术的发展,伪装语音或伪装声纹技术也有相应的进步,所以才需要人们去认识和把握一项科技的应用。
一般的声纹识别过程如图5-22所示。
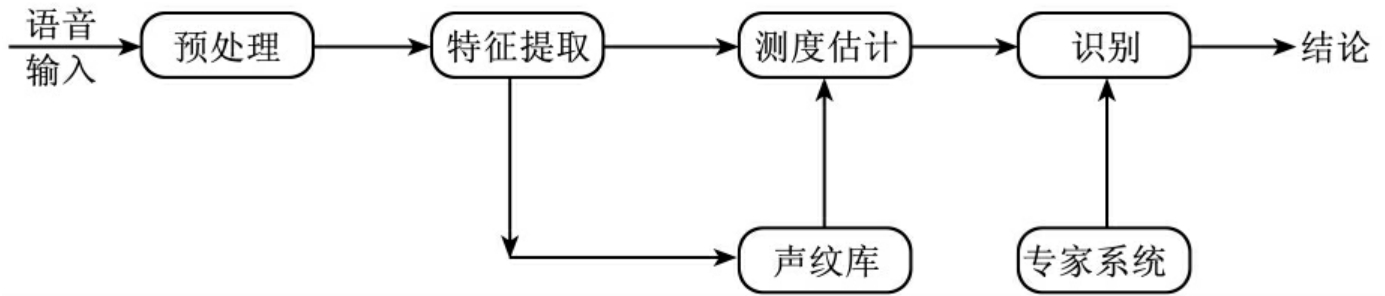
图5-22 声纹识别的一般过程
我们需要一份想要识别的人的原始语音信号作为对照,而这段语音信号必须经过声纹提取,形成一个模板,才能与下一次的输入做比较,从而判断是不是要找的人。
那么构成声纹的参数有哪些呢?从已有的研究可以归纳为短时频谱、基音周期、短时能量、短时过零率、倒谱、LPC参数和MFCC参数。
语音信号是一种典型的时变信号。如果把观察时间缩短到十毫秒或几十毫秒,则语言信号是近似平稳的,这是由于人的发音器官不可能是毫无规律地快速变化。例如,具有重大意义的LPC参数,就可以非常好地表达人的发音过程,即所谓的声管模型。这些参数的计算也往往基于语音信号的短时信息(帧)。如果把它们配合使用,则可以大大提高识别效率和准确性。目前主要的难度在于能不能找到、发现可唯一标识某人或某物的这组参数,而且这组参数还是在开集条件下不限定文本的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










