



3.2.2 面像识别算法
目前面像识别的算法可以分类为基于人脸部件的多特征识别算法(MMP-PCA recognition algorithms)、基于人脸特征点的识别算法(Featurebased recognition algorithms)、基于整幅人脸图像的识别算法(Appearancebased recognition algorithms)、基于模板的识别算法(Template-based recognition algorithms)、利用神经网络进行识别的算法(Recognition algorithms using neural network)。
1.基本算法-局部特征分析
任何一个面像识别系统的基本要点是如何将面像进行编码。面像识别技术使用局部特征分析LFA来描述面像图像,它源于类似搭建积木的局部统计的原理。LFA是基于以下事实的一种计算方法,即所有的面像(包括各种复杂的式样)都可以从由很多不能再简化的结构单元子集综合而成。这些单元使用了复杂的统计技术而形成,它们代表了整个面像。它们通常跨越多个像素(在局部区域内)并代表了普遍的面像形状,但并不是通常意义上的面像特征。实际上面像结构单元比面像的部位要多得多。
然而,要综合形成一张逼真、精确的面像,只需要整个可用集合中很少的单元子集(12~40特征单元)。要确定身份不仅仅取决于特性的单元,还决定于它们的几何结构(比如它们的相关位置)。
通过这种方式,LFA将个人的特性对应成一种复杂的数字表达方式,可以进行对比和识别。
2.当前的水平
已有好几个算法声称在很小约束的情况下仍有精确的性能。为了更好地评价这些算法,美国国防部高级研究计划局和陆军研究实验室建立了FERET计划,目标是既评估它们的性能又鼓励技术进步。到2000年1月21日,已有三种算法在大数据库和双盲检测条件下展示了它们最高的识别精度。这些算法来自南加利福尼亚大学、马里兰大学和麻省理工学院媒体实验室。他们都加入了FERET计划。其中两个算法,也就是南加利福尼亚大学和麻省理工学院媒体实验室研制的,能在最小的限制下实现检测和识别,而其他的则要求告知眼睛的大致位置。第四种算法是洛克费勒大学开发的,早期曾是竞争者之一,从测试中淘汰后转向商用。南加利福尼亚大学和麻省理工学院媒体实验室的算法也是商业系统的基础。
麻省理工学院、洛克费勒大学和马里兰大学的算法都使用了特征脸变换+判决的模型,如图3-2所示。
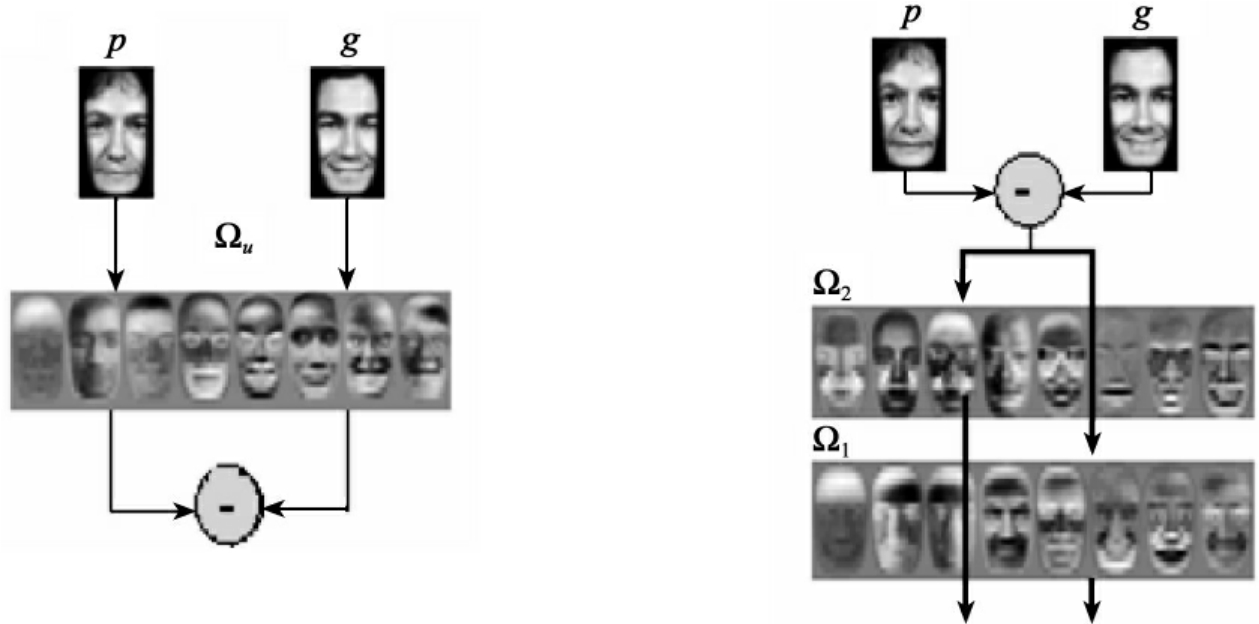
图3-2 面像识别的算法流程
计算距离的流程如图3-2左图所示。第一,建立“标准”面像数据库;第二,对上述数据库中的面像进行主元素分析(PCA)得到本征面像集,分析表明大约100个本征矢量就足以对一大型面像数据库编码;第三,库中每一面像都被表示为本征面像的线性组合;第四,一个待测面像也是本征面像的线性组合;第五,用距离测量估计两面像的相似度。
计算概率值S的流程如图3-2右图所示。首先,计算出内差集(同一个人在不同视角下面像的差异)和外差集(不同人面像的差异);其次,对每一集合执行PCA操作建立各自的本征面像集;最后,由公式S=P(Ωi|Δ)(其中Δ为两个面像间的差异)计算出两个面像的相似度,若S<0.5,则认为两面像属于同一人。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










