



5.2.3 经验费率法
经验费率法是APH方法的一种改进,其基本思想在于通过某种方法求得历年农作物产量的理论值(预测值),然后根据历年实际产量与理论产量的差求得历年农作物产量的损失,进而求得农作物区域产量保险的经验费率。经验费率方法主要根据如下的社会损失率来确定保险费率,即首先根据某种方法得到历年农作物产量的趋势值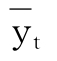
![]()
作为相应年度农作物产量的理论值,进而得到相应年度的农作物产量保险的保障产量为yc,若该年实际产量为yt,则相应年份农作物产量的社会损失率为:最后得到第T年该种农作物产量的平均社会损失率为:
![]()
用平均社会损失率L作为相应的保险费率的近似值。
经验费率方法的主要问题在于农作物生产理论产量的确定。通常理论产量是通过历年农作物产量时间序列的趋势值来确定的。
对农作物产量时间序列长期趋势的统计处理是一件十分麻烦的工作,通常存在确定趋势和随机趋势两种。
5.2.3.1 正态条件下的趋势方程
(1)线性确定趋势下的理论产量。
对农作物产量确定趋势的设定实际上是一个统计或计量经济模型设定的问题。在实际应用的过程中,确定趋势条件下的理论产量趋势的确定存在着三个方面的问题:一是趋势方程的设定偏误;二是趋势方程的拟合方法;[1]三是样本数据的预处理。[2]
确定性趋势确定的最简单的方法莫过于线性趋势方程。假定Yt是某区域某种农作物单位面积的平均产量,t=1,2,3,…,T;并假定Yt遵循如下的线性趋势模型:
![]()
其中,εt服从均值为0,方差为σ2的正态分布。根据某种准则进行拟合(OLS),得到参数a与b以及σ2的估计值。利用外推法可得到历年农作物产量的理论值及其分布,因而可以得到费率厘定年T+1时期的该区域这种农作物单位面积产量的理论平均值yT+1及其分布为N(yT+1,σ2),进而求得期望损失EL。当然,农作物区域产量的线性模型不一定是好的选择(刘长标,2000),非线性的可能更好,只是公式复杂一些而已。
(2)具有状态转移的随机趋势条件下的理论产量。
由于农业生产的过程是自然过程和社会经济过程的有机结合的体系,因此,农作物的生长过程必然受到两种状态的制约:一种是农作物生长的自然条件;一种是社会经济及技术状态。区域农作物平均单产量不论是增长还是波动都是由这两种状态所决定的。一般情况下,农作物产量长期趋势的变化主要受制于社会经济发展、科技水平的进步以及自然条件的改善,而农作物产量分布的方差则是由于这两种状态波动的结果造成的。如果这两种状态比较正常,则农业生产必然处于正常状态;如果社会经济及科技水平的变化不大,而自然条件发生极大的变动,则农作物产量增长的趋势方程中的增量系数b会相对稳定,而扰动项的波动性将会加大。如果自然状态正常,而社会经济及技术条件发生极大变化,则相应的产量的增长率会发生变化,在这种条件下,增量系数b也会由于这种增长率的变化而成为随机项,当然这也会引起农作物产量的波动性。
正是由于上述农作物生长的物理过程及其所反映的特点,在区域农作物产量保险精算的APH方法中,我们可以考虑引进具有状态转移的随机趋势模型来反映农作物产量的长期变化趋势。具有状态转移的随机趋势模型在数学中的应用很广泛。首先将其引入农作物产量时间序列分析的是Menz和Pardey(1983),而1991年Kaylen和Koroma则利用农作物产量时间序列数据正式估计了随机趋势方程。
时间序列的随机趋势模型包括两个方程,一个是测量方程,反映时间序列变量的变化趋势受状态变量的影响状况;另一个是状态方程,反映隐含的状态变量的变化状况。一般模型为:
![]()
第一个方程为测量方程,第二个方程为状态方程,其中yt,t=1,2,3,…,T为所分析的时间序列;d为常参数;z为1×M的系数向量;αt为M×1的状态向量;N为N×M的系数矩阵;c为1×M的常向量;εt为随机变量;γt为M×1随机向量,且满足:E[γt]=0,E[εtγt]=0,E[γtγTt]=Q,式中的上标T表示转置。
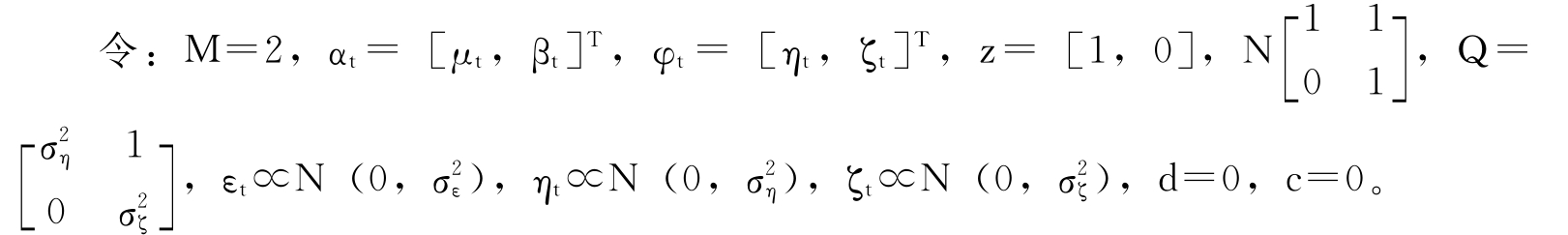
则得到我们所说的区域农作物产量的具有状态变化的随机趋势模型:

对上述随机趋势模型的参数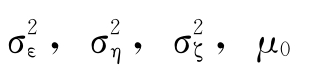 和β0根据极大似然方法进行估计,[3]经过外推就可以得到相应的理论产量值;在此基础上可求得相应APH方法的期望损失。
和β0根据极大似然方法进行估计,[3]经过外推就可以得到相应的理论产量值;在此基础上可求得相应APH方法的期望损失。
(3)ARIMA模型下的理论产量。
线性趋势及随机趋势条件下对APH的改进实际上只考虑了历年农作物依赖于趋势变量即时间的变化状况,而没有考虑农作物产量自身的自回归与滑动平均效果。事实上一个地区旱涝灾害往往一年接一年地发生,因此区域农作物产量的时间序列数据经常表现出自回归与滑动平均的效果。如果同时考虑农作物产量的趋势问题,那么利用ARIMA模型对APH进行改进就很自然且符合逻辑。
在单变量的ARIMA模型中,差分变换可以解释农作物产量时间序列的长期趋势,不同阶数的差分变换反映了农作物产量的线性趋势或多项式曲线趋势,而自回归与滑动平均则反映了农作物产量历年数据的自相关问题。因此,可以利用ARI-MA模型估计农作物产量的趋势值。
5.2.3.2 非正态条件下的趋势方程
农作物产量分布的非正态性早就被研究者发现。1965年Day研究农作物产量分布时指出农作物产量适合用具有负偏的Beta分布来拟合;Gallagher(1987)在研究美国大豆产量分布时使用了具有正偏的Gamma分布;Nelson和Preckel(1993)提出了所谓的条件Beta分布;Moss和Shonkwiler(1993)则提出了所谓的逆双曲线正弦分布。下面简单介绍几种非正态分布:
(1)两参数Gamma分布变量Y的分布密度函数为:

其中形状参数α和刻度参数β皆大于0。
(2)三参数的Beta分布的随机变量Y的分布密度为:
![]()
其中B(a,b)为参数为a与b的Beta函数。如果y为某种农作物的单位面积的平均产量,则m为一定技术条件下的最大产量。显然,Y/m服从两参数的Beta分布,其密度函数为:
![]()
如果令扰动项服从Gamma分布或Beta分布,可通过极大似然估计得到相应的未知参数,进而得到农作物生产历年的理论产量,然后可得到相应的农作物产量的平均损失率,进而得到保险费率。
实际上,非正态条件下的具有状态转移的随机趋势模型也是对随机项进行了所谓的逆双曲线正弦分布而建立的:
![]()
在得到相应的参数估计后,可以根据上述公式得到相应的农作物产量的平均损失率,进而得到相应的保险费率。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










