



7.2.2 CRM中的数据存储
中国银行业早在20世纪80年代初就开始了客户信息的收集工作,近年来推行的“数据大集中”更为银行业实现统一管理提供了良机。目前,我国各大银行建立的数据存储体系基本上是各分行、各部门原有MIS系统和数据的集市。
数据集市(独立数据集市)也被称为部门级数据仓库,往往是针对特定部门的业务需求而设计的。数据仓库与数据集市都是用来进行决策支持与数据分析的,两者之间的差别并不在于数据量的多少与系统规模的大小,而是体系结构之间的区别。当银行为多个部门建立数据集市之后,这些数据集市彼此之间相互独立,具有不同的数据存储模型。而当前推行的银行“数据大集中”往往指的是交易处理的集中,它仍然按照业务的不同而分成不同的业务处理子系统,彼此之间相对独立。独立数据集市的逻辑结构如图7-1所示。
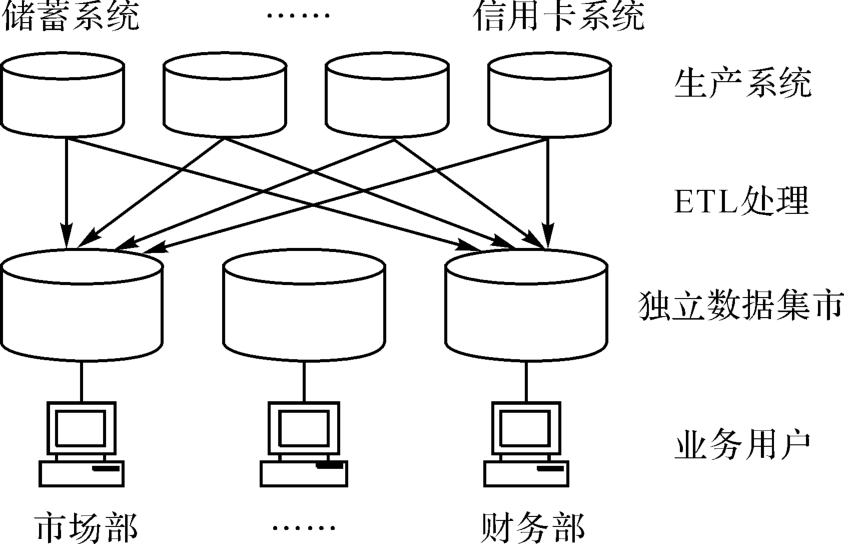
图7-1 独立数据集市的逻辑结构
这里把用于数据分析与决策支持的数据集市与业务处理系统物理上分离,通过ETL流程(Extraction、Transformation、Loading)把业务系统中的数据经过清洗与整理后加载到数据集市。CRM业务用户通过OLAP工具直接访问数据集市中的信息来生成多维报表或者其他信息分析。
在这种结构中,IT人员必须针对每个数据集市设计独立的ETL处理程序,把各生产系统的操作数据按照需要分别转换到每个独立数据集市中。显然,这种策略将使整个系统变得非常复杂和难于维护,在投资方面也是得不偿失的,因为实践证明硬件系统的投资呈比例增加,软件方面的投资和维护则呈指数形式增加。
这种结构最主要的问题还是在于没有统一的企业数据存储模型,不能为企业提供统一的信息视图。由于难以保证各数据集市之间数据的一致性,经常会出现不同数据集市对同一个CRM业务问题或分析产生不一致的结果,使决策人员无所适从,而查找这种不一致的原因更是需要花费大量的时间去跟踪。在这样的数据存储体系下,对CRM而言,数据驱动的有效性是很低的。这时,银行实施CRM系统就像是在把银行的整体视图变成一幅拼图,然后把图片分散到不同的业务部门。每个部门都只有局部的信息,决策层如果需要了解CRM信息全貌,就需要花很大的精力消除数据的冗余和不一致,把这些局部信息拼到一起。这种拼图的过程在进行CRM分析时会不断重复,系统在扩展能力上也会受到很大的限制,无法处理大量的数据,导致CRM事倍功半。因此,在形成多个独立的数据集市后,系统的业务价值会大打折扣。
随着数据积累不断增多,如何从聚集在银行数据库里的大量数据中挖掘、提炼并开发出有价值的客户信息,进而转化为可利用的资源和决策依据,实现有效数据驱动式决策支持系统?基于企业级数据仓库的CRM将是银行运营能否取胜的关键。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











