



二、单变量的统计描述
单变量的统计描述是统计分析中最简单的部分,主要是描述其分布情况。下面主要介绍只针对一个变量进行分布描述的主要方法。对一个变量的描述,除了借助上述的统计量之外,更多的是借助一些统计图增强视觉效果。
(一)饼形图
对于定类变量来说,它们只是把不同的选择进行分类,如果要把它的分布用图表示,可以用饼形图(pie chart)。饼形图又叫饼图,是把一个圆饼分割成几个部分,每一部分面积代表相应类的比例大小。饼形图可以显示一个整体分成了怎样的几个部分。因为各部分的面积之和是100%,所以饼形图只能用来表现单选变量的百分数。饼形图可以是平面的,也可以是立体的,也可以突出表现某一个取值的比例。不过一般情况下,不能将圆饼分成太多的部分。例如,图3—5是一个饼形图的例子。[1]
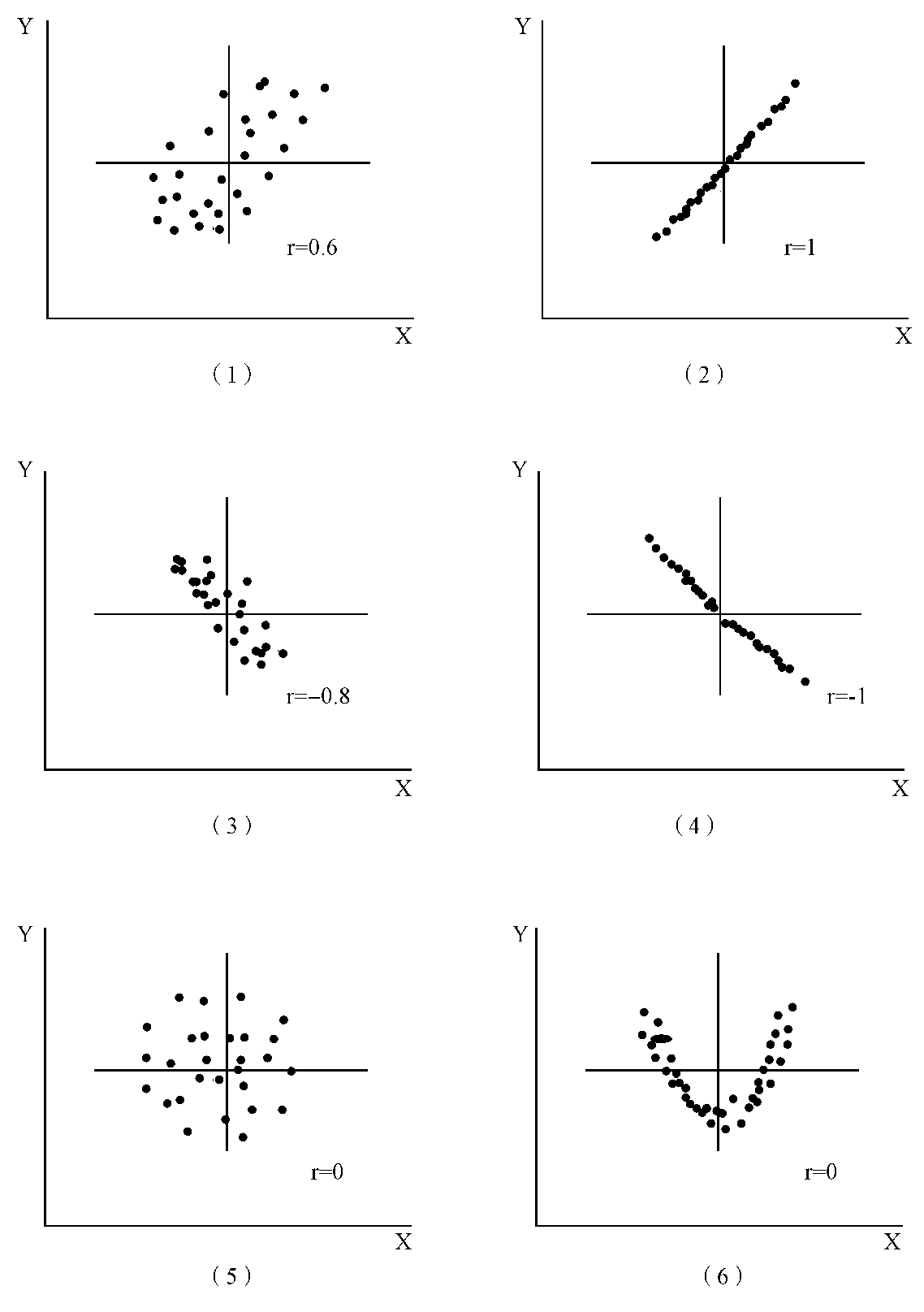
图3—4 相关系数r的直观意义
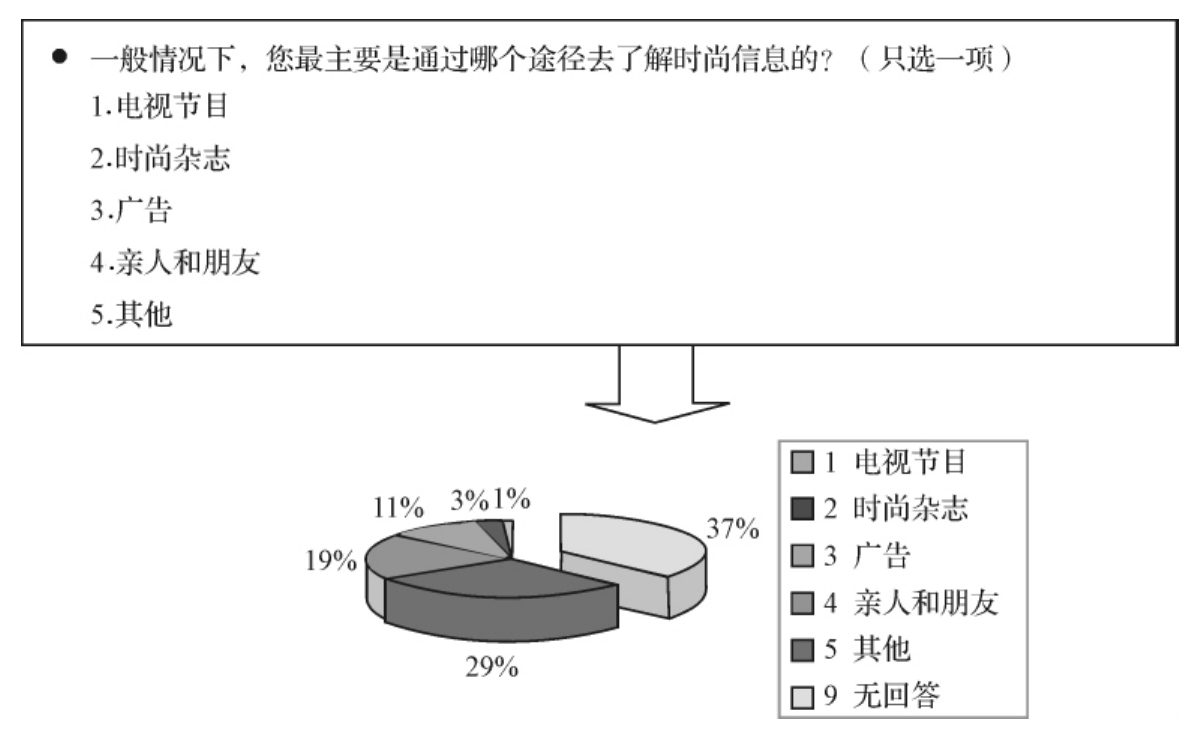
图3—5 白领观众了解时尚信息途径的饼形图
饼形图可以突出最大的部分和最小的部分,但如果想比较各部分的大小,就要比较各部分的面积(圆弧的角度),从直观上说,这不是十分方便的。如图3—5中,选择“电视节目”的37%和选择“时尚杂志”的29%,从图形似乎并不能看出这么大的差异。
(二)条形图
图3—6是用和图3—5同一数据做出的条形图(bar graph)。每个长条的高度显示出该长条底部标示的类别所占的比例。长条可以清楚地显示出:从电视节目获得时尚信息的人比从时尚杂志获得时尚信息的人多,因为它对应的长条比较高。
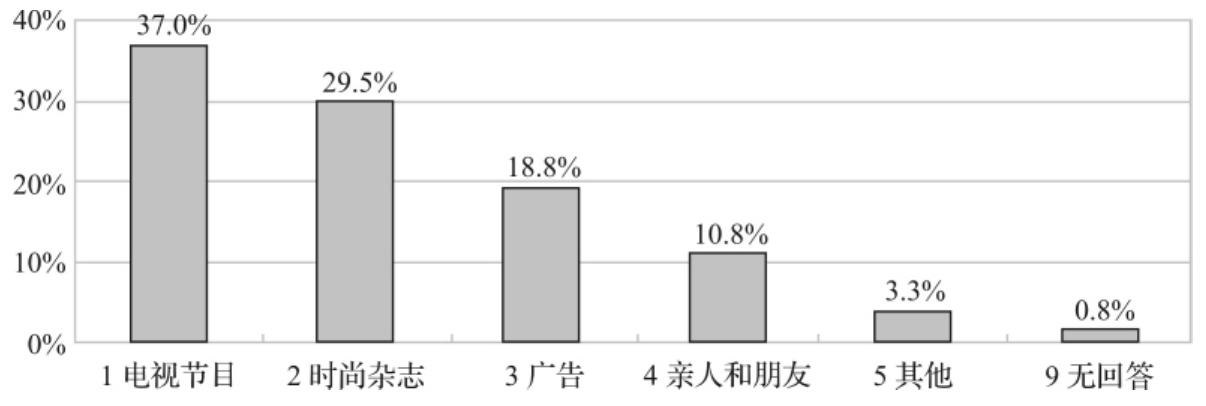
图3—6 白领观众了解时尚信息途径的条形图
饼形图和条形图是描述定性类型变量分布情况的较好工具。相比之下,饼形图更强调各部分的比例和整体的关系,而条形图更强调各部分彼此之间数量大小的比较。当条形图的类目较多时,为了篇幅和美观,可以将条形图做成横条。
此外,条形图还可以比较数值型变量的均值(见图3—7)、表现多选变量的比例(见图3—8),因为并不要求每个长条代表的比例之和等于100%;条形图的最大优势是可以表现一个变量在当另一个变量取不同值时的分布情况,这一点将在稍后的内容中进行讲解。饼形图只能以比例为依据进行做图,而条形图则可以直接用频数进行做图,比如图3—6也可以做成用频数表示的形式,而图的形状不变。
·关于“名人引导时尚”的有关说法,您怎么看?用1~4的数字表示。
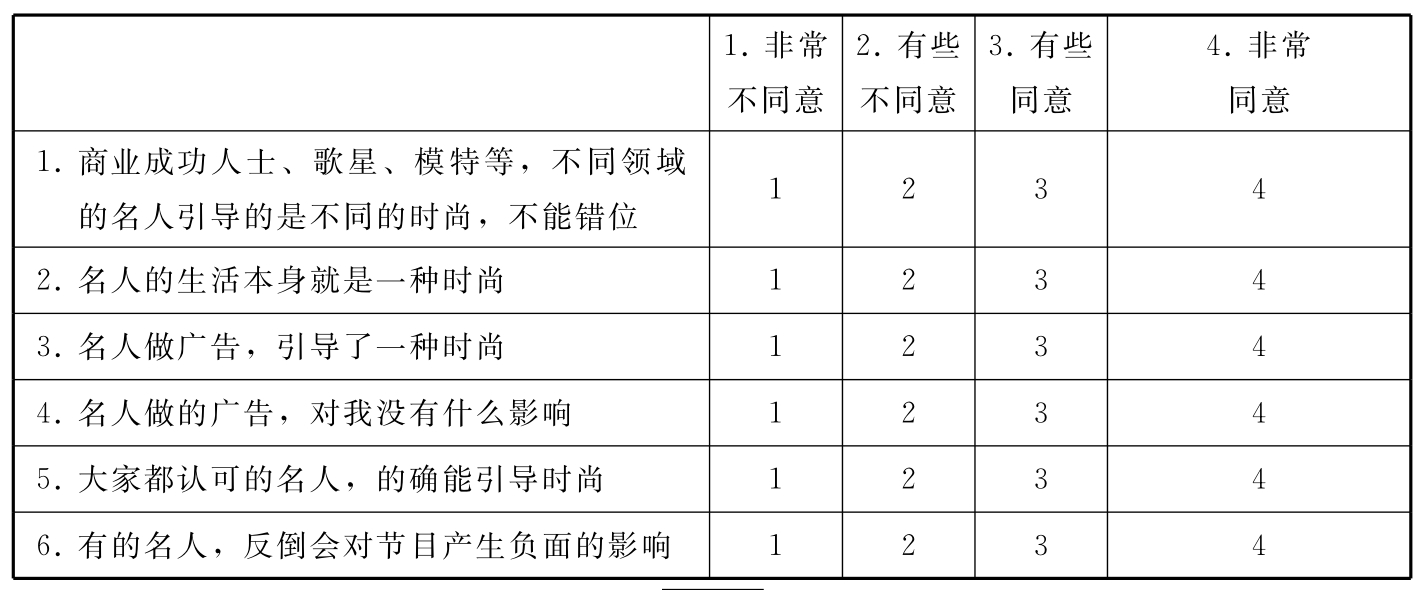
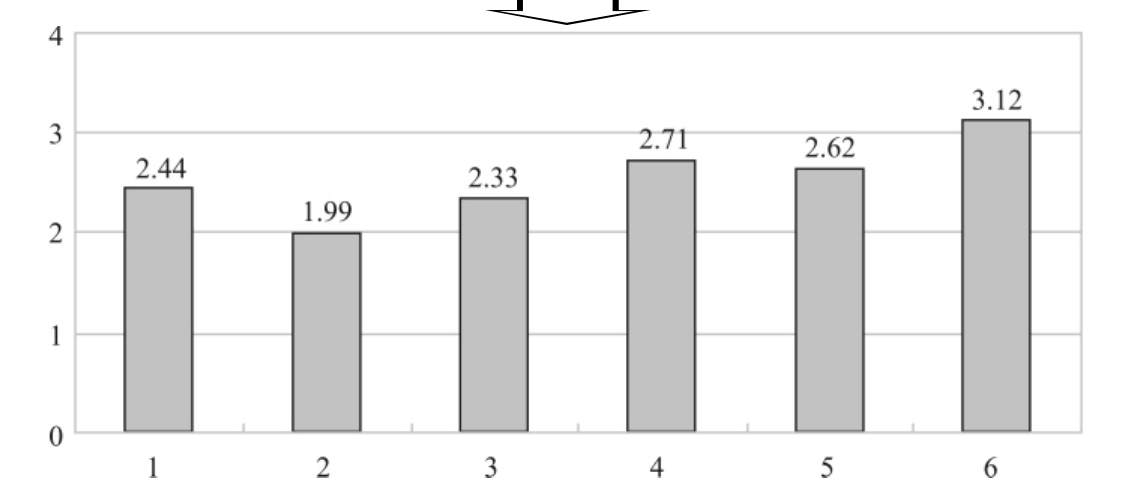
图3—7 白领观众对“名人引导时尚”有关说法的评价(均值)
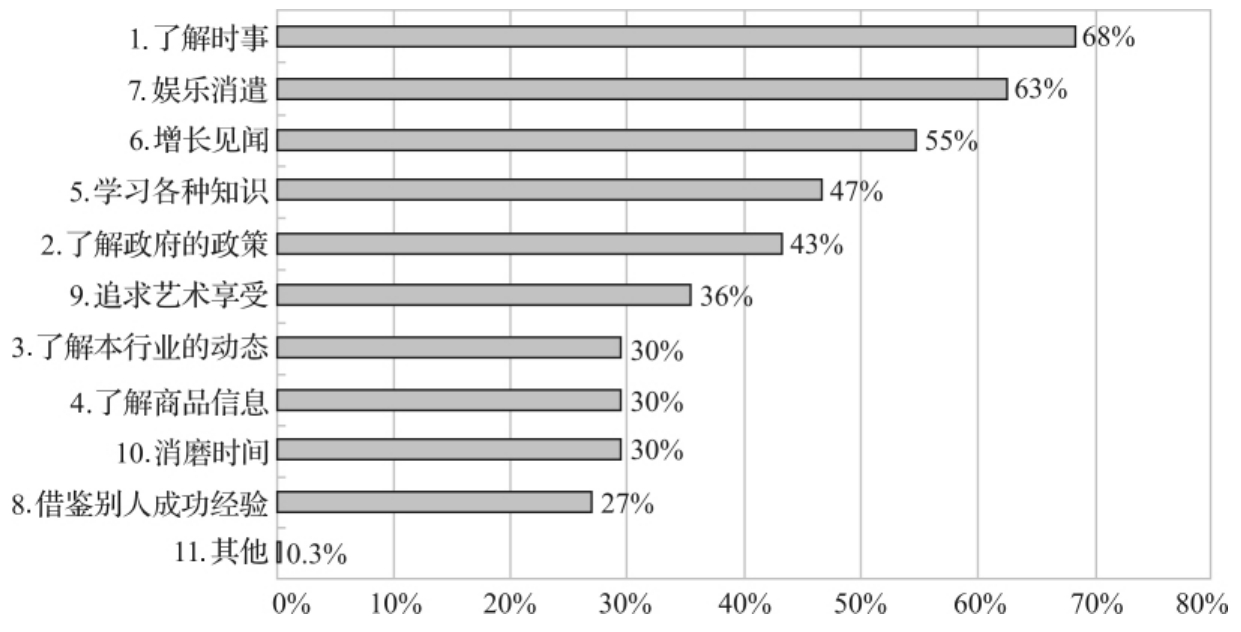
图3—8 白领观众看电视的主要目的(多选结果)
做横条的条形图一般都是因为类目较多,为了看图方便,做图时可以先按比例的大小将这些类目进行排序,否则做出的图形将会显得比较凌乱。
不管是竖条还是横条的条形图,都是一个坐标轴标明分类的类目,另一个坐标轴标明刻度。有时刻度的大小也会影响人们从图中取得正确的信息,比如图3—7中所示的对第4种说法和对第5种说法的评价(分别是2.71、2.62)差别本来是很小的,但如果按照图3—9的做图方式,这种差别就被放大到产生误导的程度了。
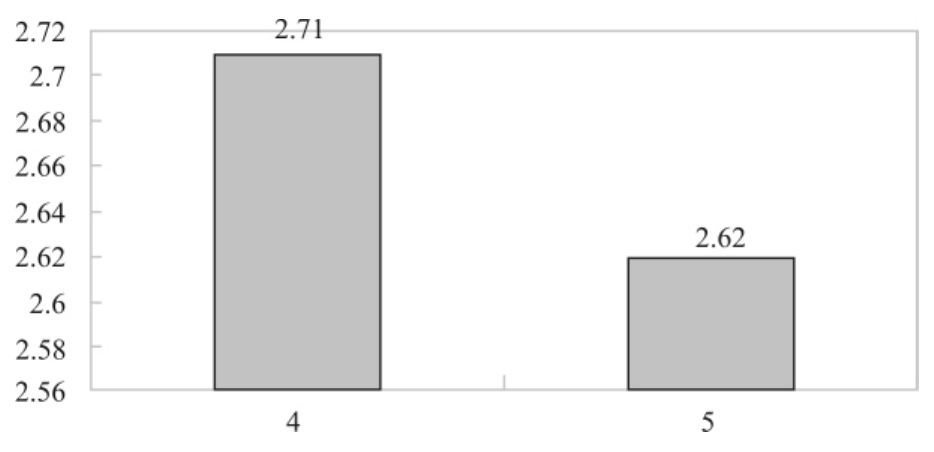
图3—9 一种误导的做图方式举例
图3—9会产生误导是因为把刻度设置得过小,放大了微小的差别。做图时刻度究竟取多大合适,最好是根据假设检验的结果是否要展示这个差距决定,不过有经验的做图者是可以控制得很好的。如何真实地用图形反映数据所要传达的信息,对做图者来说,是要从多方面加以注意的问题;对于看图者来说,注意不要只看图形的表面状况,要有一点质疑的态度,避免蹩脚的做图对自己产生误导。
(三)折线图
折线图(line graphs)可以显示出变量随时间所产生的变化及变化的趋势,时间刻度标示在横轴上,变量的刻度放在纵轴上。图3—10显示了历次中国互联网络发展状况调查中我国上网用户总数的变化情况。可以看出,我国上网用户呈逐年上升趋势,而且增加的幅度也比较大。图3—11则显示了一天不同时间网民上网的比例,可以看出,晚上8点到10点之间是互联网的黄金时间。
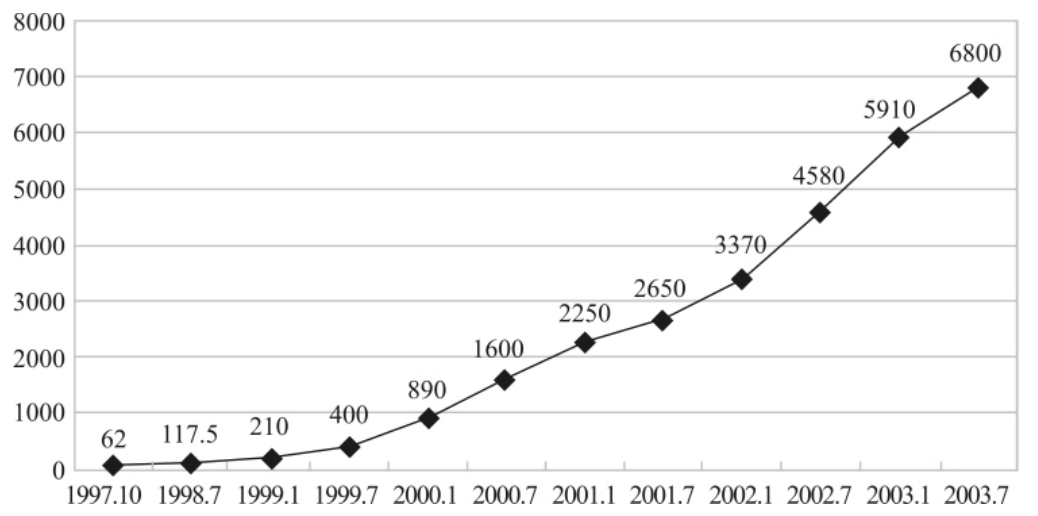
图3—10 我国上网用户总数变化情况(单位:万人)
数据来源:中国互联网信息中心CNNIC,2003年
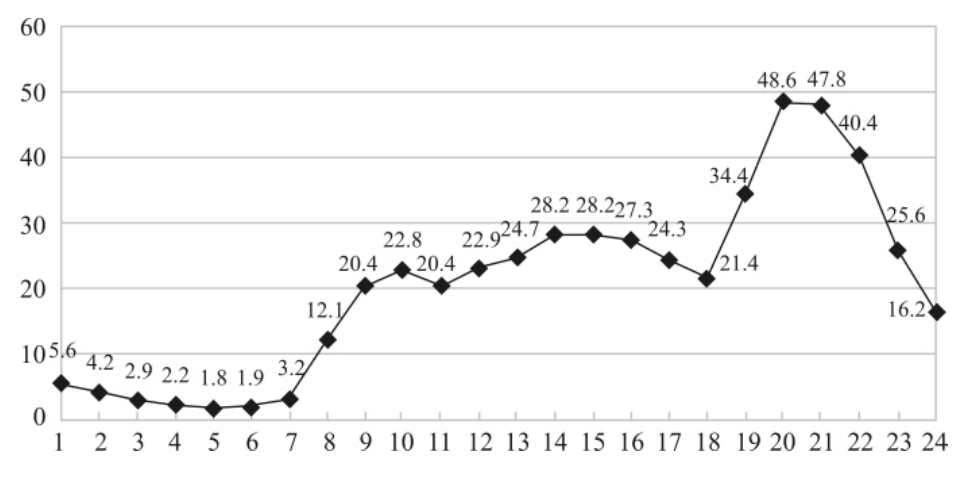
图3—11 在一天的不同时间使用互联网的网民比例(%)
数据来源:中国互联网信息中心CNNIC,2003年。
由于折线图表现的是一种变化的趋势,可以给人以强烈的视觉效果,在做图时就更要注意正确地表现资料的真实信息,尤其要注意刻度的合理性和分类轴间隔的宽窄。比较一下图3—12中的两张图,它们是根据同一数据做出的,在视觉上却有着不同的效果。
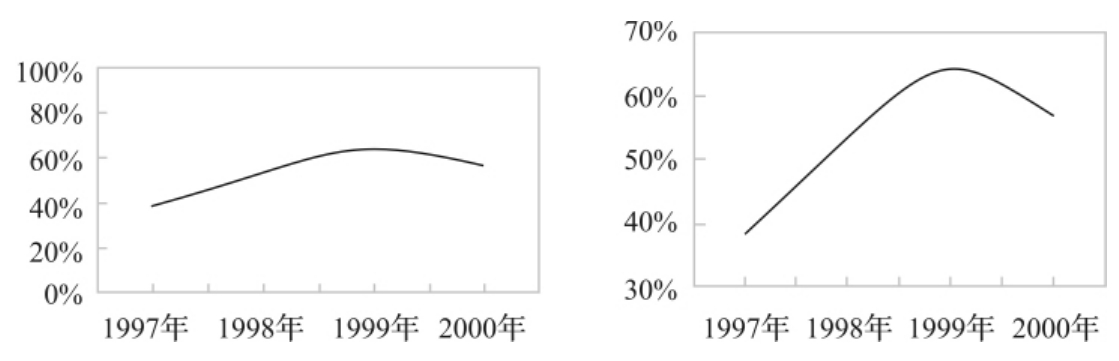
图3—12 1997~2000年中国九个城市对环境问题表示“很关心”的居民比例
数据来源:SSI,1997~2000年IEM世界公众意识研究。
(四)直方图
上面所列举的几种图共同的特点是适用于分类数比较少的情况,如对定类变量或对离散型的数值变量。但当研究的变量是连续型的数值变量(定距变量或定比变量)时,变量的可能取值就太多了,做频数表有时是不可能的或无意义的。这时就需要把临近的值合并成一组,然后就以每组的中间值分类画出分布图,这样做出的表现连续型数值变量分布的图形叫做直方图(histogram)。
假设我们从200个订阅报刊的人中获得了他们平均每月订阅报刊的花费,从5元到83元不等。这里数据的最小值是5元,最大值是83元,可以说数据的“全距=78”。
首先是将这些数值范围分成同样宽度的组(class)。可以把200个观测值分成8组。每一组的长度即组距=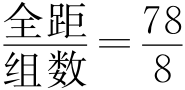 =9.75,不过组距一般取整数比较好,而且一定是要全部数据都包含在各组之中,所以这里组距取10。
=9.75,不过组距一般取整数比较好,而且一定是要全部数据都包含在各组之中,所以这里组距取10。
确定了组数和组距,接下来是确定每组的组限(下限和上限)以及组中值。比如第一组的组限是5和15,组中值= =10,以下各组的组限和组中值只要分别累加组距10即可得到,比如第二组的下限、上限和组中值分别为15、25、20。
=10,以下各组的组限和组中值只要分别累加组距10即可得到,比如第二组的下限、上限和组中值分别为15、25、20。
至于如何分组并没有绝对的标准,组数太少会造成所有值都集中在少数几个组里的现象,而分组太多又会造成很多组只有少数几个观测值甚至没有观测值的结果,这两种选择都不能有效描绘出分布的形状。要展示出分布的形状,最好是根据数据的实际情况选择合适的组数,组数通常在5~15组之间比较合适,而且组距和组中值最好都是整数。
分组之后,就可以统计观测值落入每组的频数,注意每个具体的数据应该归入也只能归入一个组。由于每组的上限和下一组的下限是相同的,因此要事先约定各组中的上限(或下限)属于哪一组。这里我们规定每组的上限不属于该组。分组后每组的频数和相对频率如表3—2所示。
表3—2 200名居民平均每月订阅报刊花费钱数的频数分布表 单位:元
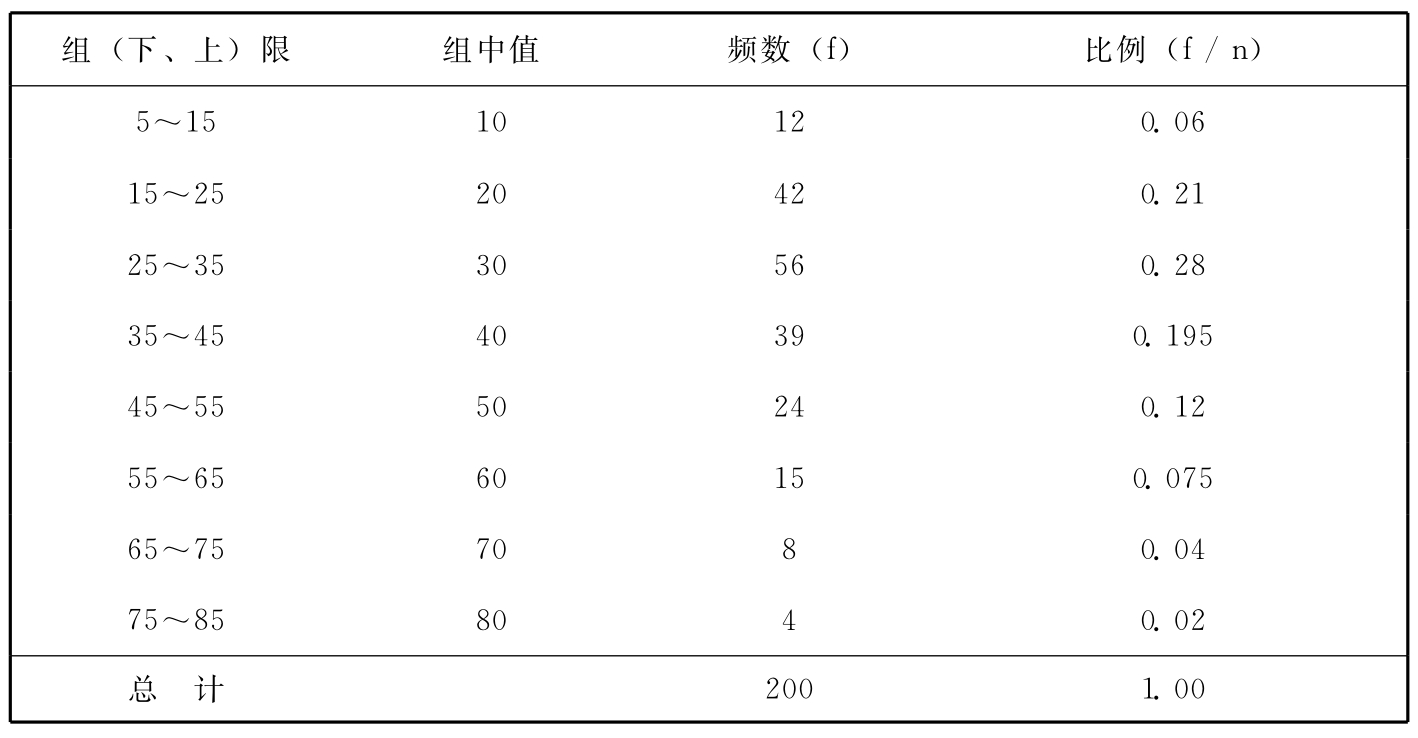
然后,就可以把频数的分布以直方图的形式表示出来,将横轴按对应的组限来划分,用长条的高度表示频数或相对频率,长条的底部覆盖该组的范围,长条之间不应有空隙。图3—13就是根据这200名居民平均每月订阅报刊花费的钱数作出的直方图。
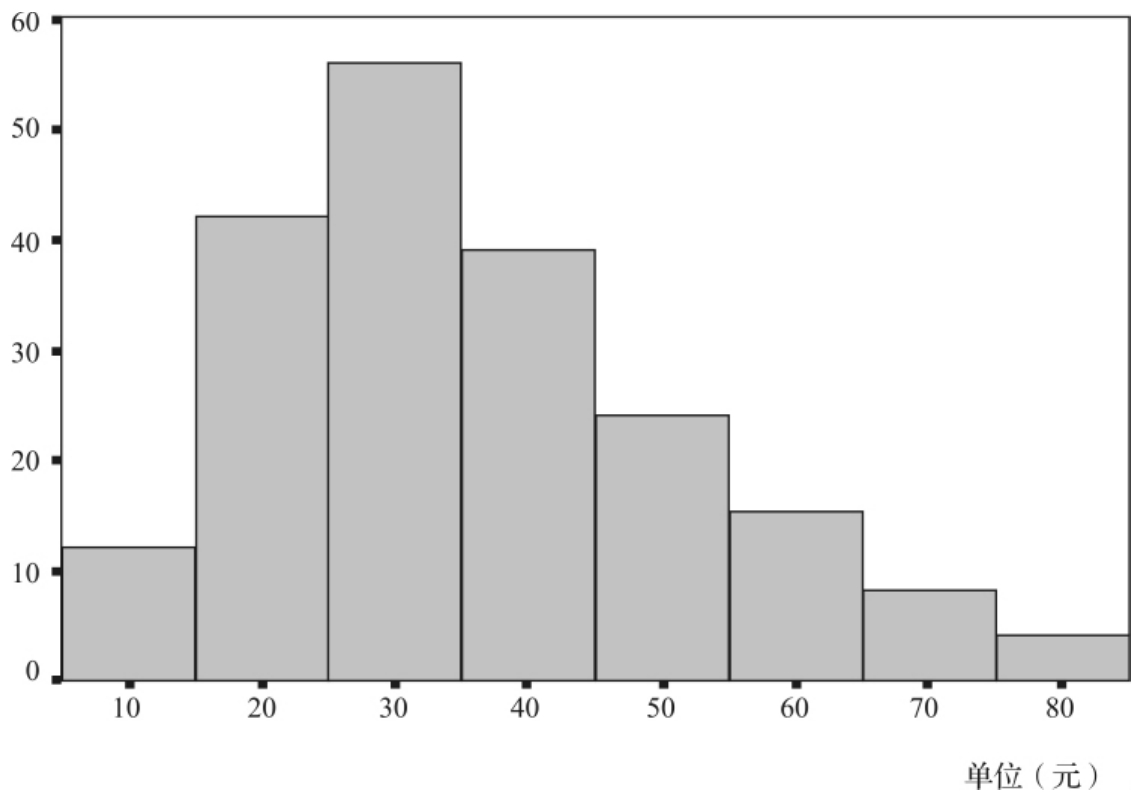
图3—13 200名居民平均每月订阅报刊花费钱数的直方图
直方图和条形图看起来很相似,不同之处在于直方图的底部刻度都间隔相同的单位数,而条形图底部没有真正的刻度;条形图的宽度是没有意义的,而直方图的宽度涵盖了一组变量的值;直方图中的长条互相连接,因为整个图的底部必须涵盖变量的所有取值。
从直方图中,就可以大致地看出该数值型变量的分布状况,包括分布的中心和离散程度,以及分布是否对称。我们刚刚已经提到过统计学最常用的一类分布——正态分布,它描述了大部分随机变量的分布状态。如果某一个变量的取值近似服从正态分布,从直方图长条高度的变化趋势上就可以近似看出正态变化的可能情形,比如本例中可以看出这200名居民订阅报刊所花费的钱数近似服从正态分布,但分布有些正偏。也有很多时候就直接把拟合的正态曲线附到直方图上,如图3—14所示。
(五)茎叶图
直方图并不是展现分布的惟一方法。当数据规模较小时,可以用茎叶图来描述,从茎叶图(stemplot或stem-and-leaf)中可以得到比直方图更多的信息。
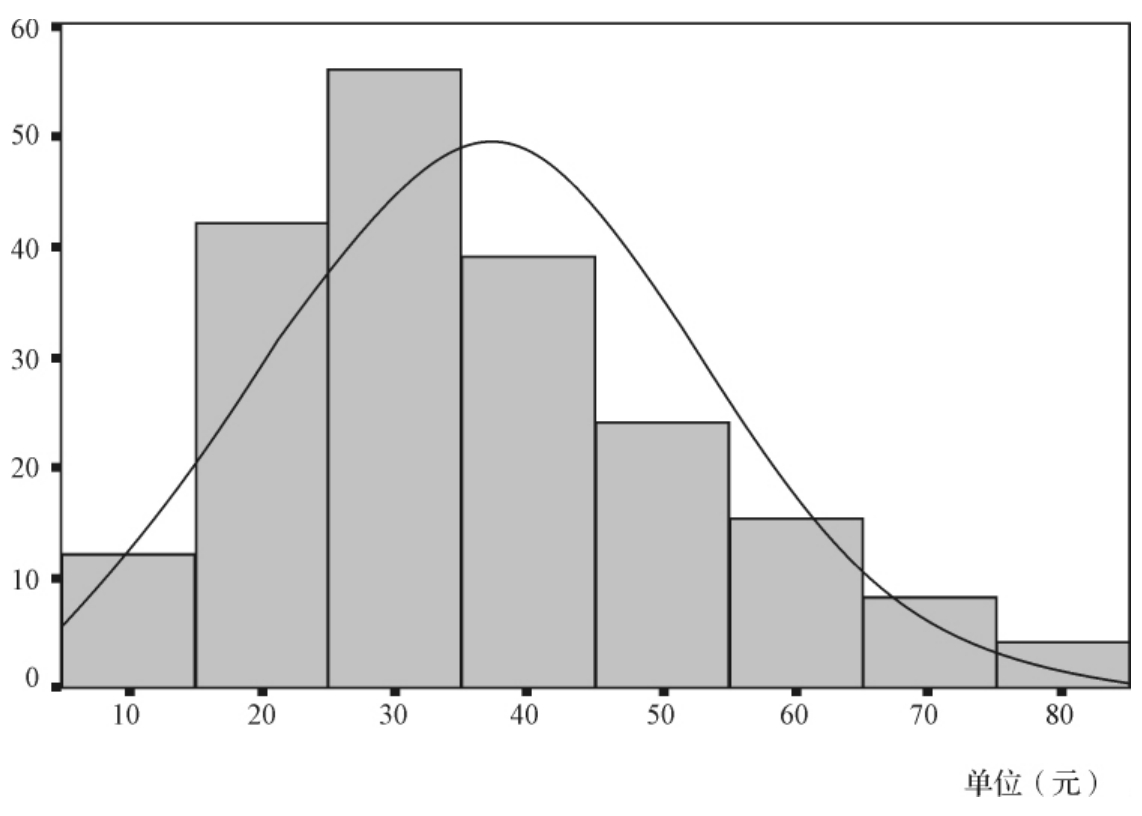
图3—14 200名居民平均每月订阅报刊花费钱数的直方图(带正态拟合曲线)
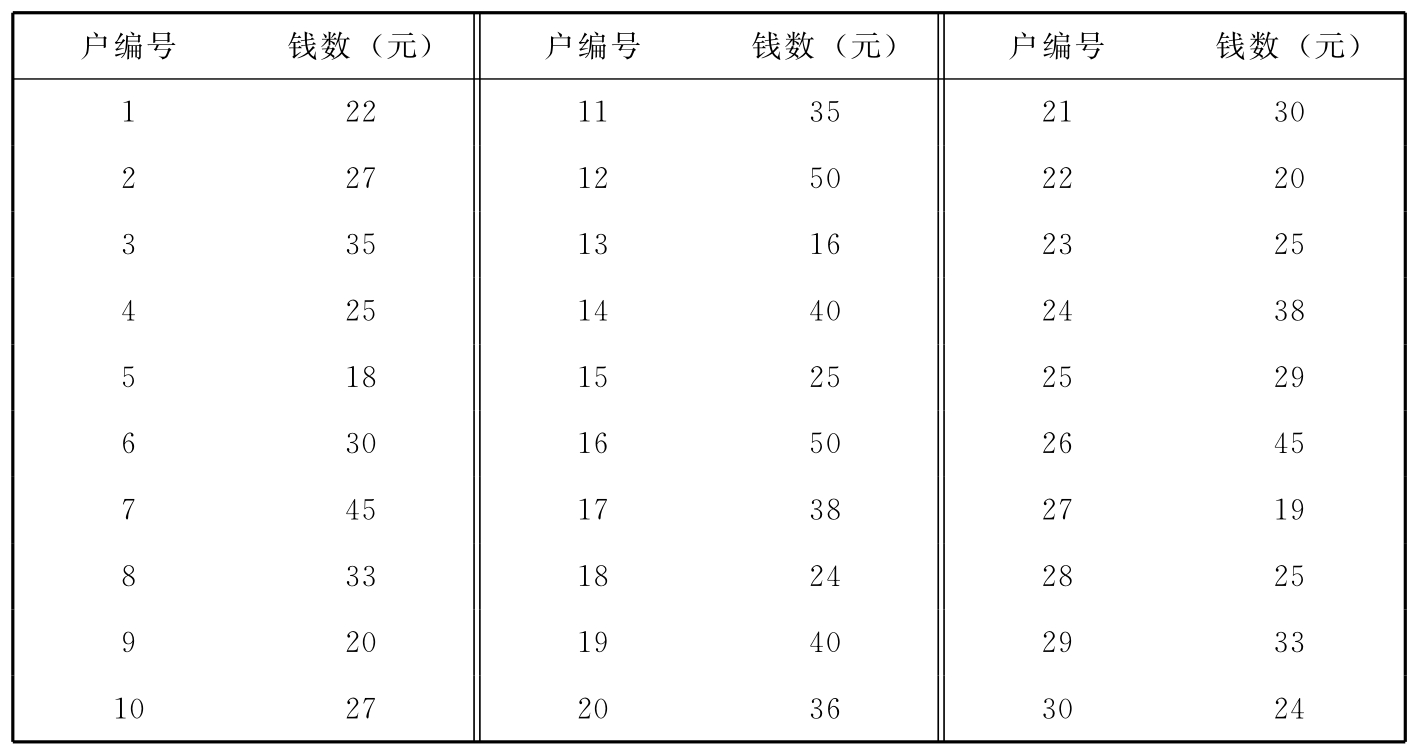
假设现在知道30户报刊订户平均每月订阅报刊花费的钱数,如表3—3中所列,下面就做出这30户订户平均每月订阅报纸杂志花费钱数的茎叶图(见图3—15)。
表3—3 30户报刊订户平均每月订阅报刊花费的钱数
第一步,先把每一观测值除最后一位数字外的数字当做“茎”,本例中,钱数的第一位数字就是茎。将茎由小到大垂直列出。
第二步,把观测值的最后一位数字(本例中是钱数的个位数)写在对应的茎的右边,当做“叶子”,茎和叶之间用竖线分开。茎叶图中,茎可以是多位数,但叶只能是一位数。
第三步,将对应同一个茎的叶子,由小到大进行排序。
茎叶图很像横着的直方图。从图3-15中可以看出,这30户订户平均每月订阅报纸杂志花费的钱数大致呈正偏的正态分布。

图3—15 30户订户平均每月订阅报纸杂志花费钱数的茎叶图
茎叶图的主要优点是保留原始的观测值。可以看出,在这30户订户中花费钱数最少的是16元,最多的是50元,而这些信息从直方图上是看不到的。
茎叶图规定用除了最后一位的其他数字当做茎,等于自动选择了组距,不过这样有可能不能有效描述分布的情况,如果组数加倍可以画出更好的图,则可以把茎再细分。比如现在有另外的353户订户平均每月花费的钱数,用SPSS可画出如图3—16所示的茎叶图。
图3—16的茎叶图左侧一列给出了频数,即每个茎对应的叶的总数,其中钱数大于41元的人有19户,SPSS把它们作为极端值一起列出,这些值分布在正态曲线右端很远的地方,当考虑分布的一般形态时,一般要排除这些极端值。图中列出的茎的宽度(Stem width)指的就是分组的组距,这里每两个年龄值分为一组,因此组距是2。当叶太多时,如果一一都画出会导致图形过大,这时可以用一个叶子代表不止一个的个案,比如图3—16中,一个叶子就代表取值相同的两个个案[Each leaf:2case(s)],而&符号代表半片叶子(只有一个个案)。

图3—16 353户订户平均每月订阅报刊花费钱数的茎叶图
(六)盒形图
在本节讲四分位数差的同时提到了第一四分位数、第二四分位数(中位数)、第三四分位数。这三个数加上数据的最小值和最大值,形成了一种五数综合的排列:最小值、第一四分位数、中位数、第三四分位数、最大值。
根据分布的五数综合,可画出盒形图(box plot),这是一种常用的表现数值型变量分布的图形。例如,把表3—3中的数据从小到大进行排序:
16 18 19 20 20 22 24 24 25 25 25 25 27 27 29
30 30 33 33 35 35 36 38 38 40 40 45 45 50 50
可以得知这30户订户平均每月订阅报刊花费钱数的最小值、第一四分位数、中位数、第三四分位数、最大值分别为16、24、29.5、38和50。根据这些数字做出如图3—17所示的盒形图。
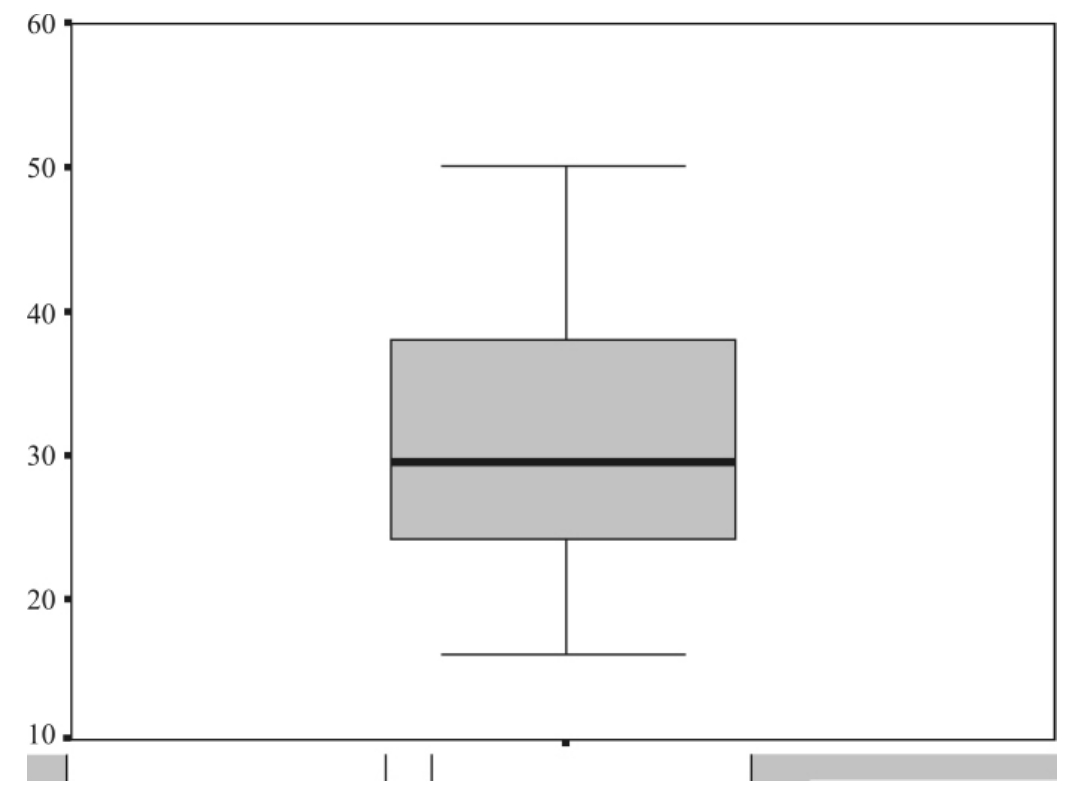
图3—17 30户订户平均每月订阅报刊花费钱数的盒形图
单个变量的盒形图横轴没有用处,纵轴代表变量的取值范围。盒形的中间有一条粗线,是中位数的位置,盒子上边线是分布的四分之三分位数,下边线是分布的四分之一分位数,盒子上下边线包含了分布的中间50%的观测。盒子的长度就是四分位差,可以反映数据分布的分散程度。从盒子边线向外画了两条线叫做触须线,最长可以延伸到四分位差的1.5倍,但是如果已经到了数据的最小值或最大值处就不再延伸。如果触须线没有达到数据的极端值,则这些数据点用触须线以外的点来画出,一般认为这样的点是异常点。从盒形图可以看出数据的偏斜情况,比如我们看到盒子的下半部比上半部短,而且下触须线比上触须线短,说明分布正偏。
盒形图不能像直方图和茎叶图那样给出分布的具体形状,因此盒形图不适于描述单个的分布。但是需要比较几个分布时,将对应的盒形图画在一起比较是很有效的,可以十分直观地比较不同的分布。例如,假定研究者为了比较电视和广播在不同时间段内播出的广告效果,从上午、中午、下午和晚上的电视和广播广告中抽取30个电视广告、20个广播广告,并通过一定的手段测量了这50个广告达到的效果的得分,用100分制表示。现在研究者想要知道电视广告和广播广告效果的差异,这时就可以以“媒体”这一变量为分类变量做出广告效果得分的盒形图,如图3—18所示。
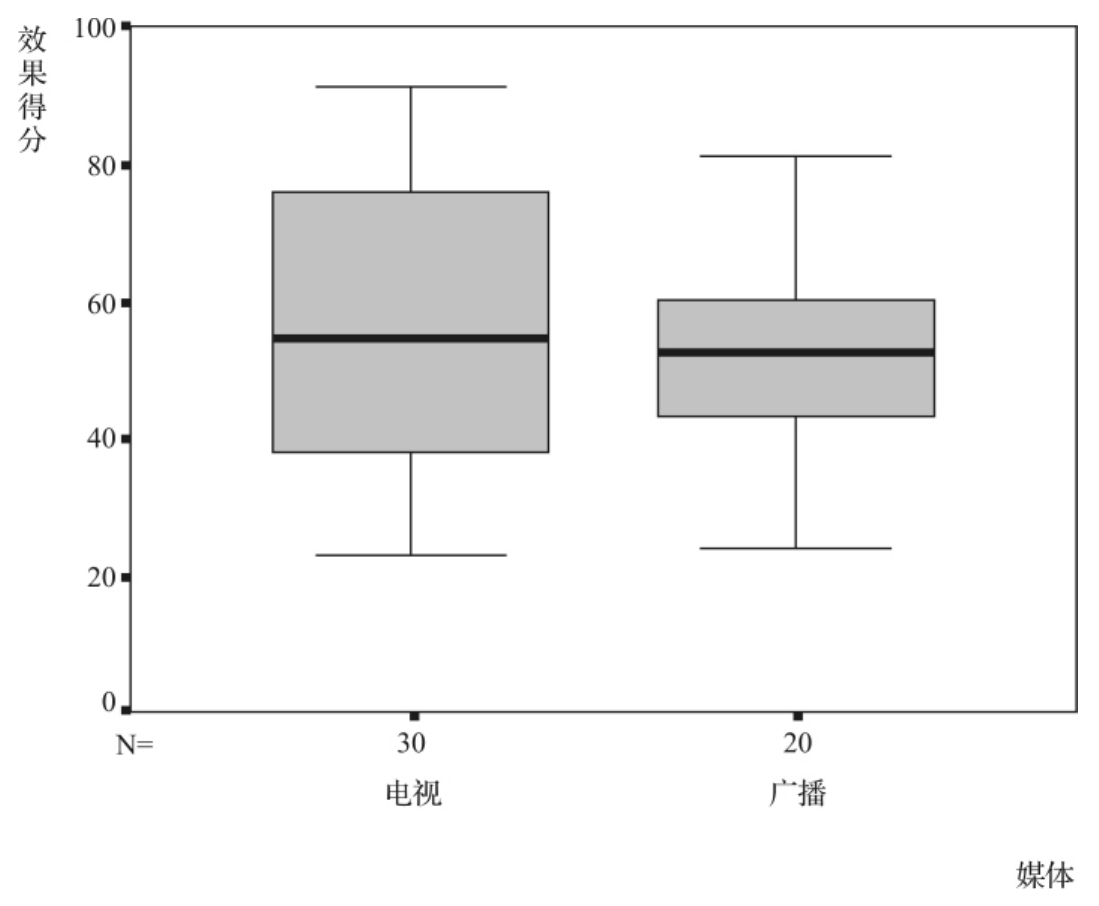
图3—18 电视广告和广播广告效果得分的比较盒形图
这种并排的盒形图把不同的分布在同一张图上表现出来,从而可以方便地比较这些分布的状况。从图3—18中可以看出,平均来说电视广告比广播广告的效果好,因为电视广告效果的中位数比广播广告效果得分的中位数高一些,不过电视广告效果得分的离散程度非常大,有的广告收到了很差的效果,有的广告则收到了很好的效果,这从盒子的高度(代表四分位差)可以看出来,广播广告的效果相对比较稳定。
研究者还想知道不同时段播出的广告效果差异,就要用“时段”为分类变量作出盒形图,如图3—19所示。
从图3—19中可以看出,不同时段播出的广告效果差异很大。平均来说,晚上播出的广告效果远远好于其他时段,不过并不是每个晚上播出的广告都收到了很好的效果(离散程度也比较大),其次是中午、上午的广告效果较好,而下午播出的广告收到的效果最差。
当然,如果要进一步比较不同媒体广告在不同时段的效果,可以同时以“媒体”和“时段”为分类变量作盒形图,这样每张图上就会有8个盒子了。
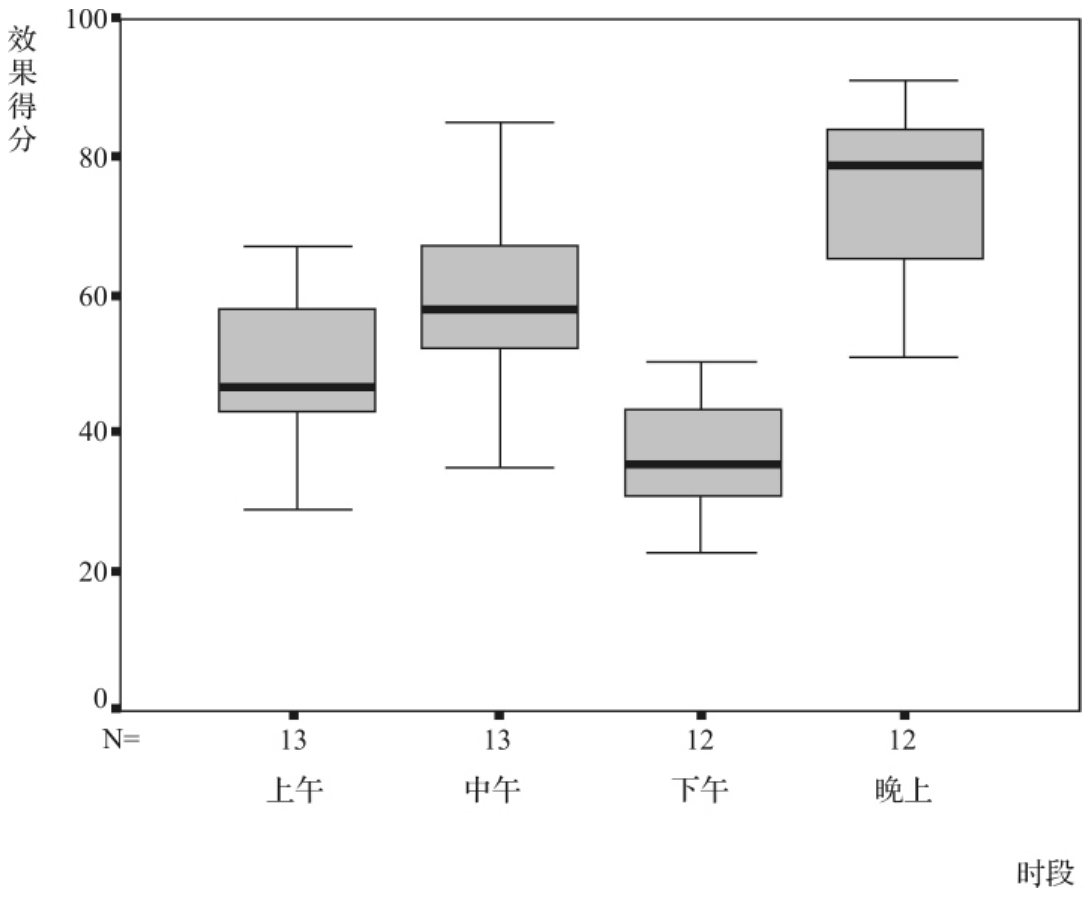
图3—19 不同时段播出的广告效果得分的比较盒形图
总的来说,对于单一变量的统计描述,首先可以作频数表;要借助图形展示的话,对于定类变量,可以采用饼形图、条形图和折线图;而对于数值类型变量,常常需要借助直方图、茎叶图和盒形图来展示它的分布形态。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











