



6.1 基于领域本体的检索模型分析
6.1.1 传统信息检索方法的不足
1 基于关键字的检索[1][2]
基于关键词匹配的方法,让用户以关键词的形式提出检索请求,然后将用户提交的关键词与文档库中的文档进行匹配,最后将那些出现了用户所提交的关键词的文档作为检索结果返回给用户。目前绝大多数搜索引擎,如Google、百度等,绝大多数的专业全文数据库,如中国期刊网、万方数据库等都采用这种检索方式。
基于关键字(词)的机械匹配进行的检索方式严重地割裂了字、词间的语义关联。只有当用户输入的关键字(词)与索引库中的索引字、词形式完全一致时,才能反馈形式相符的查询结果;否则,查询失败。基于这种缺乏语义的机械匹配式的查询机制,加之自然语言中一义多词、一词多义现象的广泛存在,导致用户查询获得的检索结果要么包括太多的无关信息,要么返回结果太少。这种查询机制缺乏智能性和知识性,越来越难以满足人们日益增长的知识需求。这种方法的最大不足就是检索过程不包含任何的语义信息,“关键字”仅仅是出现在页面中的符号而已,无法理解用户的检索提问的内容实质,缺乏必要的概念理解。例如,在检索中如果输入“熊猫”一词,目前的检索系统只能根据字面匹配得出含有“熊猫”的所有检索结果,而不关注到底是检索一种品牌,还是一种动物。
同时基于关键字的检索也无法获取隐含的知识,不能进行推理检索,不能进行语义关联检索,无法获取有语义关联的知识。隐含在内容中而没有直接表述的信息是无法得出的。例如,专家A 和B是合作者,如果A在其主页中提到了B是他的合作者,但是在B的主页中没有提到合作者的信息,由于合作关系是互相对应的,A提到了B是他的合作者,显然B也肯定是A的合作者,根据对称关系推导,就可以推导出B的合作者是A。但是目前的检索系统却不可能完成这种推理操作。
2 概念检索方法[3]
为了克服关键词检索的不足,学者们提出了另外一种检索方法,称为概念检索。这种方法是利用词汇在概念上的相关性,进行查询扩展处理。通过概念词典对用户的检索提问进行规范、查询和扩展来理解用户的检索意图。概念词典一般由专家手工定义的专业词表或者机器学习生成的关联概念空间。
概念检索方法克服了基于关键词检索中不考虑语义信息的局限性,并且具有较好的自然语言接口,但概念信息检索有一个不足之处就是概念词典表达的概念关系有限。一般的主题词表反映的词间关系为13种,如族首词、上位词、下位词、相关词、替代词等,而且主题词表无法表现公理、规则等。机器学习生成的关联概念空间是建立在大规模语料文本关联统计计算的基础上,所表达的概念关系大多仅仅是相关词集合,更适合供扩展查询使用。这两种方法虽然能在一定程度上解决基于关键词检索方式的不足,是一种初级的语义检索方式,但是对于能够理解用户的检索意图,理解关键词所表达的语义,还无法实现这种高级功能。因此需要有一种比叙词表、关联概念空间更为丰富的语义表示工具作为检索的支撑,而本体的特性恰好适合于知识表达,充分描述知识模型,并能够支持语义推理,同时采用通用的知识建模语言,更适合网络环境下的知识共享和互操作。
另外,目前绝大多数检索工具都存在着信息加工深度不够,检准率低;搜索引擎大多是综合性的,收录各方面、各学科和各行业的信息,在反映信息方面很难做到全、快、精、准,很难满足科研人员对专业网络信息资源的需求。缺乏专业的搜索引擎,也有学者提出发展针对某一领域、某一特定人群或某一特定需求建立的垂直型搜索引擎。但是这种搜索引擎同目前通用的搜索引擎在原理和技术上并没有区别,如果能建立一种可以实现领域知识的共同理解,确定领域概念之间相互关联的工具,就能够实现对于专业检索的检索精度。
6.1.2 基于领域本体的检索模型的优点
本体可以严格对概念进行描述和定义,反映概念之间的语义关系,因此基于领域本体的检索模型具有多种优点,有利于解决目前信息检索中存在的诸多问题。
(1)多途径多层面的知识表示
本体可以描述事物的属性、关系和分类;可以利用古农书本体中不同的语义关系多维度表示各种知识以及知识之间的关联。如下图所示,图中的任意一个节点都可以作为检索点,从不同的角度对农书知识进行多维度的揭示,把有语义联系的事物都连通起来。可以按照某个时代(唐、宋、元等),某种知识元(小麦、水稻、玉米等),某个机构(收藏机构、研究机构、出版机构等),某个地点(江南地区、黄河流域等),某种人物(贾思勰、万国鼎等)等多途径全方位地进行可视化显示和查询。
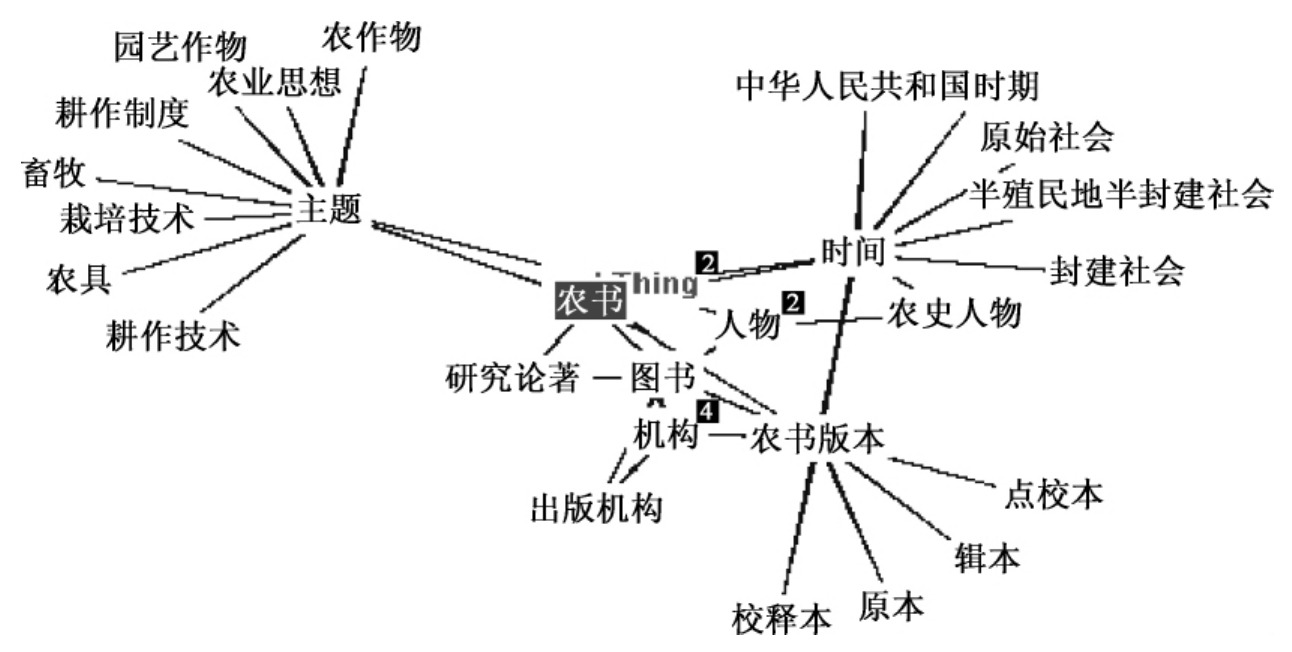
图6-1 领域本体检索点示意图
(2)信息资源的整合
领域本体更加完善地实现了知识组织的两种方式,即分类法与主题法的一体化:即由概念以及概念之间的关系形成分类体系,众多概念的实例形成词表。利用领域本体的“分类—主题”结构,可以将古农书相关的不同类型的信息资源有效、有序地整合起来,使得各种不同类型的信息资源成为古农书本体的各个节点,实现对信息资源的结构化组织。例如,可以把农书的各个版本的图片、文字组织于不同的版本节点之下,把相关的机构、人物介绍等声音文件、视频文件等多媒体文件合理地组织于古农书本体节点之下,把相关的研究论著组织于古农书本体之下,实现“一站式”检索。
(3)知识导航
领域本体整合了分类表、叙词表和元数据的功能,用领域置标语言全面描述了领域知识,再加上可视化语义工具的支持,集中表现了领域概念之间的复杂关系,是一种表现丰富的知识表示工具,不失为一种生动的教学工具,可以总揽每种农书的版本,存佚以及研究概况等,因而可以成功地用于知识导航。图6-2以《氾胜之书》为例显示了该书的各个知识点。
(4)知识获取
由于信息的急剧增长,使得人们在因特网时代更希望直接获得所需的知识,从对文本的获取提升到对知识需求的层面。领域本体在一定程度上可以视为领域专家知识库,利用其中的关联可以实现对领域知识的问答和获取,例如“万国鼎撰写了哪些关于《氾胜之书》的研究论著?”、“哪些农书论述了大麻的栽培?”。本文以古农书本体为基础开发了一个农书本体的检索系统。例如输入“清代哪些农书论述了大麻的栽培?”系统检索结果如下图所示:
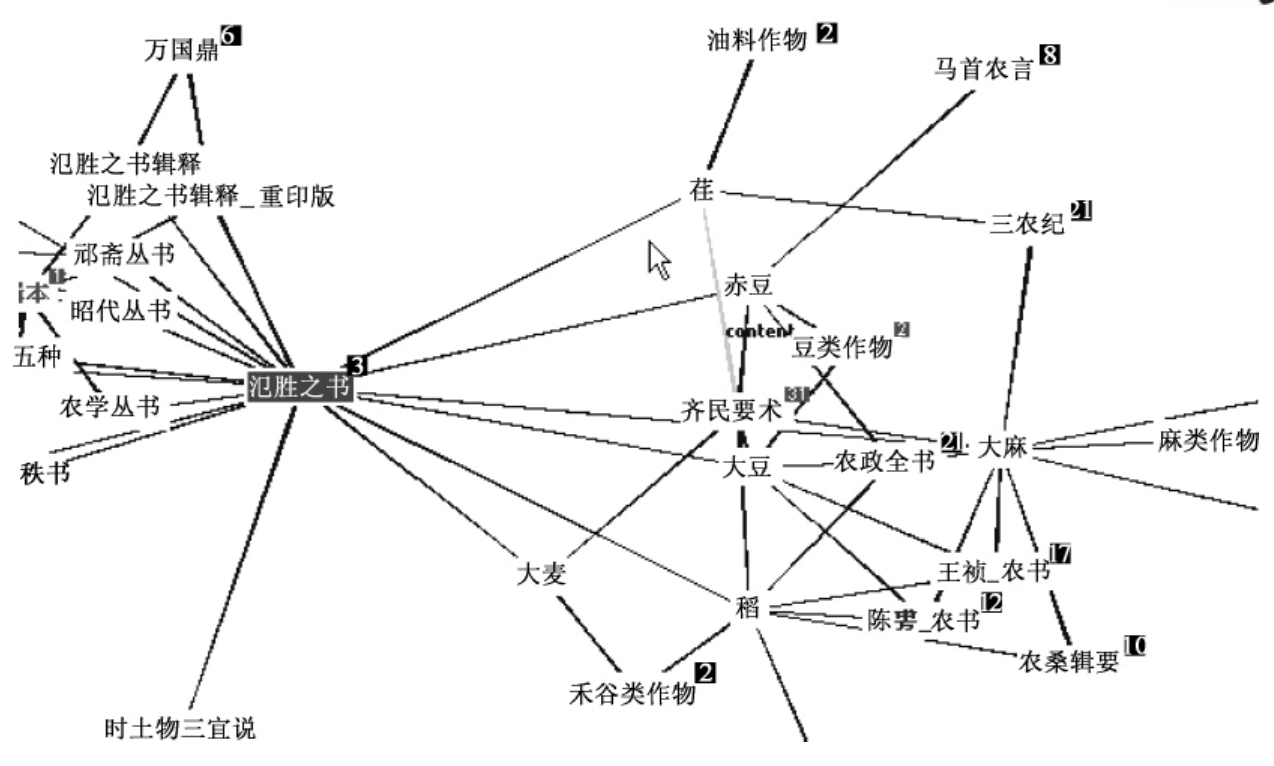
图6-2 《氾胜之书》知识导航图
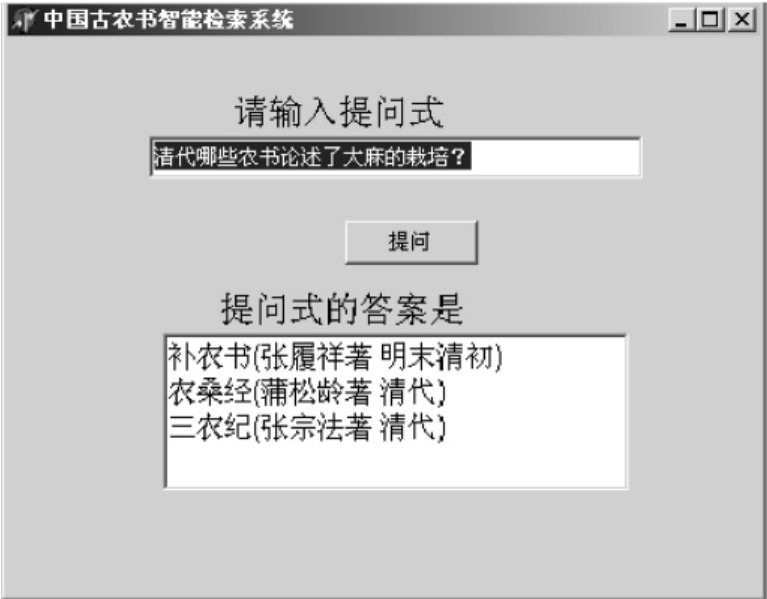
图6-3 本体问答查询示意图
(5)智能检索
传统信息检索是以单纯的词作为检索的入口。这种关键词匹配方式仅仅是字面或某种意义上的匹配,不能获取概念层面的相关含义,而基于本体的信息检索可以弥补这种不足。首先,领域本体引入了和古农书相关的语义属性和语义关联,可以将领域的检索结果按照其语义属性和语义关联分类,使得检索结果不再是孤立的,不再是类似搜索引擎似的字面匹配,而是一种概念匹配。其次,通过领域本体中的各项属性和关联,可以自由实现扩检,使得检索结果更加全面和准确。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









