



3. 3 叙词本体的结构
叙词本体的组成结构可划分为两个主要的层次:应用层与技术层(见图3-3)。
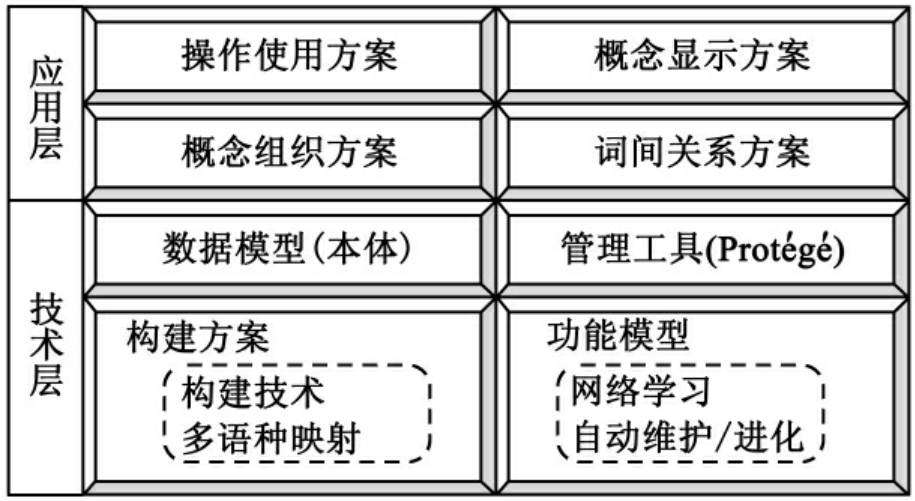
图3-3 叙词本体(第二代叙词表)的逻辑结构略图
3.3.1 应用层
应用层是叙词表的外观视图与功能描述。叙词本体的外观表现与传统的叙词表一样,其可视化效果为一维的、线性的树状结构。但实质上由于底层有本体的支持,叙词本体具有网络结构的特性。通过属性之间的联系,使得叙词本体中的概念与概念之间呈现出错综复杂的网状关系。因此,在操作和使用上,与传统叙词表的使用没有多大的区别,但却会更加智能化。例如,当输入一个非规范化词时,不用手动查找代用的规范化概念,通过概念与概念的关系将非规范化语词和规范化语词联系起来,而这个转化过程对用户来说是透明的。除此之外,叙词本体还提供多样化检索途径,不仅可以通过叙词术语查找相关信息,而且可以通过学科分类查找叙词术语,而传统的叙词表只能通过字顺进行查找。
叙词本体的应用层从四个方面为用户提供了良好的解决方案。
(1)操作使用方案
这里的操作含有两层含义,一种是查询,另一种则为叙词本体演化操作。叙词本体为用户提供了一个界面友好的查询界面。上面内容已经讲到叙词本体提供了多样化的检索途径,目的在于能够让用户更好的操作叙词本体,为用户使用叙词本体提供更多的方便。叙词本体的功能除了查询之外,最重要的是提供了演化的功能。在叙词本体进行演化之前,需要工作人员设置一些必要的参数。如演化叙词本体的周期,即叙词本体多长时间演化一次;设置新词频次标准,即指新出现的词汇达到多少次才认为其是达到使用广泛性的要求,可以作为候选的新叙词术语被提取出来;设置新关系频次标准,即提取出来的新关系使用的频次达到多少,才能够视其已达到广泛使用的要求,可以作为候选新关系提取出来。关于演化的操作除了设置参数之外,还需要为专家提供一个可以完成专家评审操作的界面。在这一部分中,专家需要完成的操作包括:查看新叙词术语出现的频次,新叙词术语与其他术语之间的关系,以及关系出现的频次;查看其他专家对新词以及新关系的打分情况,以及其他专家对此的看法;可以在评审子系统中,与其他专家进行讨论;为新词以及新关系进行打分,并发表自己的看法。最后演化功能的操作,即是系统自动根据专家的评审意见进行统计分析,决定是否将提取出的新词以及新关系添加到叙词本体中去,如果评审通过,则将提取出的该新词以及新关系添加到叙词本体中,完成整个演化过程。
(2)概念显示方案
这里所指的概念包括了两层含义,一种是指学科分类的概念,另外一种是指叙词术语概念。在叙词本体中,对这两层含义的概念都进行了显示。学科分类概念的显示以树形控件进行显示。每个学科分类下都有很多叙词术语,因此在每一层节点后面都会标示该学科分类下有多少叙词术语,见图3-4。
叙词术语概念的显示则是以表格控件进行显示。对于每一个叙词术语都会为其提供术语描述,中图法分类号,所属分类,以及与其他术语之间的关系,包括了叙词本体中所有的RI关系。
图3-4只是针对单语种进行显示的,对于多语种叙词本体的显示则更为复杂一些。叙词术语一栏可能会以中文的形式显示,也可以以英文的形式显示。这是因为中文叙词术语以及英文叙词术语是两个完全不同的叙词术语。RI关系中,也可能会有中文叙词术语与英文叙词术语之间的各种关系。
(3)概念的组织方案

图3-4 叙词本体类目体系
同显示方案一样,概念的组织方案也是按照学科分类概念以及叙词术语概念两种不同概念分别进行组织的。对于学科分类概念,采用树状组织方式;对于叙词术语概念采用网状组织方式,其网状形式则是通过各种RI(用,代,属,分,参,族)关系进行链接的。
(4)词间关系方案
从图3-4可以看到,目前界面上只采用了叙词表里的几种关系(用、代、属、分、参、族)。随着关系提取的技术不断进步,可以细化各种关系,如可以定义相关关系的子关系,具体到对立关系,交叉关系等,在显示方案中也需要适当的扩展显示这些子关系,从而使用户可以一目了然叙词术语所有信息,并且可以更清楚地知道该叙词术语与其他叙词术语之间更深层次的关系,加深用户对该叙词术语的理解。
3. 3. 2 技术层
技术层以本体的形式进行数字化存储与处理。采用本体构建的方法和工具对叙词表中的概念进行抽象,创建类,并将叙词的词间关系作为类的属性。为了让用户更加方便和深刻的理解,还可以创建类的实例,从而实现信息的自动标引和索引词的选择。除此之外,技术层还包括有叙词本体的自动学习和进化的功能,使叙词本体成为一个开放的,可扩展的叙词表,以适应不断发展的学科领域。
(1)数据模型
根据《中国图书馆分类主题词表》(以下简称《中图法》)的结构特征,我们按照分类体系来定义叙词本体的类属结构,而主题词则作为叙词本体每个类目下的实例。图3-5为叙词本体的概念模型。
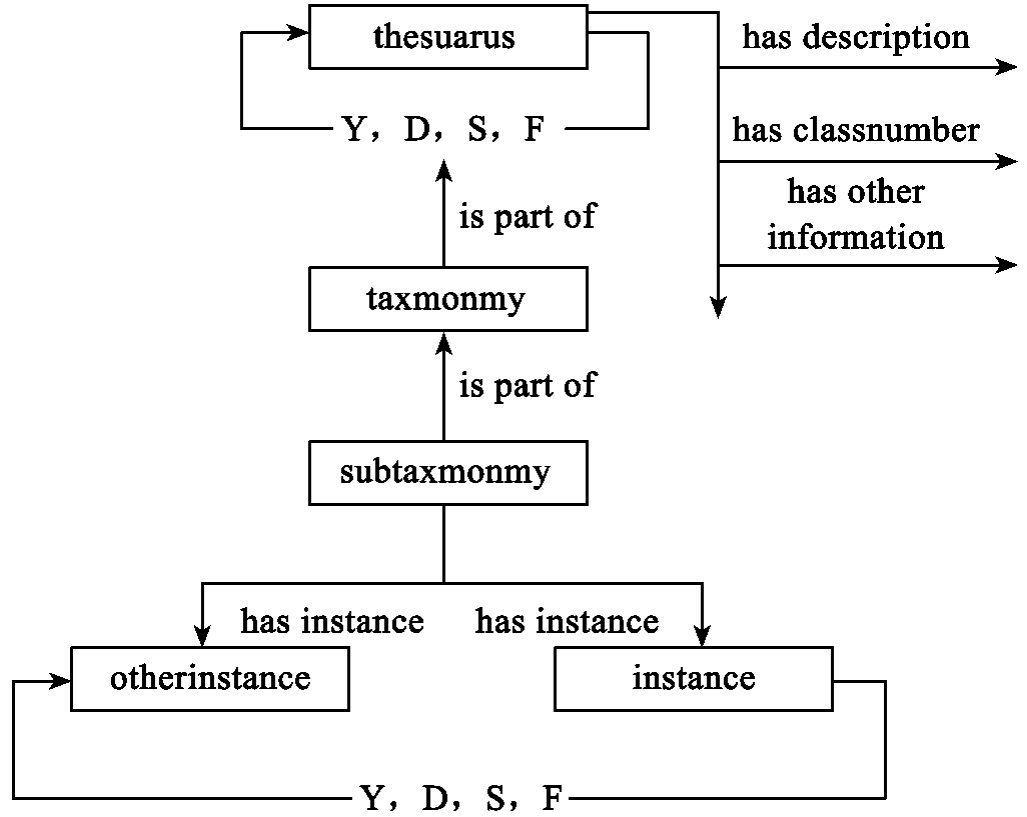
图3-5 叙词本体构建的概念模型
thesaurus是叙词本体的最顶层类,下面有很多子类,其子类为《中图法》的20个大类,图中用taxnmnmy概括表示这20个大类,每个大类下面又有很多小类以及更细的分类,图中用subtaxmonomy表示。每个类目下可能会有很多叙词,在叙词本体中用实例来描述叙词。叙词之间存在着许多关系,即用(Y),代(D),属(S),分(F),参(C),族(Z)。这些关系在本体中应该为对象属性,因此在thesaurus类中就应该定义好这些对象属性,对于具体的叙词(实例),则需要添加具体的值以完成叙词关系的映射。除了定义这些对象属性之外,还需要添加其他的值属性以完善叙词的描述,如叙词含义描述has description,叙词的中图分类号has class number,以及其他的一些信息。图3-5将作为构建叙词本体的概念模型。
(2)管理工具(Protégé)
Protégé是由斯坦福大学的Stanford Medical Informatics开发的一个开放源码的本体编辑器,它是用Java编写的,可以免费下载。Protégé界面风格与普通Windows应用程序风格一致,用户易上手。Protégé支持多重继承,对新数据进行一致性检查,并且具有很强的可扩展性,主要表现如下几点:
①Protégé是一个可扩展的知识模型。用户可以重新定义系统使用的表示原语。
②文件输出格式可以定制。可以将Protégé的内部表示转换成多种形式的文本表示格式,包括XML、RDF(S)、OIL、DAML、DAML+OII、OW L等系列语言。
③用户接口可以定制。提供可扩展的API接口,用户可以更换Protégé的用户接口的显示和数据获取模块来适应新的语言。
④有可以与其他应用结合的可扩展的体系结构。用户可以将其与外部语义模块(例如针对新语言的推理添加模块)直接相连。
⑤后台支持数据库存储,使用JDBC和JDBC-ODBC访问数据库。由于Protégé开放源代码,提供了本体建设的基本功能,使用简单方便,有详细友好的帮助文档,模块划分清晰,提供完整的API接口。
因此,它基本上成为国内外众多本体研究机构的首选工具。我们在叙词本体演化系统也将使用Protégé来构建初始的叙词本体。
本体的描述语言比较多,如XML,XML Schema,RDF,RDF Schema。其中XML(http://www.w3.org/XML/)提供了一种结构化文档的表层语法,但没有对这些文档的含义施加任何语义约束;而XML Schema(http://www.w3.org/XML/Schema)是一个约束XML文档结构和为XML扩充了数据类型的语言; RDF(http:// www.w3.org/TR/2002/WD-rdf-concepts-20021108)是一个描述RDF资源的属性(property)和类(class)的词汇表,提供了关于这些属性和类的层次结构的语义。RDF的基本构造为陈述(或声明,Statement),表述了一个“资源,资源所具有的属性,属性值”(即主体-属性-客体)的三元组。RDF表现的是一个数据模型,简言之,就是一个事物(资源),这个事物具有什么属性,这些属性应该有什么样的属性值。而OWL则是RDF的扩展,为我们提供了更广泛的定义RDFS词汇的功能,更广泛意指可以定义词汇之间的关系,类与类之间的关系,属性与属性之间的关系等。它旨在用于那些需要由应用程序而不是由手工处理文档中信息的情形。OWL可被用来明确表示词汇表中术语的含义以及术语间的关系。如此表示的术语及术语间关系被称为本体(Ontology)。OWL较之于XML,XML Schema,RDF,RDF Schema添加了更多的用于描述属性和类的词汇,例如类之间的不相交性(disjointness),基数(cardinality,刚好一个)、等价性、属性的更丰富类型、属性特征(例如对称性),以及枚举类型(enumerated classes)。因此在表达含义和语义方面,OWL比XML,RDF和RDFS有更多的表达手段,在Web上表达机器可理解内容的能力也比这些语言强。由于OWL的这种优势,我们的叙词本体采用OWL语言来描述本体。
(3)构建方案
叙词本体基于B/S模式,技术层与应用层分别基于服务器端和客户端。
服务器端根据叙词本体的定义以及结构,我们可以以《中国图书馆分类主题词表》为蓝本来构建叙词本体。《中国图书馆分类主题词表》主表中的左部分是分类法,给出了学科分类,右部分则是对应于该分类的叙词。因此,我们可以用学科分类来构建叙词本体中的概念C,用叙词来构建叙词本体中的术语I。学科分类关系就是概念类属关系HC,而叙词表中叙词之间的“用,代,属,分,参,族”关系就是叙词本体中术语关系RI。另外需要制定一些规则即公理O,使其支持之后演化过程需要的推理。按照这种对应关系,我们利用本体构建工具Protégé手工构建初始化的叙词本体,作为叙词本体演化的原始版本。Protégé工具构建出的本体是用本体描述语言OWL表示。其中,概念之间的定义方式如下:
<rdfs:Class rdf:about="http://www.domain2. com#情报学与情报工作">
<rdfs:subClassOf rdf:resource="http://www.domain2. com#科学_科学研究"/>
</rdfs:Class>
叙词概念之间的关系用、代、属、分、参、族作为概念间的关系定义:
<owl:ObjectProperty rdf:ID="D">
<owl:inverseOf>
<owl:ObjectProperty rdf:ID="Y"/>
</owl:inverseOf>
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="Z">
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="S">
<owl:inverseOf>
<owl:ObjectProperty rdf:ID="F"/>
</owl:inverseOf>
<rdfs:range rdf:resource="http://www.domain2.com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="#F">
<owl:inverseOf rdf:resource="#S"/>
<rdfs:range rdf:resource="http://www.domain2.com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="#Y">
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
<owl:inverseOf rdf:resource="#D"/>
</owl:ObjectProperty>
<owl:DatatypeProperty rdf:about="http://www.domain2. com#hasChineseTerm">
<rdfs: range rdf: resource=" http://www.w3.org/2001/ XMLSchema#string"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:DatatypeProperty>
<owl:SymmetricProperty rdf:ID="C">
<owl:inverseOf rdf:resource="#C"/>
<rdf: type rdf: resource="http://www.w3.org/2002/07/ owl#ObjectProperty"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:SymmetricProperty>
用,代是可以逆转的,定义成逆反属性,而属、分也是可以逆转的,因此也定义成逆反属性,而参为对称的,因此定义成对称属性。而所有的对象属性的值域和定义域都是所有的概念,因此为最上位类的概念。
而隶属于某种概念的(叙词)术语在本体中则以概念实例的形式呈现,用OWL表示如下:
<thes:情报检索rdf:about="http://www.domain2.com#查全率">
<thes: hasChineseTerm rdf: datatype=" http:// www.w3.org/2001/XMLSchema#string">查全率</thes:hasChinese-Term>
</thes:情报检索>这表示查全率是情报检索的一个叙词,其中thes:hasChinese-Term是查全率的一个值属性,而<thes:hasChineseTerm></thes: hasChineseTerm>之间的查全率是属性值。这样做的好处是:可以增加更多的值属性来描述此叙词,比如用英语来描述这个术语,就可以增加一个值属性<thes:hasEnglishTerm>,用法和中文的用法一样。这样有助于构建多语种叙词本体。
客户端客户端以浏览器的形式呈现给用户,以使用户有一个友好的界面接口。我们利用Java与JSP来实现。
系统叙词本体构建之后的可视化效果如图3-4所示,左边呈现了叙词表的类目结构,其结构与《中国图书馆分类法》的结构一样,每一个类目下有多个叙词。类目后的小括号的数字表示该类目下的叙词数目。因此,系统能够清晰地显示叙词表的类目系统。右边如具体的叙词的详细信息,包括叙词的含义,《中图法》分类号,所属分类以及叙词的六种关系。点击左边的类目,可以在右边的详细信息显示区域将该类目下的所有叙词的详细信息都显示出来。也可以输入具体的术语,将该术语的具体信息显示出来。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









