



6.3.2 数据分类处理方法
在数据分类处理中,一般使用聚类分析法。“物以类聚”,通过聚类分析我们可以将不同样本的产业竞争力水平分为几类,找出每一类共同的特点,以利于更好地研究产业竞争力,制定相应的对策和政策。聚类分析是对样品即个体以某种相似性为度量标准进行分类的一种统计方法。所谓谱系(或类),就是指相似物体的集合。常用的分类方法有两个: 一是用相似系数,将性质比较相似的个体分为一个谱系(或类),不太相似的个体分为不同的谱系(或类);二是将每一个样品(或个体)看成空间的一个点,距离近的点分为一个谱系(或类),距离较远的点分为不同的谱系(或类)。聚类分析根据分类对象的不同,分为R型聚类分析和Q型聚类分析,前者用于指标聚类,后者用于样品即个体聚类。本书主要用到后者,所以R型聚类分析就不再赘述。假定有一个由P个变量描述的事物的样本,第i个样品的数据为:
(xi1xi2…xip) i=1, 2,…, n
这样就得到原始数据矩阵:

其中Xij的第一个subi是样品号,第二个subj为变量号。
由于变量的量级可能差距大,例如X2是二位数,X5是四位数,那么在构成相似性度量时,X5就会占优势,所以有时需要对原始数据做一些处理,常用的处理方法有:
(1) 中心化方法。
zij=xij-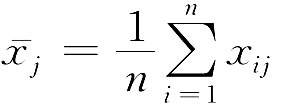 , (i=1, 2, …, n; j=1, 2, …, p) (6-4)
, (i=1, 2, …, n; j=1, 2, …, p) (6-4)
其中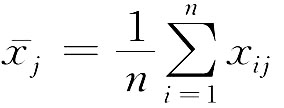 ,是第j个变量的均值。
,是第j个变量的均值。
(2) 取对数方法。这就要假定Xij>0,否则不能用。
zij=logxij/log(10),(i=1, 2,…, n;j=1, 2, …, p)(6-5)
(3) 极化方法。
zij=(xij-mj)/(Mj-mj), (i=1, 2,…, n; j=1, 2, …, p) (6-6)
(4) 标准化方法。
zij=(xij-xj)/σj, (i=1, 2, …, n; j=1, 2, …, p) (6-7)
其中:
样品间的相似性度量基本上可以分为两大类: 一类是以总量是否相近为标准,这类相似性度统称为样品间的距离;另一类是以各变量对应的比例是否相近为标准,统称为样品间的相似系数。每一类中都有许多具体的度量公式。
可以介绍几种距离,比如两个样品:
xi1xi2… xip
xj1xj2… xjp
它们的欧氏距离为:
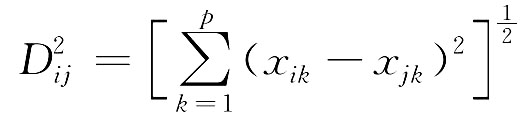
闵氏距离为:
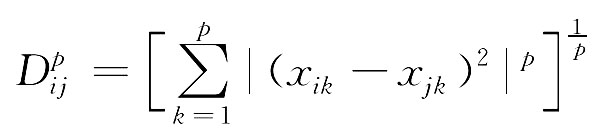
当p=1时,闵氏距离为:
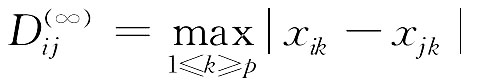
当P→+∞时,闵氏距离为:
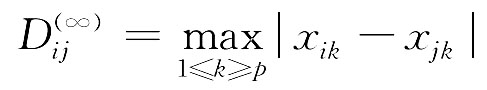
不难看出,p=2就是欧氏距离。在实际应用中,最常用的是欧氏距离D(2)ij,其次是D(1)ij与D(∞)ij这两种距离。
当选定一种相似性度量标准之后,就可计算样本内每两个样品之间的距离,从而得到一个样品间的相似性度量矩阵:
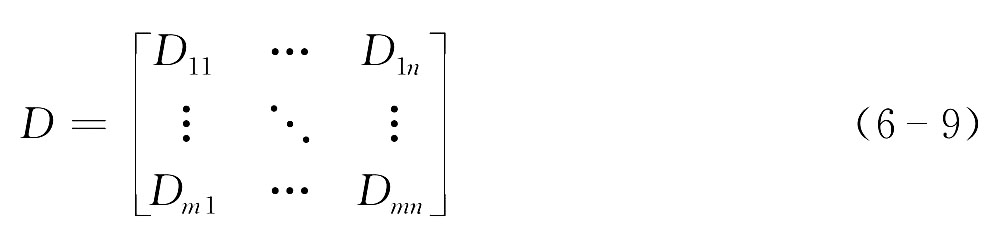
其中Dij就是样品i与j之间的相似性度量,这个矩阵就是进行样品聚类族分谱系的出发点。
有了样品间的相似性度量矩阵,就要对样本族分谱系了。族分的方法也有很多种,如逐步聚类法、快速聚类法、系统聚类法等等,我们主要采用系统聚类法。
系统聚类法的步骤是:
(1) 写出样本的相似性度量矩阵,由于这个矩阵是对称的,而且主对角线上的元素对族分谱系没有作用,所以只需写出上半三角形就可以了。
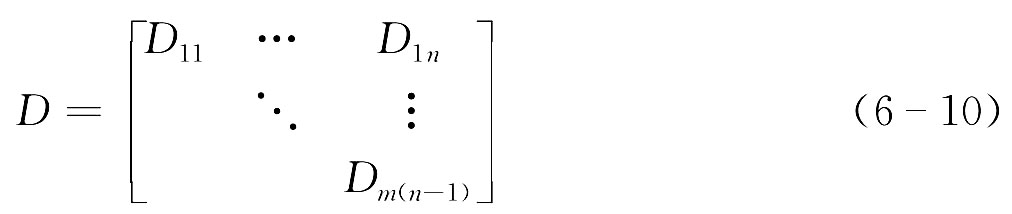
(2) 把每个样品称为一类,所以开始簇分时,共有n类。
(3) 在(6-10)式中找出最小的数,设为Dpq(假定p<q)。
(4) 将p, q两类合并成一类,记作n+1(r)类,同时把6-10式中的p, q所在的两行与两列划去,而在n列之后,增加一列,其元素Di(n+1)(i≠p, q)表示第i类与第n+1类之间的距离,形成新的(6-10)式。现在需要说明的是Di(n+1)的算法。
如果是欧氏距离,则有八种计算Di(n+1)的方法,确定采用一种算法之后,中途就不准改变。这八种算法的名称为: 最短距离法、最大距离法、中间距离法、重心法、类平均法、可变类平均法、可变法、离差平方和法。
设i类样品个数为ni个,那么当p类与q类合并为r类之后,r类与其余各类i(这里i≠p, q)的距离按以下公式计算:

其中,αp, αq, β, δ四个参数由下列表格给出数值。
如果是其他距离,对于最短距离法、最长距离法、类平均法、可变类平均法,公式6-11仍是可用的。
(5) 返回第三步。
如此重复(3)、(4)两步,共n-1次,就完成谱系族分的计算,根据这个计算,即可做出样本的谱系图,有了这个谱系图,就可以根据需要确定个值λ,把距离小于λ的样品分为同一类,而把距离大于等于λ的样品划分为不同的类。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











