



6.1 多维数据模型
为了深入地理解数据仓库和OLAP,我们首先了解一下多维数据模型。
通过前面的学习,我们知道,关系数据库具有数据冗余小、数据一致性好等优点,它有效地满足了联机事务处理的需求。数据保存下来之后,更重要的任务就是对数据进行查询、分析以支持管理决策。那么,关系数据库在数据分析方面的能力怎么样呢?
下面,我们可以通过一个制作销售统计报表的例子来探讨一下这个问题。假如销售部门想要生成一张表6-1所示的销售统计表。
表6-1 ╳╳公司销售统计表
统计期间:2008年1月 单位:万元
为此,可能需要用到OLTP数据库中以下4个表的数据:销售单表(销售单号,销售时间,门店号),销售明细表(销售单号,产品编号,销售量),产品表(产品编号,产品名称,产品类别,单价),门店表(门店号,门店名,地址)。虽然可以利用SQL语言,通过复杂的选择、连接、汇总、计算等操作得出表6-1,但显然这一过程十分复杂,需要较长的运算时间,不能满足管理人员快速、方便地分析数据的需求。
设想一下,如果数据存储在图6-1的立方体中,我们在时间轴上1月份处做一个截面,得到的结果不正是表6-1吗?由此可见,如果数据能组织成多维的形式,就能够较好地满足管理人员对数据分析的需求。一种不同于关系数据库的技术,多维数据模型就可以将数据组织成多维的形式。
多维数据模型的概念
在多维数据模型中,一部分数据是数据测量值,称为“度量”。度量是有数字有单位的数据,如销售量、投资额和收入等。而度量依赖于一组“维”,这些维提供了度量的上下文关系。例如,销售量(度量)与销售地区、商品名称及销售时间这三个维有关,这些相关的维决定了这个销售测量值。因此,多维数据视图就是在由维构成的多维空间中,存放着度量数据。
进一步来说,所谓的维就是人们观察数据的特定角度,是考虑问题时所涉及的一类属性,属性的集合便构成一个维。例如,企业决策制定者往往关心产品销售数据随着时间推移而产生变化的情况,这是从时间的角度来观察产品的销售情况,所以时间就是一个维(时间维)。企业决策制定者也时常关心本企业的产品在不同地区的销售分布情况,这是从地理区域分布的角度来观察产品的销售情况,所以地理区域分布也是一个维(地理维)。
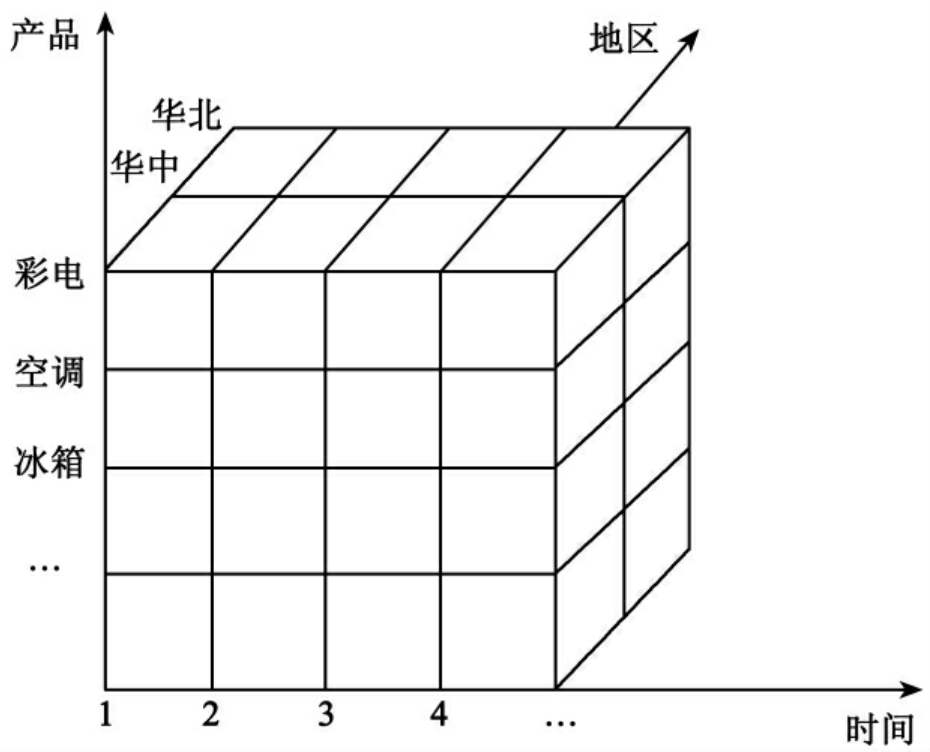
图6-1 多维数据模型示意图
人们观察数据的某个特定角度(即某个维)还可以存在细节程度互异的各个描述层面,称为维的层次。一个维往往具有多个层次,例如在描述时间维时,可以从日期、月份、季度、年等不同层次来描述,那么日期、月份、季度、年等就是时间维的层次;同样,城市、地区、国家等构成了地理维的多个层次。
维的一个取值称为该维的一个成员。如果一个维是多层次的,那么其维成员是不同维层次上的取值的组合。例如,若时间维具有日期、月份、年这3个层次,分别在日期、月份、年上各取一个值将其组合起来,就得到了时间维的一个维成员,即“某年某月某日”。
当多维数组中的各个维都选中一个维成员,这些维成员的组合就唯一确定一个度量值。维和度量的组合称为事实,事实可用多维数组来表示。一个多维数组可以表示为:(维1,维2,…,维n,度量)。例如,在地区、时间和销售渠道上各取维成员“北京”、“2006年12月”和“批发”,就可以唯一确定变量“销售额”的一个值(假设为10000元),则相应的数据单元可表示为:(北京,2006年12月,批发,10000元)。
对于逻辑上的多维数据模型,在物理上也可以使用关系数据模型来实现,星型模型、雪花模型、星网模型等都是典型的实现方式。由于星型模型它是一种最基础的实现方式,雪花模型等可以认为是它的一种扩展,因此下面简要地介绍一下星型模型。
星型模型
星型模型是由一个事实表(大表)以及多个维表(小表)组成,这样一来,逻辑上的“多维”即可以通过物理上的关系模型来表现。图6-2就是一个星型模型实例。
图6-2 星型模型实例
维表是围绕事实表建立的较小的表,一个维表中包含着该维的不同层次的描述,图6-1中的地理维、时间维、产品维就是维表。事实表的关键字由各个维表的关键字构成,因此,事实表与各维表都是一对多的联系。除了关键字之外,事实表中还存放有度量数据,如销售金额及其单位等。因此,事实表中的一条记录就代表着一个事实——维和度量的组合。
通常,维表相对来说有较少的行(记录),而事实表却有大量的行(记录)。事实表与维表均是非规范化的,特别是事实表的非规范化程度很高,例如,多个时期的数据可能会出现在同一个表中。星型模型正是以潜在的存储空间代价,使用了大量的非规范化来优化速度。星型模型针对各个维作了大量的预处理,如按照维进行预先的统计、分类和排序等,所以,在进行数据分析时速度会很快。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











