



(二)变量设计与分析方法
本研究主要使用CGSS2005[50]数据中的居民问卷进行研究。CGSS2005数据包括城乡样本10372个,本文主要考查城市居民幸福感的影响因素,因此笔者只选择样本中的城市居民样本,共6098个。全国城乡居民生活综合调查是一项连续性的中国基本社会状况调查项目,主要目的是了解改革开放20多年来,中国城市居民的就业、教育、社会关系、生活方式和生活环境等方面的状况。
1.变量设计
(1)因变量
本研究的因变量是幸福感,是一个定序变量。这是根据问卷E3“总体而言,您对自己所过的生活的感觉是怎么样的呢?您感觉您的生活是:A、非常不幸福;B、不幸福;C、一般;D、幸福;E、非常幸福”这题内容构建的变量。
(2)自变量
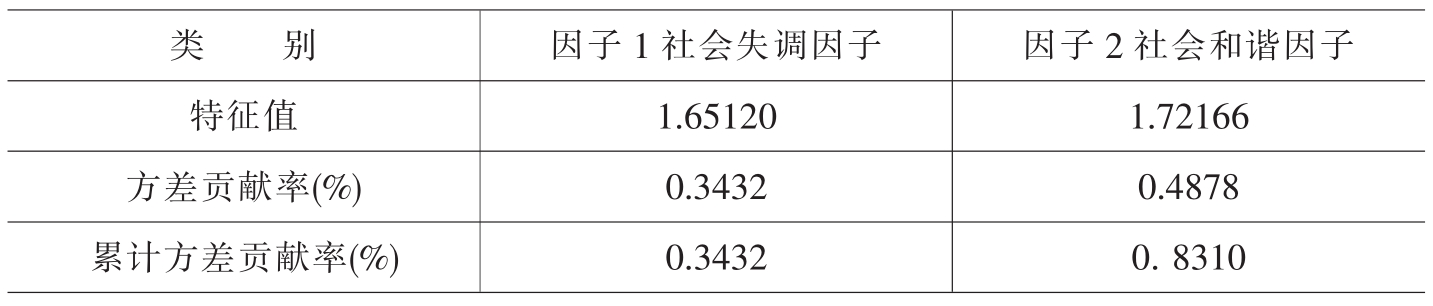
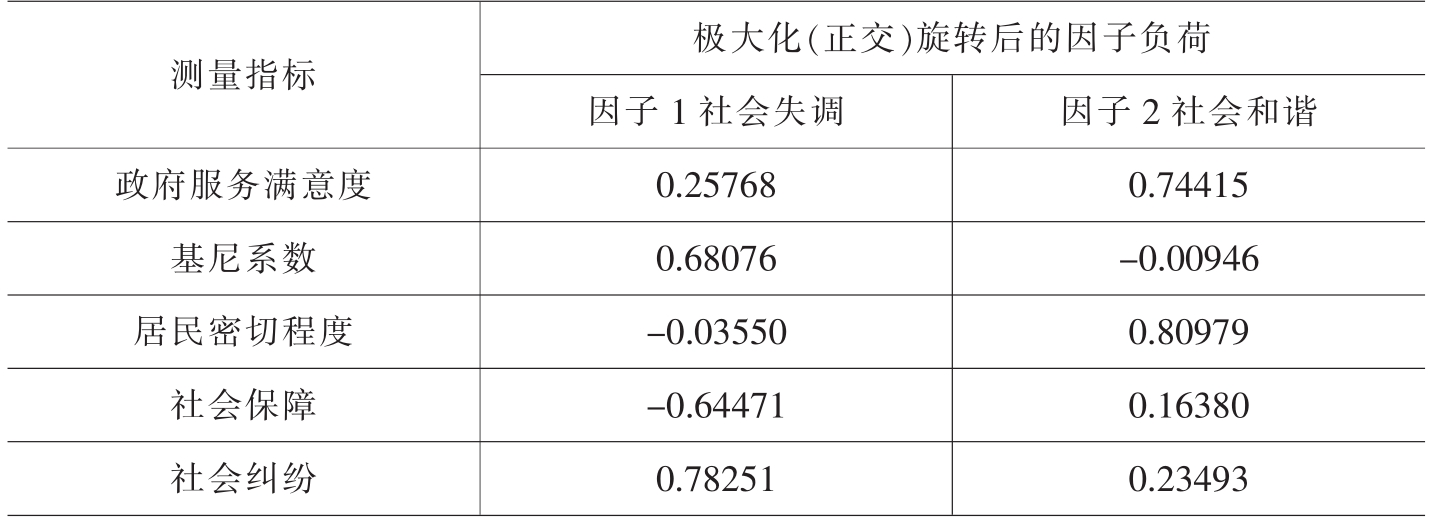
本研究的自变量主要有:(A)住房产权:有住房产权取值为1,无住房产权取值为0。(B)社会和谐与社会失调,为连续变量,由相关的5个社会指标经因子分析得出。这些指标包括:政府服务满意度、基尼系数、居民密切程度、社会保障与社会纠纷。这5个项目互为关联,根据特征值大于1的原则,得到“社会失调”与“社会和谐”这两个因子,其方差贡献率为83.1%(见表V-4-3和表V-4-1),即这两个因子可以反映原指标83.1%的信息量。因子分析的KMO和球形Bartlett检验情况如表V-4-2所示。KMO(Kaiser-Meyer-Olkin)给出了抽样充足度的检验,是用来比较相关系数数值和偏相关系数是否适中的指标,其值越接近1,表明对这些变量进行因子分析的效果越好。本文的KMO值为0.705,说明因子分析的结果是可以接受的。球形Bartlett检验的值为140.518,并在0.01水平上双尾显著,这说明相关系数矩阵不是一个单位矩阵,因此采用因子分析是可行的。
表V-4-1 因子分析的特征值和方差贡献率
表V-4-2 因子分析的KMO和球形Bartlett检验
![]()
注:***表示在0.01水平上双尾显著。
表V-4-3 旋转后的因子负荷矩阵
(3)控制变量
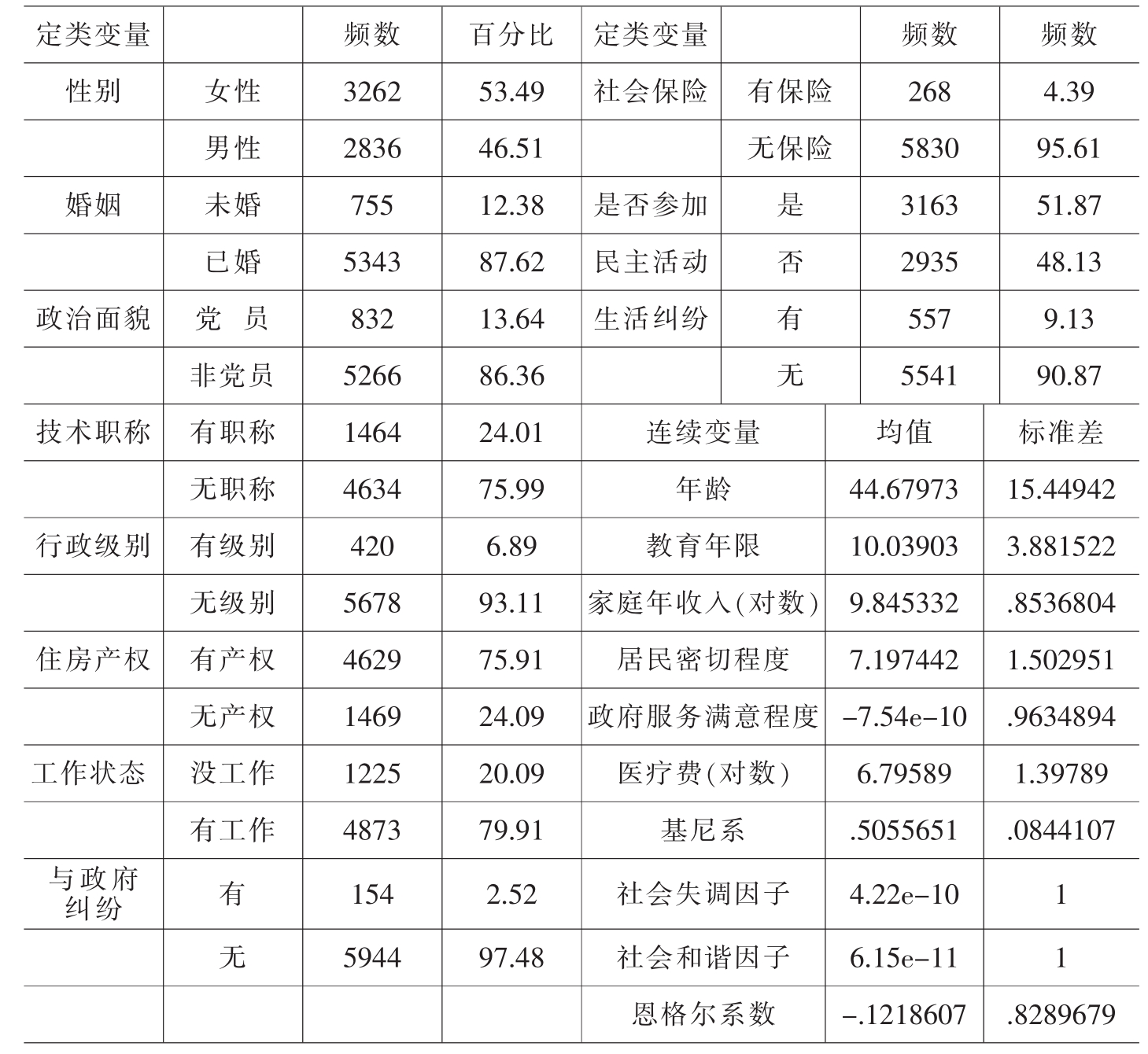
本研究的控制变量主要有:(A)年龄:在模型中按惯例另加入年龄平方项,以捕捉其非线性效用。(B)婚姻状况:已婚取值为1,未婚取值为0。(C)性别:男性取值为1,女性取值为0。(D)教育水平:CGSS2005数据教育水平为定序变量,笔者将其转化为教育年限,变成连续变量。(E)政治面貌:党员取值为1,非党员取值为0。(F)行政级别:无行政级别取值为0,有行政级别取值为1。(G)技术职称:无技术职称取值为0,有技术职称取值为1。(H)收入:主要为居民家庭总收入,取其对数。(I)居民健康状况:主要通过居民的医疗费(取对数)来评估,医疗费越多,健康状况越差。(J)工作状态:有工作取值为1,没工作取值为0。(K)与亲戚朋友联系的密切程度:CGSS2005数据其为定序变量,笔者将其转化为连续变量。(L)社会保险:有相关社会保险取值为1,无相关社会保险取值为0。(M)政府服务满意程度:CGSS2005数据其为定序变量,笔者将其转化为连续变量。(N)民主参与:积极参与民主活动取值为1,不参加民主活动取值为0。(O)生活差距:主要通过恩格尔系数来评估。(P)生活纠纷:有生活纠纷取值为1,无生活纠纷取值为0。(Q)与政府纠纷:与政府有纠纷取值为1,与政府无纠纷取值为0。本研究的相关变量的描述统计见表V-4-4。
表V-4-4 相关变量的描述统计
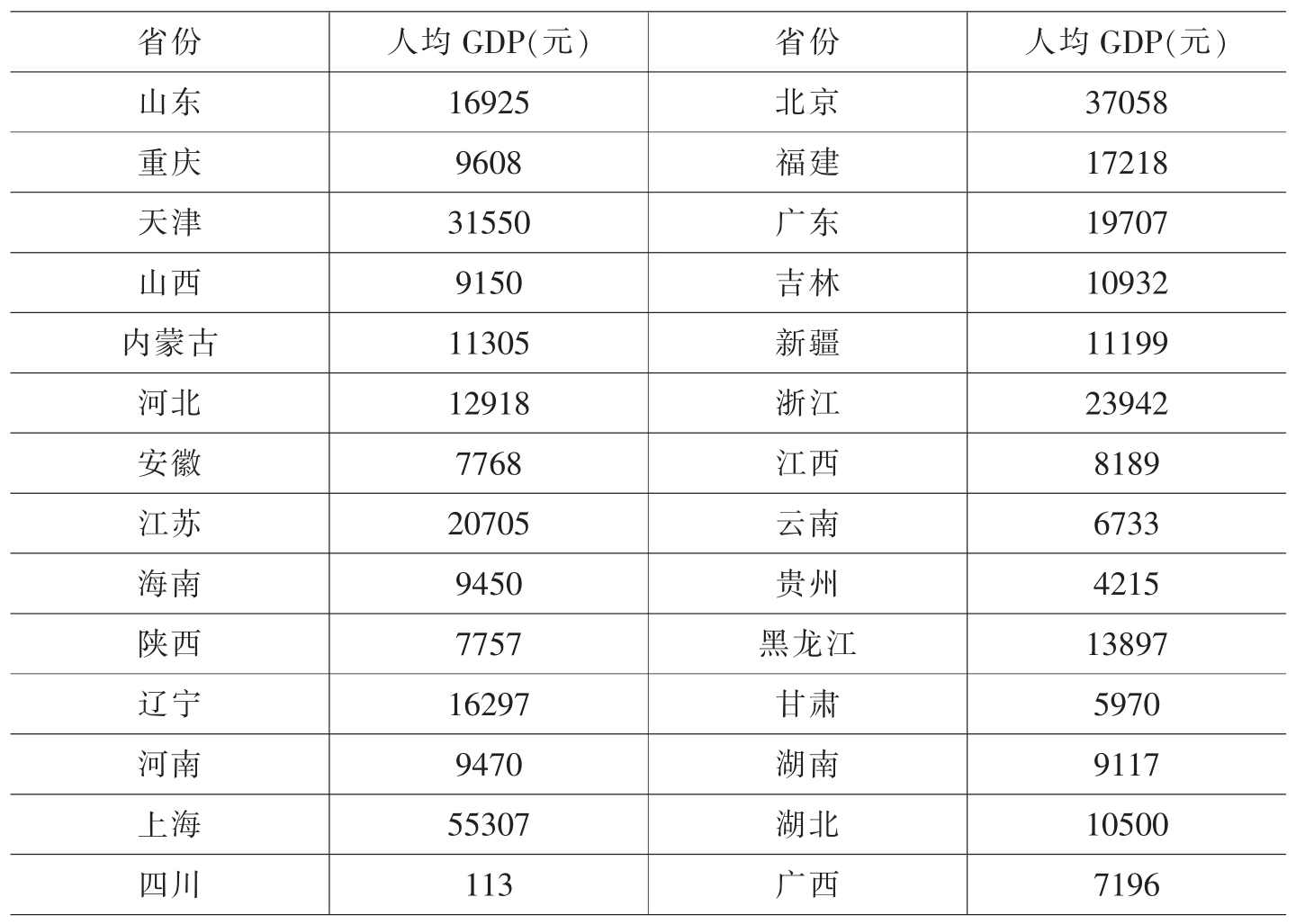
(4)省份层次变量——经济发展水平
在本研究中,笔者选用了人均GDP来反映各地区间经济发展水平的差异。如表V-4-5所示,这里的人均GDP主要来自“中国综合社会调查(CGSS)2005”的数据统计。
表V-4-5 各省经济发展水平(人均GDP)状况表
数据来源:“中国综合社会调查”(CGSS)2005
2.分析方法
本研究涉及微观与宏观两个层次的数据,且城市居民嵌套于各省份之内,对幸福感的影响不仅有居民个体因素的影响,而且还存在省际经济发展水平对幸福感的影响(如图V-4-2所示),也就是说,如果运用一般的回归分析,则不能满足独立性条件。因此,我们使用了多层次模型统计方法,目的是将非独立性的来源纳入方程中来解决这个问题,其具体的计算公式如下:
(1)个体层次
Yij=β0j+β1jX1ij+β2jX2ij+……βkijXkij+rij
在分析中,个体层次的主要变量Xkij为住房产权、社会和谐、社会失调、性别、年龄、婚姻、受教育年限、收入、政治面貌、技术职称、行政级别、医疗费等。βkij为各自变量的回归系数,rij为方程残差。
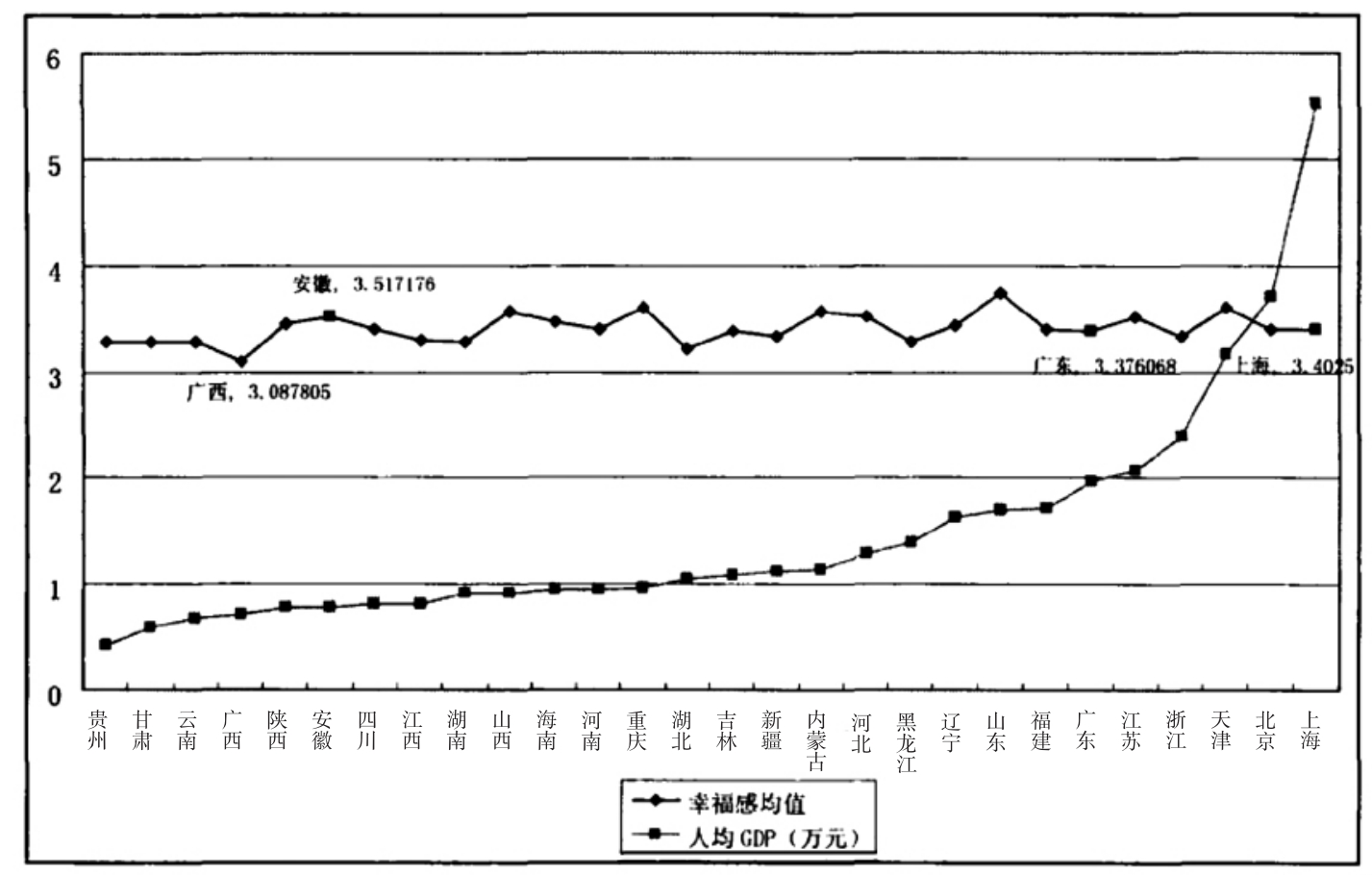
图V-4-2 各省份人均GDP与居民幸福感(CGSS2005)
数据来源:2005年中国综合社会调查(CGSS)
(2)省份层次
β0j=γ00+γ01W1j+u0j
β1j=γ10+γ11W1j+u1j
在二水平的省级层次,主要的变量W1j为各省经济发展水平。其对于因变量的影响主要在两个层次上,一是截距层次,即β0j方程所示,γ01、u0j为截距层次上变量的回归系数与残差;二是斜率层次,即β1j方程所示,γ11、u1j为斜率层次上变量的回归系数与残差。其分别反映了二层次变量各省经济发展水平对因变量的直接结构效应(二层次变量对因变量的直接影响)和间接结构效应(由于二层次变量的作用,使得个体层次变量对因变量的影响程度具有结构性差异)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











