



7.4.1 近红外多元校正方法的原理和应用
由于样品吸收及反射的近红外光量与样品中功能团成正比,仪器记录所得不同波长的反射值可转换成样品的浓度值。
为充分利用近红外光谱所提供信息,需使用合适的计算分析方法处理NIRS数据,一般在对未知样品进行分析前,必须建立一个校正集(亦称建模集),对校正集的每一个样品测量其光谱及其对应的组成或性质。与单波长测定建立标准曲线一样,事先必须用多元校正方法,即以样品的近红外光谱作为自变量,样品的化学值(物质含量)作为因变量,将测量的光谱与样品化学性质或组成数据进行关联,建立起样品近红外光谱与化学值之间的定量数学关系——校正模型,该关系通常无法用直观的数学表达式输出,而是以方法或模型名称保存在电脑中,便于以后随时调用,以预测未知样本的化学值。
本章前面所介绍的多元校正方法如多元线性回归(MLR)、K矩阵、P矩阵及主成分回归(PCR)、偏最小二乘回归(PLSR)等方法均可用于近红外多元校正,其中PLSR算法将多维光谱数据集(维数相当于波长数目)压缩降维,在降维的同时考虑了其与性质矩阵的相关性,通过对PLS潜变量的合理选取,去掉含有干扰组分或干扰因素的成分变量,仅取与因变量关系最大的光谱信息PLS成分变量参加回归,所建立校正集模型通常优于MLR与PCR法。因此,PLSR是目前在近红外光谱中应用最多的一种多元校正方法,在所有近红外仪所配的化学计量学软件中均有该方法,甚至有些仪器商在近红外仪的定量分析方法中只配置PLSR算法。
下面我们通过一个例子来演示近红外技术进行化学多元校正(定量分析)时的步骤。
例7-2 冰片缓释制剂由冰片、乙基纤维素和聚乙二醇4000按合适的配比制成,为优化缓释制剂的配方及包合条件,需要对配制的缓释样品在不同时间点下快速、准确测得其中冰片含量,采用传统GC方法需要进行样品预处理,耗时较长。本例通过测试样品溶液的近红外光谱,采用PLSR法建立近红外光谱与冰片浓度间的定量模型,实现快速、简便测试冰片缓释制剂中冰片含量的目的。
步骤1:样品溶液的配制
由于冰片不溶于水,本例采用50%乙醇作为溶剂,因辅料乙基纤维素不溶于50%乙醇,故样品配制时只需选取冰片和聚乙二醇4000,准确称取一定量的冰片和聚乙二醇4000,溶于50%乙醇溶液,配制出冰片浓度范围在0.6~10mg·mL-1的一系列标准溶液44个。
步骤2:测试样品溶液的近红外光谱
以空气作参比,样品放入2mm石英比色皿进行光谱扫描,扫描次数80次,仪器分辨率为8cm-1,环境温度保持25℃。样品近红外谱图如图7-1所示。
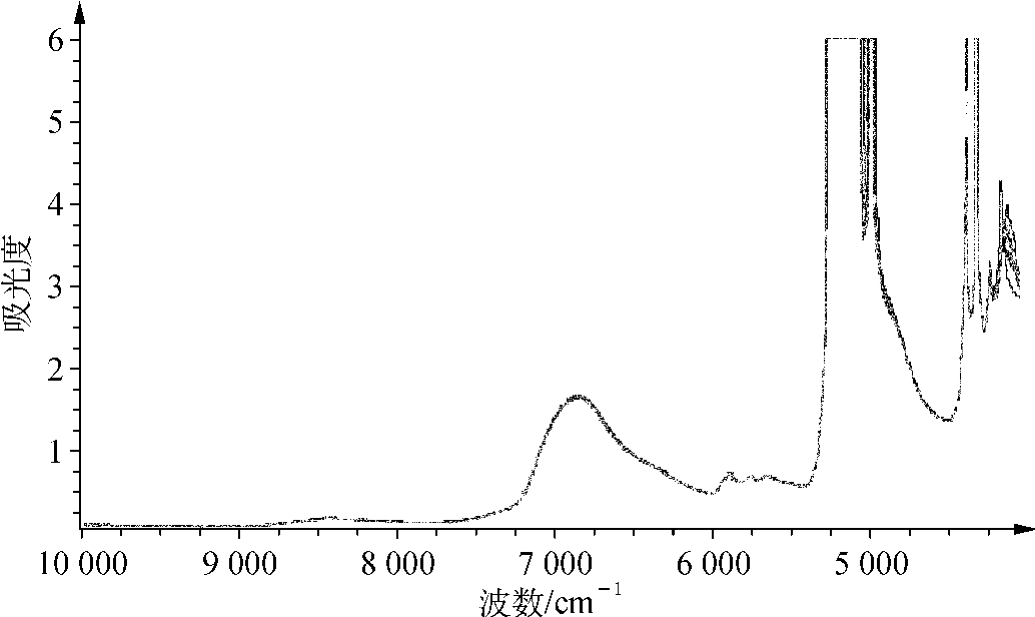
图7-1 不同浓度冰片溶液的近红外光谱
步骤3:PLSR建模与模型评价
采用仪器自带软件进行PLSR建模,软件采用6.4.5节中介绍的内部交叉验证指标PRESS确定最佳潜变量(LV)个数,然后采用所建模型对未参加建模的预测集中样品进行定量预测,通过计算检验集样本的模型值与实际值的相关系数r或检验集的均方根差RMSEV(Root Mean Square Error of Validation set,RMSEV)检验模型的预测功能、比较模型的决定系数(R2)和建模集均方根差(Root Mean Square Error of Calibration set,RMSEC)来评价模型的模拟功能。
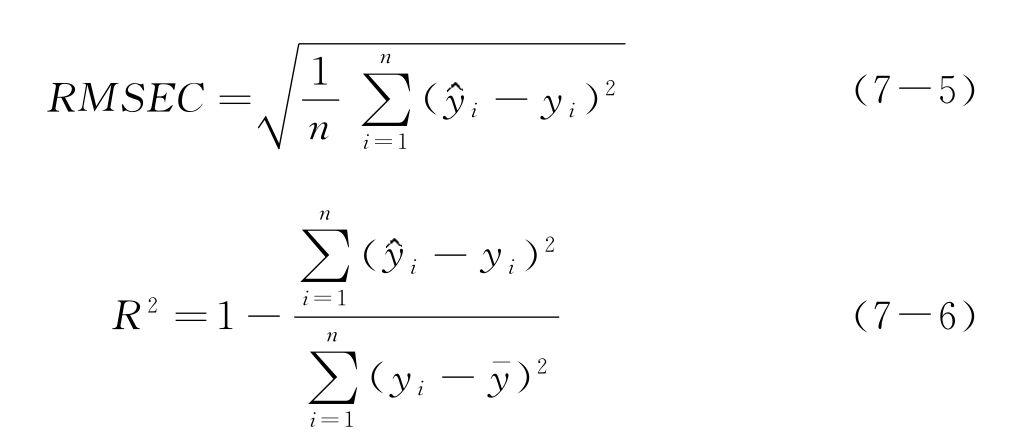
式中,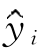 ,yi分别表示第i个建模样品的模型值与真实值;n为建模样品数;y-为n个建模样品模型值的平均值。RMSEV的计算与式(7-5)相似,只是其中的样本求和是对检验集样本求和而不是对建模集样本求和。
,yi分别表示第i个建模样品的模型值与真实值;n为建模样品数;y-为n个建模样品模型值的平均值。RMSEV的计算与式(7-5)相似,只是其中的样本求和是对检验集样本求和而不是对建模集样本求和。
步骤4:模型参数的优化
由图7-1可知,在5 200cm-1与4 300cm-1附近有两个饱和峰,这一区间不宜用于建模。在软件建议的建模波数范围(5 314~7 566cm-1)基础上经过比较不同区间所建模型的R2、RMSEC,最终确定最佳波长范围为5 314~7 032cm-1。
采用5 314~7 032cm-1的原始近红外光谱分别对全浓度、高浓度、中低浓度样品建立了模型1(校正集38个样本,检验集样本数6个样本)、模型2(校正集22个样本,检验集5个样本)、模型3(校正集29个样本,检验集8个样本)。结果见表7-4。
表7-4 不同浓度范围样品建模效果比较
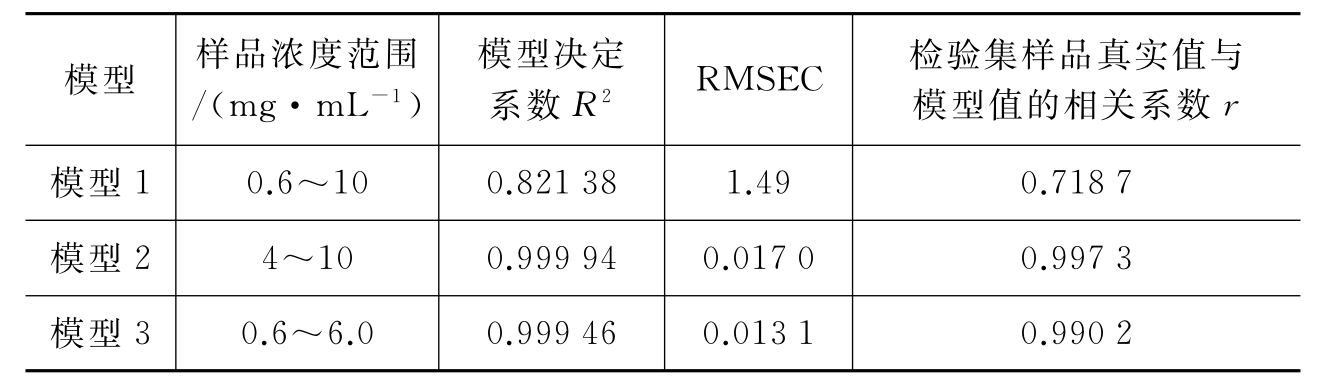
可见,全浓度范围内建模模型参数与预测效果均不及划分浓度范围的结果,实际应用时应根据样品的浓度区间采用合适的模型预测样品中冰片含量。
步骤5:冰片缓释制剂体外释释药的考察
将冰片、乙基纤维素和聚乙二醇4000按两种不同配比制得两种缓释制剂(样品1与样品2),将其溶于一定量的乙醇中,在室温下不断搅拌使乙醇挥发,混合物再放置一段时间至没有乙醇味得到冰片固体分散物。
分别于5min、10min、20min、30min、40min、60min、100min、120min、180min、240min、300min、360min、480min取样1mL样品进行近红外光谱测试,选用模型2预测样品中冰片浓度,进行缓释制剂体外释药效果考察。
释放度的测定以冰片相对累积释放率为指标,其计算公式如下。
相对累积释放率=ci/c
式中,ci为定时取样的样品浓度;c为完全释放时样品浓度(以溶液超声0.5h后样品浓度作为完全释放时浓度)。
制备的缓释样品1、2在不同时间下冰片的累积释放率见图7-2。
由图7-2可知缓释制剂1在30min达到突释(释药41.02%),以后缓慢释放,8h释放不完全(释药76.89%)。制剂2在10min释药71.01%,100min释药93.06%,480min释药97.38%。制剂2 10min达到突释,8h后几乎释放完全。
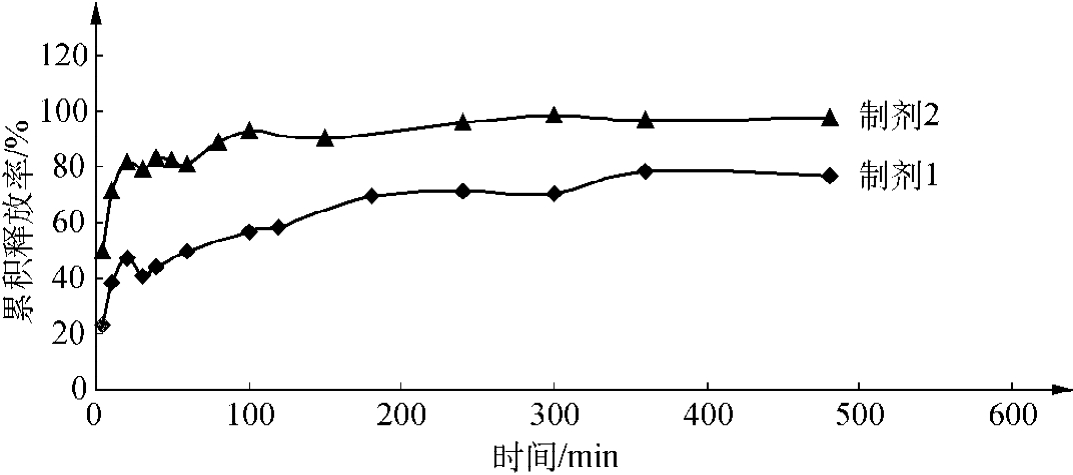
图7-2 缓释制剂的冰片释放曲线
通过本例可以总结出采用近红外技术进行定量分析的基本步骤如下。
(1)构造和选取建模集样本,获取其因变量的数值矩阵。如果建模集样本像例7-2一样是自行配制的,则其化学值(浓度)不用测试,根据配制比例可以获得浓度数据;否则,需要采用传统分析测试方法获取相关性质。如文献[2]采用HPLC方法测试丹参提取液中丹酚酸B和丹参酮IIA的浓度,文献[3]采用流动注射分析方法获取烟叶主要成分的含量。假设建模样本数为n,因变量个数为q,则建模集因变量构成一个Yn×q矩阵。
(2)测试建模集样本的近红外光谱,获取已知样本的自变量数据。假设建模样本数为n,近红外光谱点数为p,则建模集近红外光谱构成一个Xn×p矩阵。
(3)采用多元校正方法(如MLR、K矩阵、P矩阵、PCR及PLSR等)建立建模集自变量矩阵Xn×p与因变量矩阵Yn×q间的数学关系。
(4)对建立的近红外定量分析模型进行评价。对于近红外定量分析模型通常采用以下评价指标来考核模型的性能。
①决定系数R2。决定系数的计算公式见式(7-6),该指标反映了建模样本的模型值与实测值之间的线性相关程度,R2越接近于1,表示所有样本点在以模型值为纵坐标、实际值为横坐标的坐标系里距45°的直线越近,即实际值与模型值差异越小。决定系数反映了模型的拟合功能。
②建模集均方残差RSMEC。RSMEC反映了样品实测值与模型拟合值之间的平均残差平方和的开方,其计算公式见式(7-5)。均方残差值越小,表明模型值与实测值之间的误差越小,该指标体现了模型拟合建模样品数据的程度。
③留一法预测均方残差PRESS。上述两个指标均描述了模型的拟合功能。建立模型的目的是为了预测未知样本的有关性质,如果一个模型对于已知样品的数据拟合很好但预测误差却很大,这个模型就没有实际应用价值。PRESS可在一定程度上体现模型的预测功能,其计算公式见式(6-74)。PRESS是最终决定模型参数(潜变量个数、光谱区间、光谱预处理方法等)选择的决定性指标。
④检验集均方残差RSMEV。检验集用于检验模型预测功能,不参加建模仅用来做预测,其样本的化学性质已知。设检验集样本个数为nv,其检验集样本的因变量模型值与其实际值的均方根残差记为RSMEV,其计算公式如下
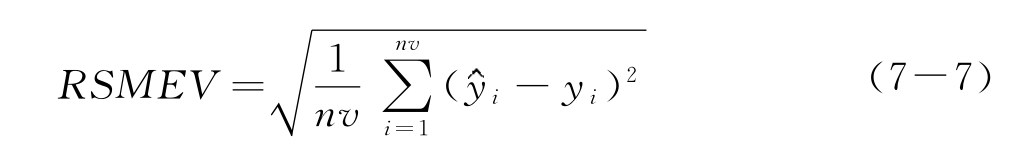
如果RSMEV偏大,说明该模型预测功能欠佳,即使相关系数R、建模集均方根残差RSEMC均很理想,只表明模型可以很好地拟合建模样本的数据,但不能很好地预测未知样本,这个模型就不是成功的,不可用其预测相关的化学值。
(5)根据建立的模型及预测集样本的近红外光谱预测其因变量。由于近红外光谱获取十分便捷、快速,只要采用性质已知样本建立近红外光谱与待求化学性质(这些化学性质应当与近红外吸收密切相关,最常见的化学性质就是物质浓度)间的数学模型,就可以根据未知样本的近红外光谱预测其物质浓度(含量)。近十年来,采用近红外定量分析技术进行混合物系中物性(主要是化学性质)快速预测的文献报道可谓汗牛充栋。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











