



二、量表的类型
量表在社会调查研究中的应用越来越广泛,人们在长期的实践过程中也总结出了一些制作量表的方法,形成一些具有典型意义的量表类型。
1.总加量表
总加量表又称“里克特量表”,是1932年由里克特提出并使用的。总加量表是最为简单、同时也是使用最为广泛的量表。其主要目的是用来测量人们对某一事物的看法和态度,主要形式是询问答卷者对某一陈述的判断,并以不同的等级顺序选择答案,如“非常同意”、“同意”、“不同意”、“非常不同意”等。如表4-3就是总加量表的一个例子。
表4-3 请表明您对下列问题的态度

总加量表按可供选择的答案的数量的不同,可以分为两项选择式和多项选择式两种形式。两项选择式只设同意、不同意,或是、不是两项可供选择的答案,如表4-3所示。多项选择式通常设非常同意、同意、说不上、不同意、非常不同意五个等级供选择,如表4-4所示。多项选择式量表由于答案类型的增多,人们在态度上的差别就能更清楚地反映出来。因此这种量表比两项选择式量表要用得更多一些。
按陈述所代表的态度倾向的不同,总加量表又可以分为完全正向式和正向与负向混合式两种形式。表4-3中的陈述都是谴责随地吐痰行为的陈述,故是完全正向式的表达形式。表4-4中的陈述中,“人们应当劝导和说服亲友和邻居节制生育”是对节制生育制度抱肯定态度的一种正向式陈述,而“控制生育是违反天意的,应当顺其自然地生育”是对节制生育制度抱否定态度的一种负向式陈述。这种混合式量表的正向式陈述与负向式陈述之间由于能起到互相印证和检验的作用,故而能更准确地反映人们的态度倾向,因此这种量表就比完全由正向式陈述构成的量表用得更普遍。
设计总加量表的具体步骤是:
(1)确定主题,并以赞成或反对的方式写出若干与主题相关的看法或陈述。
如测量人们对节制生育的态度,提出如下问题(见表4-4)。
表4-4 人们对节制生育的态度量表
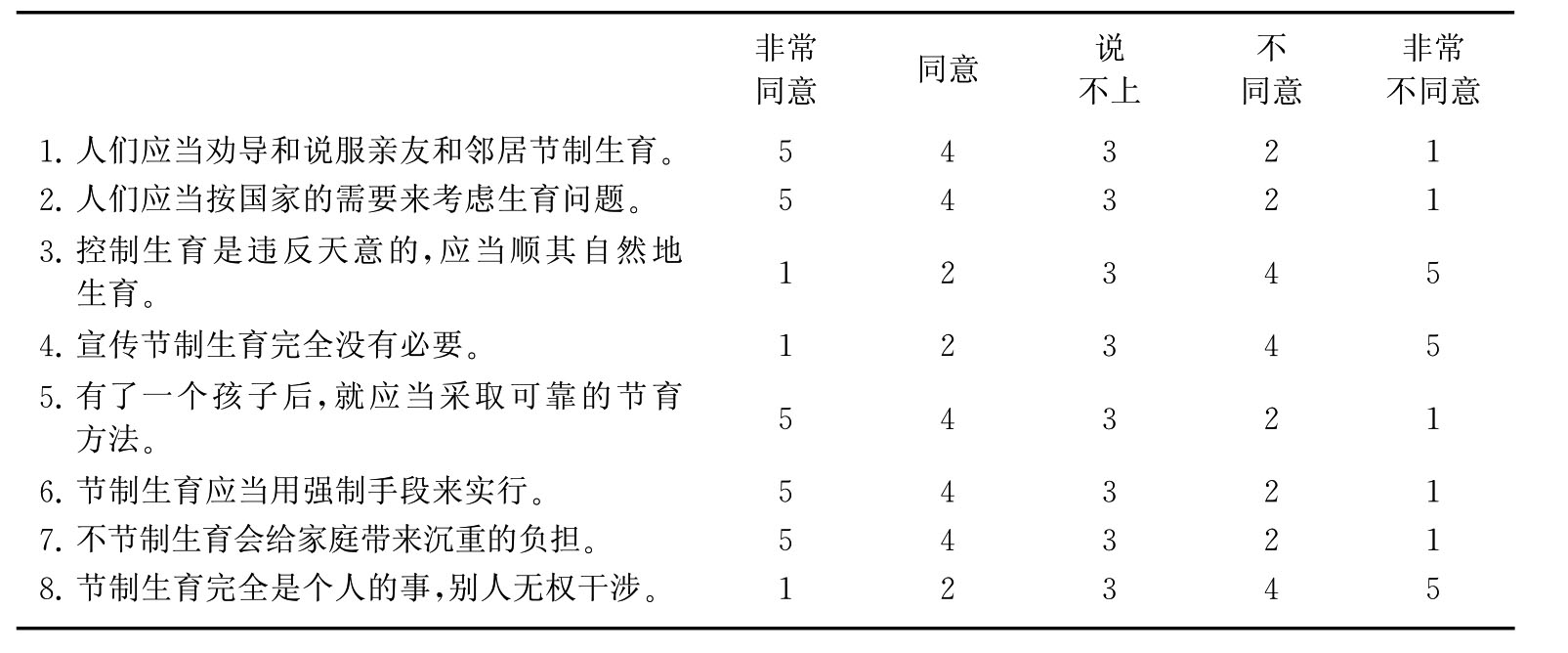
(2)对每一个问题均有“非常同意”、“同意”、“说不上”、“不同意”、“非常不同意”五种回答,每个回答均要记分。在总加量表中,一般都会有正向问题和负向问题,如果正向问题如“人们应当劝导和说服亲友和邻居节制生育”记为5、4、3、2、1分,那么负向问题如“控制生育是违反天意的,应当顺其自然地生育”就记作1、2、3、4、5分。
(3)试调查。从调查对象中抽出一部分样本进行试测,以便发现量表设计中有什么问题,是否会引起误解,更重要的是检查每道题的分辨力。具体方法是计算出每一个人的全部答案的总分,计算得分最高的25%和得分最低的25%的试测者在每一个问题上的平均分,两者相减所得的差为辨别力评分,辨别力评分高的问题保留,辨别力评分低的问题删掉。如上例,对一个社区中20人进行试测,若得分最高的25%的5人在第一题的得分分别是5、4、4、5、5分,得分最低的25%的5人第一题的得分分别是2、2、1、1、1,那么,得分最高的5人在第一题的均分为(5+4+4+5+5)/5=4.6,而得分最低的5人在第一题的均分为(2+2+1+1+1)/5=1.4,两者相减4.6-1.4=3.2即为第一题的分辨力系数。分辨力系数越小,就说明这一题的分辨力越低,分辨力低的题目应该删除。
(4)经过筛选,选择一组辨别力高的问题组成量表。
(5)选择调查对象,发送量表让被调查者填写。
(6)计算每一个被调查者在所有问题上答案的总分数,这个分数就是每个人关于这一社会现象的态度和看法。
总加量表可以测量每个被调查者的社会意向,即个人的总的态度倾向,也可以测量全体被调查者关于某一问题的平均倾向,这时只要把全体被调查者所得分数加总,再除以被调查人数,就测出全体被调查者关于某一问题的平均倾向。
总加量表的最明显的优点是设计容易;其次它的适用范围比其他量表要广,可以用它来测量一些其他量表不能测量的某些多维度的复杂概念;再次,总加量表的五种回答形式使回答者能够很方便地标出自己的位置。
总加量表的最主要缺点是相同的态度得分者有可能具有十分不同的态度形态。因为总加量表是以各项目总加得分代表一个人的赞成程度,它可大致上区分个体间谁的态度高谁的态度低,但无法进一步描述他们的态度结构差异。
2.语义差异量表
语义差异量表又叫语义分化量表,最初由美国心理学家C.奥斯古德等人在他们的研究中使用,20世纪50年代后发展起来。在社会学、社会心理学和心理学研究中,语义差异量表被广泛用于文化的比较研究,个人及群体间差异的比较研究,以及人们对周围环境或事物的态度、看法的研究等等。语义差异量表以形容词的正反意义为基础,标准的语义差异量表包含一系列形容词和它们的反义词,在每一个形容词和反义词之间有约7至11个区间,我们对观念、事物或人的感觉可以通过我们所选择的两个相反形容词之间的区间反映出来。如表4-5、表4-6都是语义差异量表的例子:
表4-5 你对婚姻的感觉如何?
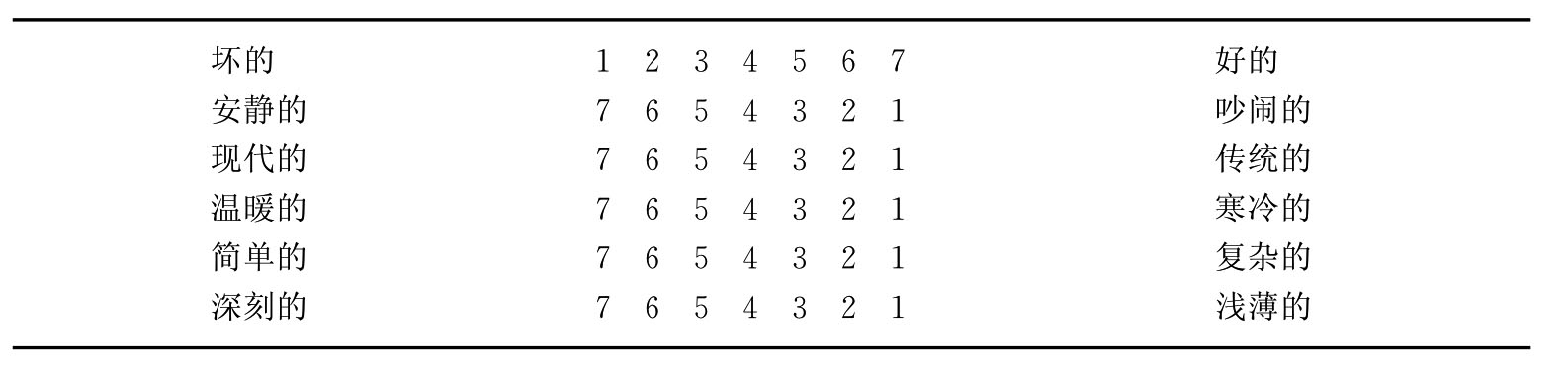
表4-6 你对同事们的印象和评价如何?

在使用语义差异量表时,要特别注意尽可能全面地包括概念、事物或人的各个层面。同时,以表4-6为例,合作、愉快、精力充沛、效率高、聪明等是正指标,可从左到右以7至1记分;吵架、自私、爱挑衅、苛刻等是负指标,可从左到右以1至7记分。这样,同较高分值对应的是正指标,同较低分值对应的是负指标。测量结果出来后,有两种处理方法:一是单个加总记分,把每个被调查者所有回答的分值加起来,计总分,这是每个被调查者个人的感觉和评价得分;二是求整体平均数,即将所有被调查者总分加起来除以人数,得算术平均数,这个算术平均数就是群体平均的感觉和评价。
语义差异量表有一个缺陷,即询问比较模糊,程度上的差异很难把握,且在形成一个总的印象与评价过程中,个人也会把经验等因素掺入进来。但尽管有缺点,这种测量方法仍然是有效的,因为求所有被调查者回答的平均数,能够中和一些偏见与极端的看法,作为平均倾向,可以对各种群体进行比较与评价。
3.鲍格达斯社会距离量表
鲍格达斯社会距离量表产生于20世纪20年代,主要用来测量人们相互间交往的程度、相互关系的程度或对某一群体所持的态度及所保持的距离。例如,要测量人们对外国人的容纳程度,可以用下面的表4-7测量。
表4-7 人们对外国人的态度量表
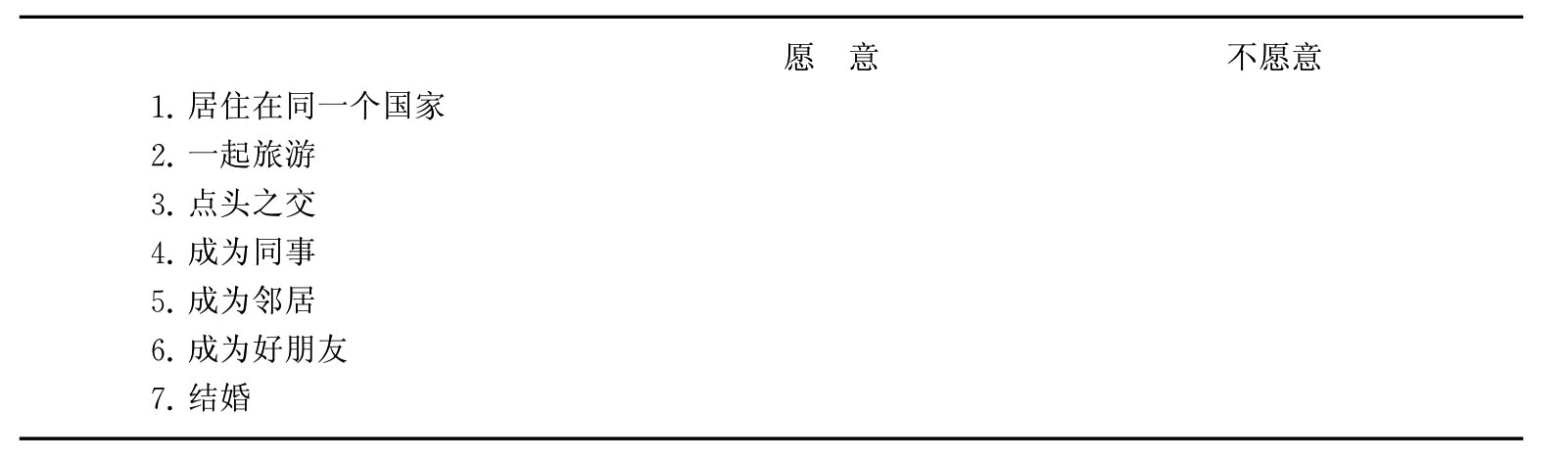
上表七个指标之间有一个顺序结构,如果我们愿意与一个不同种族的人结婚,我们当然也愿意与他成为朋友、邻居和同事。即使我们不愿意与一个不同种族的人结婚,但如果我们愿意与他成为朋友,当然可以和他成为邻居、同事。按此逻辑推理下去,鲍格达斯社会距离量表的每一个指标都是建筑在前一个指标之上的。它的优点在于极大地浓缩了数据。鲍格达斯社会距离量表的原则也可以用到其他概念的测量上去,是一个很经济实用的指标。
4.累积量表
累积量表又叫“古德曼量表”,主要测量人们的态度倾向等级。与上述量表不同,它不是一种现成可使用的量表,而是需先依据数据构筑标度,再建立量表。它的最主要特征是量表中后一等级积累了前一等级的强度,受访者只要支持某个较强的变量指标,就一定会支持较弱的指标。如:我们都知道乘除法较加减法难,掌握乘除法的人也应相应地掌握加减法,而根号计算又比乘除法难,掌握根号的人应会乘除法和加减法。因此在加减法、乘除法和根号之间实际上存在着一种强度结构。现在,我们假设不清楚加减法、乘除法与根号之间是否存在着这样一种强度结构,而试图用累积量表的方法来检验能否构筑这样一个量表。
由于累积量表的构筑是采集数据在先,因此,我们选了100名6至12岁的儿童,分别测试他们对加减法、乘除法与根号计算的能力。下面是这100名儿童的测试结果。

从回答中可以看出,在八种可能的组合中,绝大多数的回答属于1、2、3、4四种模式。而这四种模式又排成一种顺序结构,第一种模式是三种能力全无;第二种模式是会最容易的加减法,但不会乘除法与根号计算;第三种模式是会最容易的加减法和比较容易的乘除法;第四种模式是三种全会。由于这四种模式表达了加减法、乘除法、根号计算的顺序关系,我们把它们称为具有可标度性的模式。属于5、6、7、8四种模式的回答只有5个,其中5名儿童会乘除法,但不会加减法与根号计算,这不符合实际情况。由于后四种模式都不符合加减法、乘除法与根号计算的顺序关系,我们把它们称为不具有可标度性的模式。如果具有可标度性的模式为正确的模式,那么这些不具有可标度性的模式就是错误的模式。
根据具有可标度性模式的人数与总人数之比,我们可以计算出累积量表的一致性系数。一致性系数又称再现系数,表示在所有回答中保持一致性的程度,或者说所有回答中以相同形式再现出来的程度。显然,在所有回答中,去掉反常回答的百分比,就是保持一致性的回答的百分比。
![]()
上例中,在100名儿童中有5名选择了错误的模式,错误回答数为5。100个人回答3个问题,回答总数为300。因此,一致性系数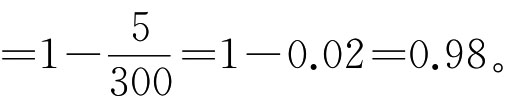 一般说,一致性系数必须达到0.90或0.95以上,累积量表的构筑才能算是成功的。
一般说,一致性系数必须达到0.90或0.95以上,累积量表的构筑才能算是成功的。
累积量表的设计步骤如下:
(1)就某一调查主题提出若干测量项目,即根据测量的特征选择若干问题。
(2)每个项目的答案均为“是”、“不是”或“同意”、“不同意”。
(3)让部分被调查者进行填答,收集数据,去掉那些不能很好区分是赞成的回答还是不赞成的回答的陈述。如要了解人们对堕胎的态度,可先抽样调查人们在各种不同情况下支持女性堕胎的百分比,以1996年美国全国社会调查的一个样本为例[2],如表4-8。
表4-8 支持女性堕胎的百分比

(4)按调查数据排列这些陈述的内在结构,算出一致性系数。在上述三种情况下的支持率差别表现了受访者对各项目支持的不同程度。如果他支持未婚女性堕胎,那么他也应支持因强奸而怀孕的堕胎,当然他也会支持女性生命受到严重威胁时的堕胎。这样构成了初步的等级结构之后,再利用收集到的数据进行如表4-9的排列。
表4-9 支持堕胎的量表分析
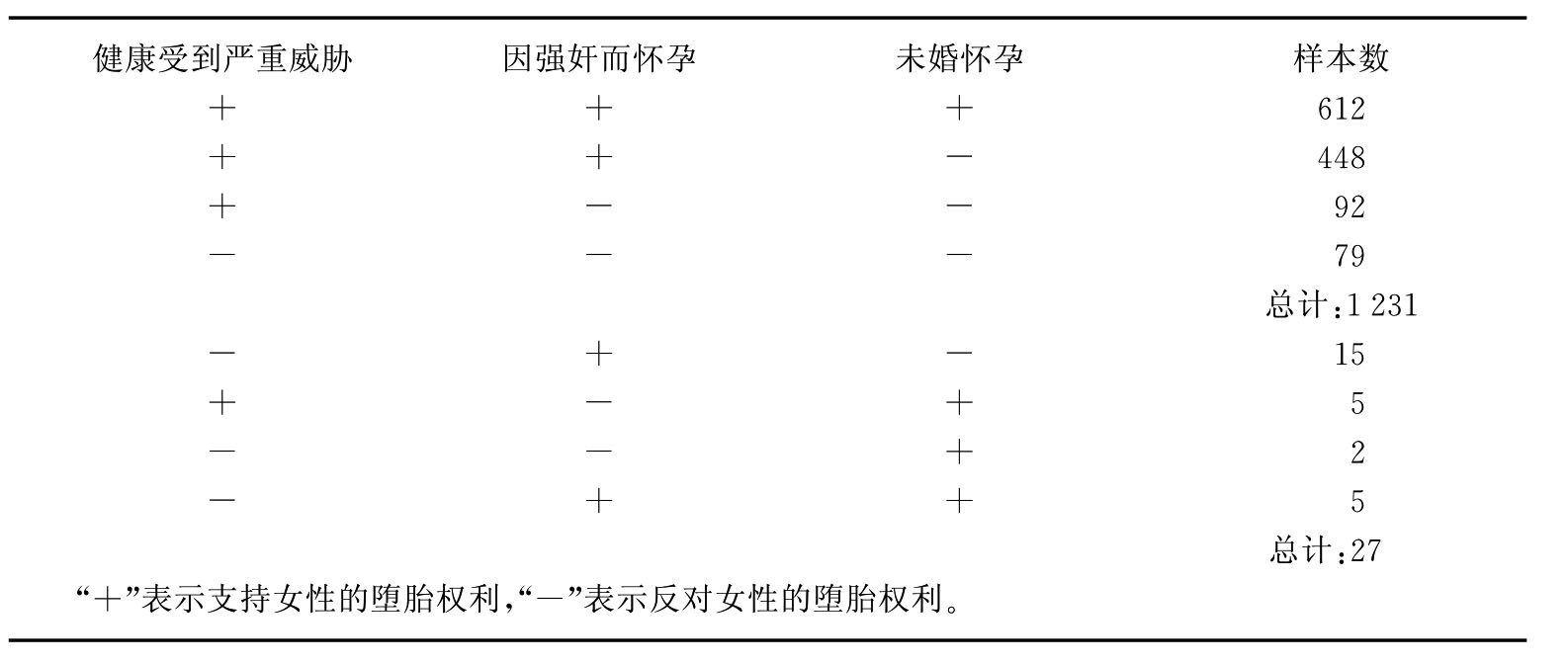
该表的后四个回答类型显示的是违反项目等级结构的回答模式,即他们接受较难作决定的项目而拒绝较易作决定的项目。根据分析,算出一致性系数,即一致性系数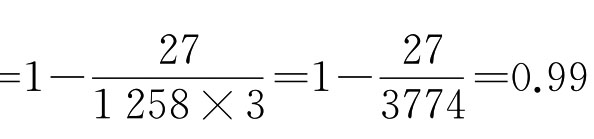 。显然,一致性系数符合要求,我们能够划定测量的等级结构。
。显然,一致性系数符合要求,我们能够划定测量的等级结构。
(5)划定了测量项目的等级结构后,把这些陈述按等级排列,给每个测量项目均使用相同的回答等级,并计分(如“完全同意”计5分、“同意”计4分、“不知道”计3分、“不同意”计2分、“完全不同意”计1分),制成量表。
(6)根据全体被调查者的回答,计算每一个测量项目等级的总得分和各测量项目的得分平均值,并按平均值的高低将项目排列起来。得分平均值高的测量项目是被调查者的主要态度倾向。
如前所述,总加量表有个缺陷,即许多人对于量表的回答各不相同,但它们所得总分却可能是相同的。这样,它就无法进一步描述被测量者的态度结构差异。而累积量表自身结构中存在着某种由强变弱或由弱变强的逻辑关系,它的每一个量表总分都只有一种特定的回答组合与之对应。但累积量表也有弱点,它是由一组具有单维性质的问题组成的,这种单维性往往只是某一部分人的态度模式。一组特定的陈述可能在某一群体中表现出单维模式,却不一定在其他群体中也表现出这样的单维模式。此外,由于累积量表要求严格按单一维度设计问题,故设计起来十分困难。所以,在现实的研究中,累积量表不如总加量表应用广泛。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











