



3.3 字面相似度计算模型
根据字面相似度来判断词汇(或者字符串)之间的语义相似度,国内外针对不同的语种进行了大量研究。其中最著名的研究成果是Ehrig等人提出的编辑距离法。所谓编辑距离,是指将一个英文单词转化为另一个英文单词所需要的最小编辑操作次数。编辑距离法噪音比较大,两个毫无相关的单词往往具有较高的语义相似度值,例如:“Power”和“Tower”[1]。由于智能信息检索和自动翻译的需要,国内学者从20世纪90年代开始研究基于字面相似度的汉语词汇语义相似度计算模型。主要包括以下几种类型:
(1)简单字符匹配模型
假设有A和B两个词汇,N表示A和B的相同字符数,C1表示N与A的总字符数之比;C2表示N与B的总字符数之比。那么,N、C1、C2共同构成了A和B之间的匹配度,根据C1、C2的值可以判断A和B之间的相似度。这种方法比较简单,但是准确率较低[2]。
(2)位置权重匹配模型
简单字符匹配法只考虑了词汇之间的字符匹配度,忽视了匹配字符所在的位置(称作“匹配序”)。调整匹配度和匹配序的权重(分别用α和β表示),可以在一定程度上提高准确率。在这种情况下,α和β之和等于1。根据黄金分割律,二者通常定义为0.6和0.4[3]。
(3)重心后移规律匹配模型
所谓重心后移规律,是指汉语中大多数特定领域的专业术语,其语义重点往往集中在后半部分字符串。因此,在位置权重匹配法的基础上引入重心后移规律,可以进一步提高准确率[4]。具体定义如下:
![]()
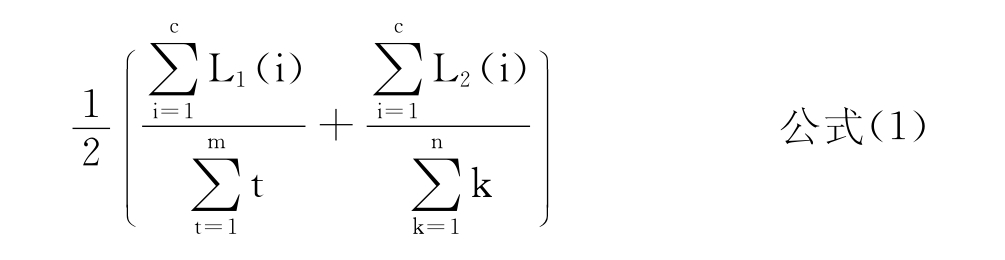
其中,S1和S2分别表示两个汉语词汇。如果词汇中有英文字母,则将连续的英文字符串作为一个汉字处理。m和n分别表示S1和S2的字符总数,c表示S1和S2的匹配字符数量,L1(i)和L2(i)分别表示匹配字符i在S1和S2中的匹配序。匹配序按照从左到右的顺序,从1开始以自然数递增的方式计算。例如,S1=“平面控制点”和S2=“一等平面控制点”,S1和S2的匹配字符为“平”、“面”“控”、“制”、“点”。它们在S1中的匹配序为“1(平)、2(面)、3(控)、4(制)、5(点)”,在S2中的匹配序为“3(平)、4(面)、5(控)、6(制)、7(点)”。那么,S1和S2的语义相似度定义为:
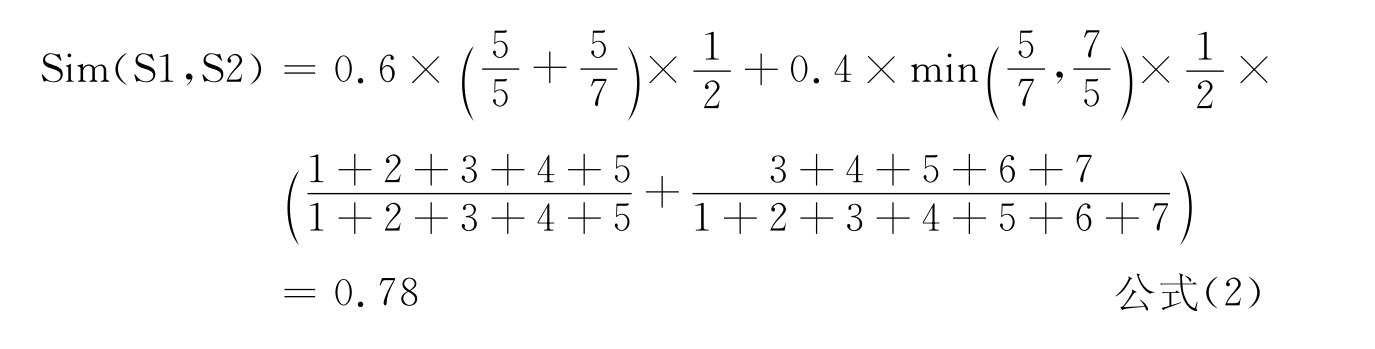
在分类表中,类名是对其相应类别语义的文字描述。类名之间的语义相似度,在很大程度上可以反映类别之间的语义相似度。类名可以看作是一个汉语词汇或者字符串。因此,我们假设,类名之间的字面相似度可以作为类别语义相似度的重要判断标准。本文选择重心后移规律匹配法作为类别语义相似度计算方法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










