



6.1 网络爬虫原理
进入21世纪以来,科技的进步特别是互联网技术飞速发展,使我们的生活更加便利。网络已经成为我们生活中不可或缺的重要工具。但与此同时,海量的无序信息使我们获取有用信息更加困难。我们怎样才能高效地利用网络获取信息满足我们的需求呢?随着信息检索技术不断进步,特别是一些优秀的搜索引擎的出现,给用户带来了许多方便。对信息检索以及相关技术,如情感挖掘、语义消歧、垂直检索、语义网等技术的研究与实践都不断深入。用户有了更加多元的方法进行信息检索。尽管技术发展日新月异,但各大搜索引擎都需要网络爬虫这一关键技术来获取信息源。下面我们将介绍网络爬虫技术。
6.1.1 网络爬虫定义
网络爬虫(WebCrawler)是一个计算机程序或脚本。它的主要工作就是从互联网上有序地、自动地采集信息。根据不同人的习惯,WebCrawler还有一些别称,如ants、automatic indexers、bots、worms和Web spider。
WebCrawler是按照特定策略自动执行的程序或脚本,可以实现对互联网的遍历和信息采集。采集的过程称为Web Crawling。许多网站,特别是一些搜索引擎如Yahoo、Google等,就是利用这个信息采集过程来获取最新的数据。采集通常从一个初始的URL集合开始,通过HTTP、HTTPS等Web协议,依次访问链接指向的页面,并自动提取Web页面上的链接,将它们放到待采集的队列中,实现从一个网页向另一个网页的爬取,直到实现采集器定义的停止策略才停止爬取。
6.1.2 网络爬虫基本原理
网络爬虫现在已经广泛地应用到各大搜索引擎网站,尽管主流搜索引擎如Baidu、Google等在搜索策略中参数的设置有些差异,导致对同一关键词进行检索得到的结果排序有所不同,但是他们所利用的网络爬虫的基本原理是一致的。
一个典型的网络蜘蛛工作的方式为:查看一个网页,并从中找到相关信息,然后它再从该页面的所有连接中出发,继续寻找相关的信息,以此类推。网络蜘蛛在搜索引擎中的位置如图6-1所示。
初始化时,网络蜘蛛一般指向一个URL(Uniform Resource Locator)池。在遍历World Wide Web的过程中,按照深度优先、广度优先或其他启发式算法从URL池中取出若干URL进行处理,同时将没有被访问过的URL放入URL池中,这样处理直到URL池为空为止。对Web文档的索引则根据文档的标题、首段落甚至整个页面内容进行,这取决于搜索服务的数据收集策略。网络蜘蛛在爬行过程中,根据页面的标题、头、链接等生成摘要放在索引数据库中。如果是全文搜索,还需要将整个页面的内容保存到本地数据库。
为了能够快速浏览整个互联网,通常网络蜘蛛采用抢先式多线程技术实现网络信息的搜索。通过抢先式多线程的使用,就能索引基于URL链接的Web页面。启动一个新的线程,网络蜘蛛就可以追踪一个新的URL链接。当然在服务器上所开的线程也不能无限膨胀,需要在服务器的正常运转和快速收集页面之间找到一个平衡点。
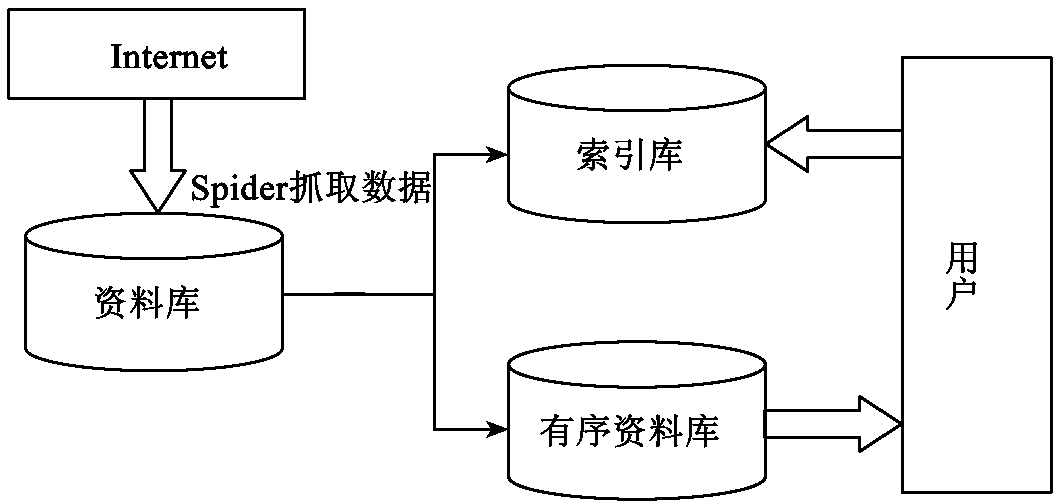
图6-1 网络蜘蛛在搜索引擎中的位置
6.1.3 网络爬虫搜索策略
目前,网络有几个主要特点使得我们搜索数据非常困难。
(1)超大数据容量;
(2)数据更新迅速;
(3)动态页面生成。
由于网络数据容量巨大,网络爬虫在有限的时间内只能下载所浏览过的页面的一部分。这使得网络爬虫必须采取有优先次序的下载方式。由于网络数据更新十分迅速,网络爬虫目前正在下载的某一网站的最新数据,很可能已经有更新的数据添加到此网站,或者这个网页已经更新或者被删去。
服务器端软件生成新页面的数量多,网络爬虫很难避免检索重复的内容。在近似无穷多的HTTP GET(基于URL的)参数组合中,只有很少一部分能返回唯一的内容。例如,一个简单的在线相册可能由HTTP GET参数在URL里指定给用户提供3种选择。如果有四种方式分类这些图像,3种缩略图选择,2种文件格式和一种取消用户提供的内容的选择,相同的内容集可能被48种不同的URL链接到,而这些链接可能都链到这一网站。
网络爬虫在抓取网页时,有两种最基本的搜索策略:深度优先搜索策略和广度优先搜索策略。为了更好地解释网络爬虫的搜索策略,我们把互联网看作一个有向图,将每个网页看作图的节点,将页面中的超链接看作图的有向边,这样,网络爬虫就仿佛是使用有向图遍历法对网页进行遍历(见图6-2)。
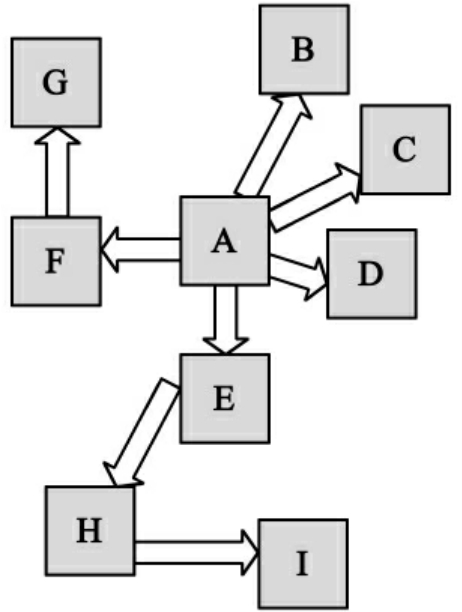
图6-2 遍历图
6.1.3.1 深度优先搜索策略
深度优先搜索是一种早期的网络爬虫使用较多的搜索策略,是指网络爬虫从起始页开始,一个链接接一个链接地跟踪下去,处理完一条线路之后再转入下一个起始页,继续跟踪链接。当不再有可选的超链时,说明搜索已经结束。例如,在上面的图中,A为起始网页,然后搜索到A的下一个链接F,然后蜘蛛继续搜索F的下一个链接G,直到G没有下一链接;蜘蛛转到A的下一个链接E,然后是H和I;到达I之后没有链接了,蜘蛛转到A的其他链接继续搜索BCD,最后完成图的遍历。这种方法的优点是网络蜘蛛在设计的时候比较容易,而且能遍历一个Web站点或深层嵌套的文档集合;缺点是因为Web结构相当深,有可能造成一旦进去,再也出不来的情况发生。
6.1.3.2 广度优先搜索策略
广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。例如,在图6-2中A为起始网页,然后蜘蛛遍历A的所有下层链接BCDEF;然后搜索这一层网页的所有下层链接作为下一次的抓取对象,这样下去,直到完成所有层的抓取。这也是搜索引擎最常用的方式,因为这个方法可以让网络蜘蛛并行处理,既提高了抓取速度,也保证了对浅层的首先处理。当遇到一个无穷尽的深层分支时,不会导致陷进WWW中的深层文档中出不来的情况发生。广度优先搜索策略还有一个优点,即它能在两个HTML文件之间找到最短路径。广度优先搜索策略通常是实现Crawler的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是如果要遍历一个指定的站点或者深层嵌套的HTML文件集,用广度优先搜索策略则需要花费比较长的时间才能到达深层的HTML文件。
除了以上两种最基本的搜索策略,现在的主流搜索引擎大多根据链接价值评价的不同方法,采用了基于回报价值的搜索策略。而基于回报价值的搜索策略又可分为两大类:基于立即回报的搜索策略和基于未来回报价值的搜索策略。前者评价链接价值的依据主要是在搜索过程中“在线”获得的信息,如已访问页面中的文本信息、链接周围的文本信息和页面之间的结构信息等,它又可分为基于内容评价的搜索策略和基于链接结构评价的搜索策略;后者评价链接价值时,主要依据经预先训练而获得的某些“经验信息”,用于对远期回报的预测。
6.1.4 网络爬虫基本结构
在了解网络爬虫的基本原理之后,本节将着重介绍其基本结构。由于在搜索引擎中占有很重要地位,网络爬虫的结构和实现的细节均为各大搜索引擎的商业秘密,我们参照WikiPedia中关于网络爬虫的解释和整体架构图(见图6-3),将网络爬虫程序分为:调度器、URL管理器、多线程下载器、URL提取器等。
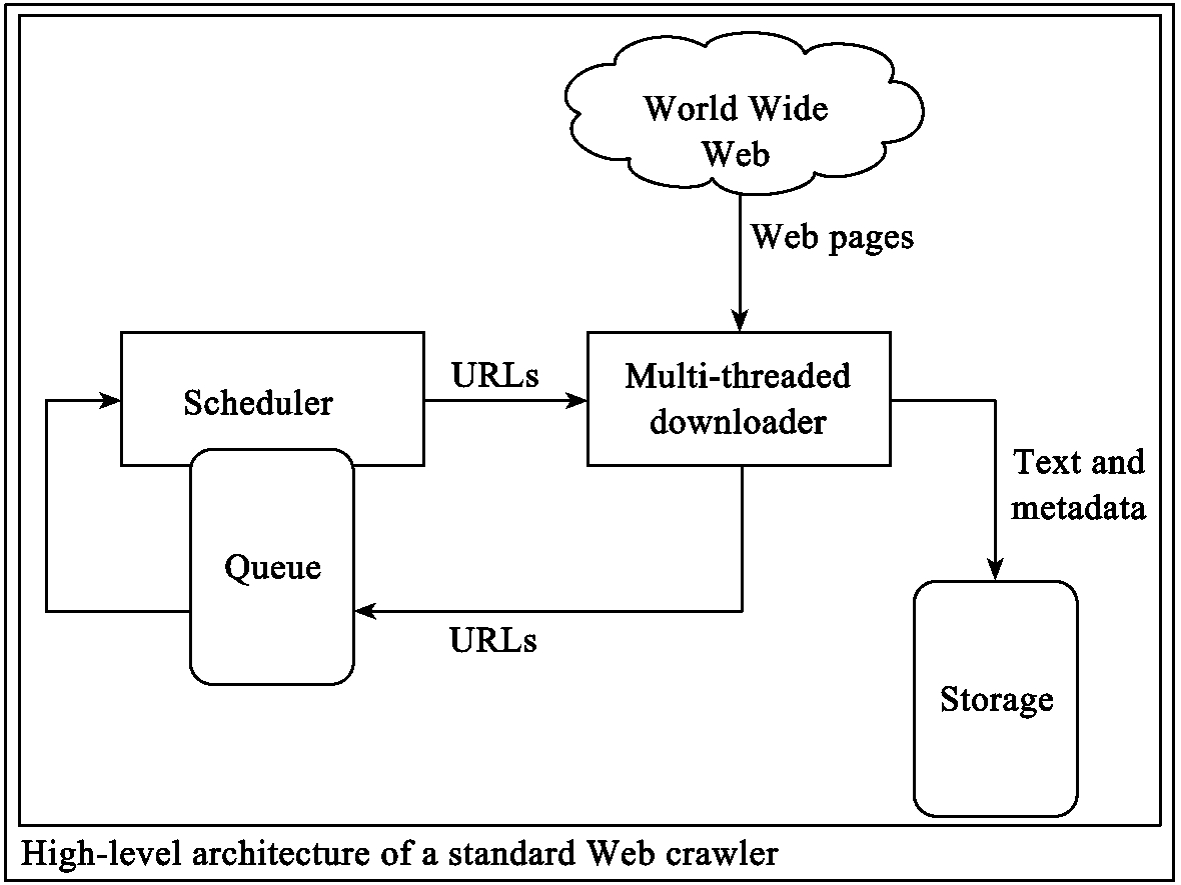
图6-3 网络蜘蛛程序的基本框架结构
其中调度器负责整个网络蜘蛛的管理,是程序的中枢,包括链接管理器的管理、多线程的管理、链接提取器的管理等。
链接管理器主要负责URL队列的管理。网络蜘蛛共使用了四个链接队列对所有链接加以管理。分别是:等待队列,即等待被处理的URL队列,链接提取器中提取的URL判断未被访问之后被加入这个队列;处理队列,即正在被处理的URL列表队列;完成队列,URL被正常处理后,被移送到完成队列;错误队列,处理错误的URL将被放入该队列。同一时间一个URL只能在一个队列中,这也被称为URL的状态。
多线程下载器和链接提取器主要负责网页的下载和解析,两者关联十分紧密。下载器下载了网页文件之后,便要对其进行链接提取,链接的形式主要分为文字链接和图片热区链接,可以用相关的HTML解析器完成,亦可自己构建规则表达式匹配。
通过对网络蜘蛛程序的分析,发现其瓶颈在于发送请求和接受网页的网络传输过程的等待时间,可以使用多线程来提高效率,消除瓶颈。多线程在优化程序的性能时,也带来了另外的线程同步和多线程管理的问题,因此网络蜘蛛还需要设立多线程管理器,负责多个线程的整体监控和调度。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












