



第二节 统计整理
当我们通过统计调查,搜集到大量统计资料以后,如果不加整理,这些资料都是零星的、分散的,只反映事物的表面现象和外部联系。因此,必须根据一定研究目的,对这些数据资料加以科学的综合、加工,使之系统化,变为能反映总体特征的综合数字资料。
统计资料整理的主要步骤是对调查得来的数据资料进行审核、分组、汇总并编制统计表。其中统计分组是统计整理的一个重要内容,统计分组的方法或分类的方法是否科学,是否能反映现象的客观过程,是统计分组的中心问题。
一、统计分组的概念
统计活动的全过程是在一定的分组体系下运用统计指标体系进行的,所以,统计分组在统计活动中具有十分重要的地位。
统计分组就是根据统计研究的需要,将统计总体按照一定的分组标志区分为若干部分的一种统计方法。总体的各个组成部分称为“组”。
根据统计总体的特征,一方面,组成总体的各单位,在某些标志上具有相同的性质;另一方面,在其他一些标志上又具有某些差异。通过对有差异的标志分组把总体内不同性质的单位分开,使性质相同的单位归在一个组内,这样有助于从数量方面揭示现象内部的联系,从而更深入说明总体的特征和规律性。例如,我们把社会产品区分为生产资料和消费资料两大类,以研究两大部类的比例关系和规律;将具有我国国籍的人口按年龄或性别进行分组以研究我国人口状况和发展趋势等。
统计分组的关键在于选择分组标志和划定各组界限。分组标志是统计分组的依据,如果选择不当就不能获得正确的结论,达不到统计研究的目的。而在分组标志的差异范围内各组界限划分不当,必将混淆各组的性质差别,达不到组内同质、组间差异的分组要求。
二、频数分布
将总体按某种标志分组,并将总体中的所有单位按组归类整理,形成总体中各个单位数在各组间的分布,称为频数分布。各个组的单位数叫频数(Frequency),各组频数与总频数之比叫比率,又称频率。将各组按大小顺序排列起来,并列出各组在该标志上的总体单位数,所形成的数列称为频数分布数列,简称分布数列。通过频数分布可以反映总体中所有单位在各组间的分布状态和特征,研究这种分布特征是统计分析的一项重要内容。
根据分组标志特征的不同,分布数列可以分为品质数列与变量数列。
(一)品质数列
按品质标志分组形成的分布数列称为品质数列。如表2-1所示。
表2-1 我国内地人口的性别分布(2000年11月1日0时)

资料来源:第五次全国人口普查公报(第1号)。
一般来说,由于品质标志对事物性质的差异表现得比较明确,总体中各组界限划分比较容易,因而品质分布数列一般也较稳定,通常均能准确地反映总体的分布特征。但有些按品质标志划分各组界限时会碰到困难,因为存在着两种性质的变异间的过渡形态,使组限不易划分,如生产按部门分,劳动力按职业分,产品按种类分。为了保证统计资料在搜集和汇总上的统一,对重要的品质标志分组,往往编有标准的分类目录,以统一全国的分组口径。例如,《工业部门分类目录》、《工业产品目录》等。
(二)变量数列
按数量标志分组形成的分布数列称为变量数列。如表2-2所示。
表2-2 某街道住户人口数分布

对于变量数列来讲,因为事物性质的差异表现得不太明确,决定事物性质的数量界限往往因人的主观意志而定。因此,按同一数量标志分组时,有出现多种分布数列的可能。如何分组才能使变量数列准确地反映总体分布的特征,这是编制变量数列的核心问题。
变量数列可分为单项变量数列与组距变量数列两种。
单项变量数列是按每个变量值分别列组而编制的变量数列,如表2-2所示。对于离散型变量而且变量值又比较少的情况,一般适宜采用单项变量数列。
对于连续型变量(如表2-3中的资料)或者数值比较多的离散型变量,则适宜采用组距数列。
表2-3 某车间工人生产定额完成情况 单位:%

续表

组距变量数列是用表示一定变动范围或表示一定距离的两个变量值代表一个组,由这些组及其所含的单位数组成的变量数列,表2-4即为根据表2-3的资料编制的组距变量数列。
表2-4 某车间工人生产定额完成情况分布

在组距数列中,每组的最大值为组的上限(Upper limit),最小值为组的下限(Lower limit),上限和下限之间的距离称为组距(Class width),上限与下限之间的中点数值称为组中值(Class midpoint),即:组距=上限-下限,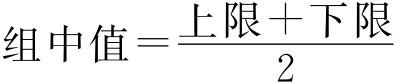 。
。
例如,表2-4中第一组上限为90%,下限为80%,组距=90%-80%=10%,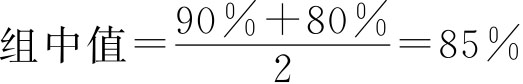 。对于组距数列,需要做以下几点说明:
。对于组距数列,需要做以下几点说明:
1.组距变量数列通常有等距和不等距两种。等距数列即每一组的组距是相等的,上例即是等距数列。组距不相等的叫不等距数列。在实际进行分组时采用哪一种数列,取决于现象的性质和研究的目的。
等组距的优点是便于以后的计算和分析,因此,编制组距数列时,应尽量采用等距分组。对于一部分现象由于性质差异的变化不均衡,很难用等组距的办法近似地区分性质不同的组,则需要采用不等距分组。例如,对儿童年龄的分组,必须注意到儿童不同年龄生理变化的特点,分为:1岁以下,1~3岁,3~7岁,7~15岁等组。又比如,钢铁工业中,高炉按有效容积(立方米)的不等距分组:100立方米以下,100~200立方米,200~400立方米,400~800立方米,800~1600立方米,1600立方米以上。
2.离散型变量和连续型变量组限的表示方法不同。离散型变量可以一一列举,而且相邻两个数值之间没有中间数值,因此,各组的上下限都可以用确定的数表示,且相邻两组的上下限可以不重合。例如,企业按职工人数分组可以分为以下各组:50~99人,100~149人,150~199人,200~249人。连续型变量不可能一一列举,因此,相邻组的上限和下限不可能用两个确定的数值来表示,在这种情况下,通常是以一个数值作为相邻两组的上限和下限,例如,表2-4某车间工人生产定额完成程度分组中,90%既是第一组的上限又是第二组的下限。在这种分组情况下,为了防止分组发生混乱,习惯上规定各组一般均只包括本组下限变量值,而不包括本组上限变量值,即“上组限不在内”原则,如上例定额完成程度为90%的工人列入第二组。
3.组距数列中的各个组可以是开口组,也可以是闭口组。组距的上限、下限都齐全的叫闭口组,如表2-4所示。有上限缺下限,或有下限缺上限的叫开口组,例如,表2-4的第一组若表示为90%以下,则为缺下限开口组;第五组若表示为120%以上,则为缺上限开口组。开口组的组中值一般以邻近一组组距为准计算,其计算公式为:

(三)频数分布图
为了更直观地反映变量数列中总体单位在各组的分布情况,可以根据频数分布表绘制频数分布图。
1.直方图。直方图是以横轴表示各组组限,纵轴表示频数或比率,依据各组组距的宽度与频数的高度而绘制的频数分布图。根据表2-4的资料可绘制直方图,如图2-1所示。

图2-1 某车间工人生产定额完成程度频数分布图
2.曲线图。如果以各组标志值中点位置作为该组标志的代表值,然后用折线将各组频数连接起来,就形成了频数分布的折线图。当变量值非常多,变量数列的组数无限增多时,折线图就会越来越光滑,逐渐接近于一条光滑的曲线,这种曲线即频数分布曲线。
各种不同性质的客观现象都有着特殊的频数分布曲线,但主要有钟形、U形和J形三种类型。
钟形曲线的特点是“两头小,中间大”,即靠近中间的变量值分布的频数多,靠近两端的变量值分布的频数少。钟形分布有对称与非对称之分,对称分布以分布频数最多的中间变量值为中心,两侧呈对称分布,如图2-2(a)所示。许多客观现象总体的分布都趋于对称分布,如零件公差的分布、商品市场价格的分布等。非对称分布有不同方向的偏度,如图2-2(b)、(c)所示。对非对称分布的偏斜度的测定,可参阅本书第三章的有关内容。

图2-2 对称与非对称分布
U形曲线的特点是“两头大,中间小”,即靠近中间的变量值分布的频数少,靠近两端的变量值分布的频数多。如人口死亡率分布,由于婴幼儿和老年人死亡率均高,而中青年人死亡率最低,因而按年龄分组的人口死亡率表现为U形分布,如图2-3所示。
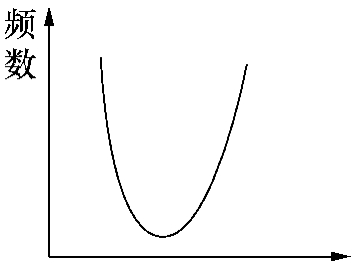
图2-3 U形分布
J形分布分正J形与反J形两种类型,如图2-4(a)、(b)所示。正J形分布是频数随着变量值的增大而增多,如投资额按利润率大小分布。反J形分布是频数随着变量值的增大而减少,如经济学中需求量按价格高低的分布(即需求曲线)。
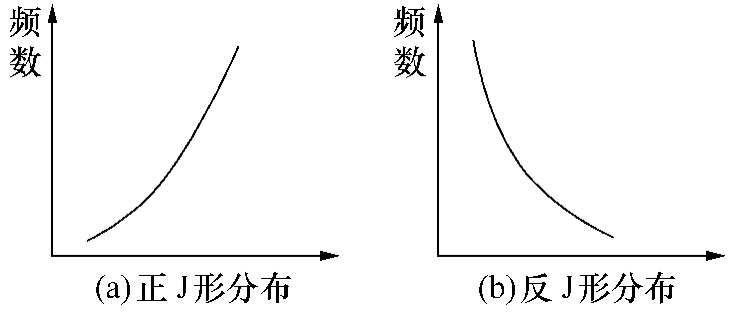
图2-4 J形分布
(四)累计频数分布
上述的频数分布表仅表示每一组的频数为多少,如表2-4所示,生产定额完成程度为90%~100%的工人数为6人。但如果要知道定额完成程度为100%以下(或以上)的工人数为多少,占全体的比例是多少,就要计算累计频数(Cumulative frequencies)或累计比率(Cumulative ratio)。计算累计频数或比率的方法有两种,一种是向上累计,另一种是向下累计。向上累计频数及比率是将各组频数和比率由变量值低的组向变量值高的组累计,各累计数的意义是各组上限以下的累计频数或累计比率。向下累计频数及比率是将各组频数和比率由变量值高的组向变量值低的组累计,各累计数的意义是各组下限以上的累计频数或比率(见表2-5)。
表2-5 工人生产定额完成程度累计频数分布表
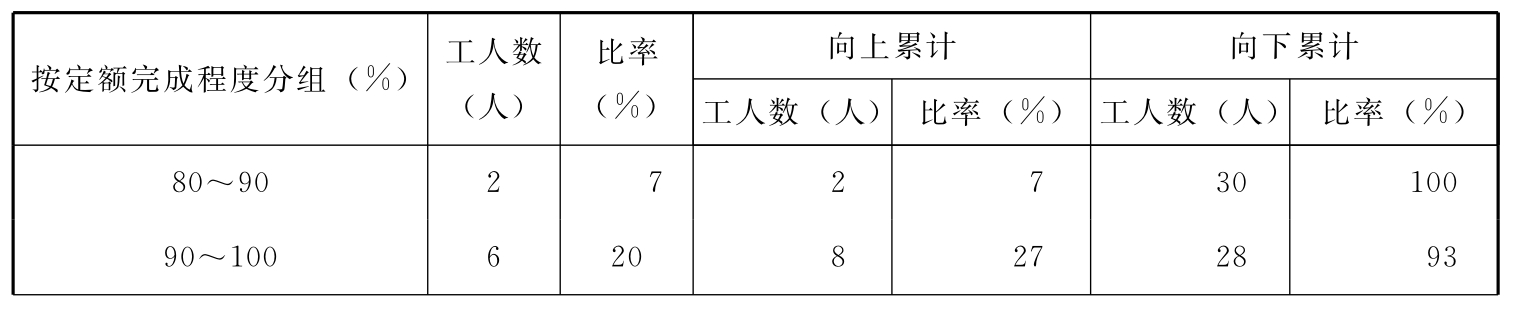
续表

对于累计的频数除了列表表示以外,还可以用图表示。图示累计频数形成的曲线称累计曲线图。洛伦茨曲线是一种具有特殊作用的累计分布曲线,它可以用来表示一个国家或一个地区收入分配是否平等的程度。其计算方法是:计算出各组人数的百分数及其所得收入的百分数。若有一组人数百分数甚少,而所占收入百分数甚高,其余各组人数的百分数甚大,而占有收入的百分数甚低,则可知所得分配是不平等的。表2-6是我国1984年职工收入分布表。
表2-6 1984年我国职工收入分布表

从表2-6可看出收入分配的状况。其中收入最高的户数占总人数的5%,而收入额则达到9.28%。收入最低的户数占总人数的2.21%,收入额仅占0.98%。这种状况,用累计百分数表示,则表现得更清楚(见表2-7)。
表2-7 职工收入累计分布

为了说明收入分配的不平等状态,可将上述实际分配状态与绝对平等状态和绝对不平等状态相比较,并用曲线表示出来。所谓绝对平等状态,是假定居民的收入都完全一样,如表2-8所示。
表2-8 职工收入绝对平等累计分布 单位:%

所谓分配的绝对不平等状态,则是假定居民中99%的人收入为零,最后1%的人占有全部收入,如表2-9所示。
表2-9 职工收入绝对不平等累计分布 单位:%

续表

当然,这两种情况在任何国家和地区都是不存在的,实际的分配介于两者之间。把以上三种情况画成曲线图以进行比较,当实际分配曲线与绝对平等线之间差距越小,表明实际的不平等越小,差距越大,表明实际的不平等越大,如图2-5所示。

图2-5 居民收入分配的洛伦茨曲线
从图2-5中可知,不平等面积越大,表示不平等的程度越大,不平等的面积越小,表示不平等的程度越小。
以不平等面积与三角形面积的比值(G)来反映收入分配不平等的指标称为基尼系数。基尼系数是意大利经济学家基尼(Gini)为分析收入和财富分配的不平等性,在洛伦茨曲线的基础上于1912年提出。利用基尼系数判断收入分配平等性的一般标准为:G<0.2,高度平等;0.2≤G<0.3,相对平等;0.3≤G<0.4,差距相对合理;G≥0.4,差距偏大。
三、茎叶图
将搜集来的数据资料按照分组标志进行分组,再将分组数据绘制成直方图、折线图或曲线图来观察数据的数量规律性,这种统计整理方法的局限性表现为整理后就失去了原始的数据信息。为解决上述问题,20世纪70年代末期出现了探索性数据分析的统计新领域,茎叶图(Stem-and-leaf display)是探索性数据分析中比较简单的一种。图2-6是根据表2-3的资料绘制的茎叶图。

图2-6 某车间工人生产定额完成情况的茎叶图
茎叶图将分组标志视为树茎,将观察值视为树叶,每个树叶按照分组要求长在应长的树茎上,各树茎上的叶子数是各组的频数。在图2-6中,我们将定额完成程度的十位和百位数作为树茎,如第一个树茎8表示十位数为8,第三个树茎10表示十位数为0、百位数为1,分属不同树茎的观察值,个位数从0~9都应长在相应树茎上。将树茎确定并画好后,依次将每个工人生产定额完成程度的个位数写到对应的树茎上,即是一个茎叶图。
与编制组距数列再绘制直方图比较,茎叶图将分组与绘图两步一次完成,并且保留了数据的原始信息。在对连续型数据分组时,利用茎叶图还可以避免重复分组问题,因而不必规定“上组限不在内”原则。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











