



第二节 随机和非随机抽样
随机抽样的基本形式就是简单随机抽样,研究对象的总体中每一个单位都有入选的几率。如果从研究总体中抽取的单位不再返回总体,就叫做非重复抽样方法。反之,如果将从总体中抽取的单位重新返回总体中,即是重复随机抽样,即首次被选中的单位有第二次被选中的几率,在较复杂的研究中,常采用重复随机抽样方法。
随机抽样通常以随机抽样表(乱数表)来实施抽样。例如,某研究机构要研究某报纸360天中10天的头版头条新闻内容,就必须将360天逐天编号,然后完全随机地从中选取10天。选取的方法是首先任意选一天,然后在乱数表中找出相应的数字,并在该数字的任一方向选取9个数字,即得到了所需的样本。
一、简单随机抽样
简单随机抽样应用并不广泛,只作一般调查之用,如随机电话号码,方法是用乱数表选取4位数或5位数,然后加上地区号码。随机电话号码抽样应考虑抽的数量足够多,因为在实际调查时常会出现空号或电话无人接听。
简单随机抽样虽然不常使用,但常被研究者提出来研究,这是因为简单随机抽样的数学性质比较简单,很多统计理论和技术都是假定元素,且是用简单随机抽样的方法来选取的。同时,所有的概率选样都可以看作是对简单随机抽样的限制,它限制了总体元素的一些组合,而简单随机抽样允许所有可能的组合。此外,简单随机抽样的计算公式经常用于复杂抽样办法得到的数据。
简单随机抽样的优点也非常明显:研究人员不需对研究总体作过多的调查;可以统计推断外在的效度;容易找到一组具有代表性的对象;排除了分类误差。
二、系统随机抽样
系统随机抽样与简单随机抽样很相似。系统误差的抽样方法是在研究总体每隔一个固定的区间便抽取一个单位。例如,要在有100个单位的总体中抽10个单位,每个单位的被抽几率为10%。研究人员首先随机抽取第一个单位,然后按每10个单位为一间隔,如果任意抽取的单位是15,那么所抽取样本单位就是15、25、35、45、55、65、75、85、95、5。
在大众传播学的定量研究中,系统随机抽样法常被使用,因为与简单随机抽样相比,系统随机抽样省时省力,样本的代表性也比简单随机抽样好。
系统随机抽样的最大缺点是容易遇到周期性误差,就是所选的单位在排列和顺序上的偏差。例如在大众传播媒介研究中,要研究某电视台的电视剧频道,假如新抽取的单位间隔为7的话,可能抽到的都是周末、周日或周二,这样就没有代表性。再如,假定抽一年的36天的某报纸为研究样本,抽样结果可能出现抽的是每月的1、10、20,如果抽的单位中有1号,那么全年中会有1月1日、5月1日、6月1日、7月1日、8月1日、10月1日、12月1日等若干个节日。研究一年的报纸抽的全是节假日作为研究单位就很难有代表性。
三、分层随机抽样
分层随机抽样抽取的样本都来自研究总体,就是说抽取的单位来自具有相似性特征的总体中,具有同质性。
分层随机抽样方法有两种形式,一种是比例分层抽样法,是以研究总体中所占比例为分层的根据。例如在人群中,18—24岁的成人占研究总体中的30%,那么在所抽取的样本中,该年龄层也应占30%。另一种是非比例分层抽样法。例如要研究新闻媒介实行舆论监督的情况,在一项调查中,突出的是具有认知能力的人,即22—60岁这一年龄段的比例最大。
分层随机抽样法的优点是十分明显的,那就是能够表现相关变量的代表性,可以同其他研究总体相比较,样本选自同质群体,抽样误差少。但分层随机抽样也存在一定的缺陷,选择前必须详细了解研究总体的情况,抽样成本较高,分层标准很难掌握,中选几率较低。
四、集体随机抽样
集体随机抽样法是将研究总体分成若干区域,然后再从若干区域中抽取一部分区域作为样本。集体随机抽样法容易产生两种误差,一种是选定原始团体时的误差,另一种是自若干区域中取部分称作为样本的误差。例如,抽取的某区域正好是经济水平和社会地位都很低的阶层,或者都是经济收入较高、社会地位高的白领阶层,这两个阶层都不能代表研究总体,也就是说研究结果的偏差大,与实际情况不符。为了减少这种误差,较容易的办法是将区域分得很小,降低每一区域中个体的数量,又能选取更多的区域。
在集体随机抽样法中,多段抽样法常被使用。多段抽样法就是将研究总体分成若干阶段。例如,一项全国性的研究,首先抽取较大的区域,如省、地、州、市,然后从地、州、市中再抽出县或区,再从区中选出路、道,然后再随机抽出某号楼某家庭。以家庭作为样本时,还要确定哪一位家庭成员作为样本,这就要用随机数表来决定。调查过程如图9-1所示。
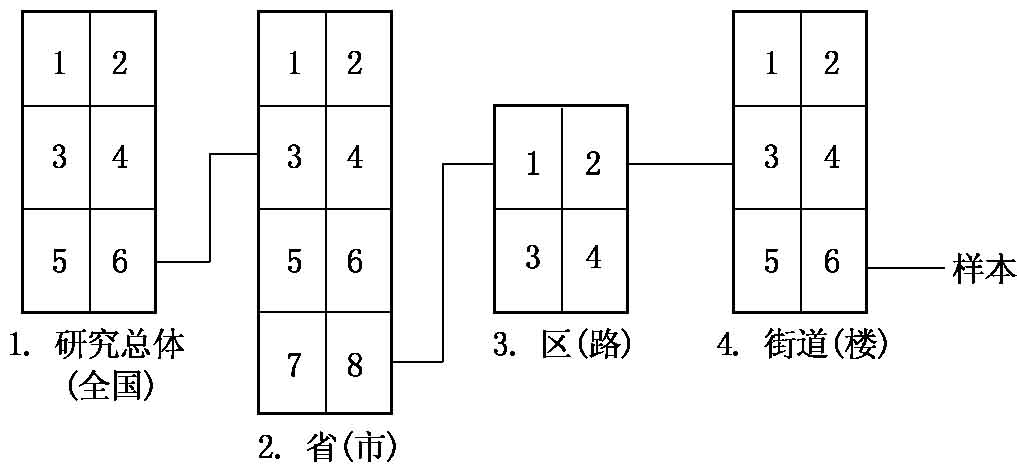
图9-1 多段抽样调查过程图
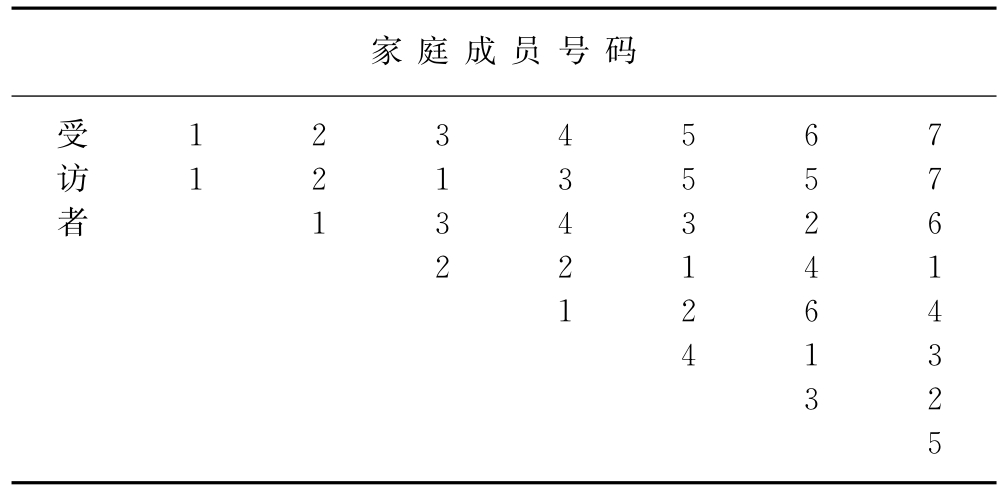
摘自《Mass Media Research—An Introduction》
图9-2 多段抽样选择受访者的模型
在选择家庭成员时,调查人员询问听电话的人,如“你家中18岁以上的成员有几位”,如果对方回答是3位,那么就选择3号家庭成员,即从年龄最长者往下数第3位。若下一位被调查对象同上一个被调查对象的情况相同,调查者则从家庭成员号码的“3”下选一个号码。
五、非随机抽样
非随机抽样方法在大众传播学定量研究中经常被采用,特别是现成样本、自愿样本和立意样本等形式已经被普遍地使用在传播媒介中。
现成样本也叫便利样本,就是对容易得到的被调查对象进行调查,能够取得有用的资料。但现成样本的信度低。
现成样本在一些研究领域中有争论,一部分研究者认为现成样本不论得到什么样的结果,都是无价值的,不能代替母体。另一些研究者认为,如某一特征或现象普遍存在的话,它应该存在于任何样本中。但无论如何,现成样本还是有用的,如要确定问卷的科学性及研究程序和研究方法的可行性,可先行试调查。
自愿样本并非按照数学原则选出,也是一种非随机样本。由于这些被调查对象,迥异于非自愿者,因此误差的出现是不足为怪的。但自愿者常常是教育水准较高、职业地位较高的社会成员,是能代表社会中较高阶层的特征的。
立意抽样是针对具有某种特性或质量的对象进行抽样,并常常被用于大众传播的广告研究,如让一些消费者对同一用品的新旧产品和不同厂家产品进行比较等。
配额抽样是同立意抽样类似的方法,按照特定和已知的比例选择对象。
偶然性抽样也是一种非随机抽样方法,它按照表面特征或某种特征要求偶然选择对象,它是研究者的主观行为和意志的研究,误差已在考虑之中。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









