



第一节 非参数统计
统计基本分为两大类,即参数统计(parametric statistics)和非参数统计(nonparametric statistics)。过去有些学者认为,这两大类统计有几点不同:
第一,非参数统计仅适用于列名的(nominal)和次序的(ordinal)数据,而参数统计如适用于等距(interval)和等比(ratio)的数据;
第二,非参数统计结果不能推广到总体,只能利用参数统计;
第三,参数统计假设数据为正态分布,非参数统计没有这种假设,因此被称为“任意分布”(distribution-free)。
但是罗杰·温默认为,第一、第二区别并不存在,因为大多数大众传播研究专家认为参数统计和非参数统计都可以推广到总体。近几年许多专家就是这样做的。
事实上,非参数统计分析方法有很多的优点,例如,这种分析不要实现知道总体的分布情况,不要事先对样本分布作假设,只是对调查的样本进行分析,统计过程较为简单,是大众传播定量研究中实用简易的操作方法。
非参数统计分析方法缺点也是非常明显的,就是度量层次不高,检验分析的效力和效度比参数统计检验要低,解释与分析能力较差。
非参数统计包括内容很多,在传播学研究中,最常用的是以下四种。
一、卡方拟合优度分析
将某一现象的观测频率和期望或假设频率相比是大众传播研究人员经常采用的,目的是判断这种频率的变化是否真正有意义,即卡方统计(chi-square statistics),并通过卡方拟合优度检验实现。
卡方就是一个表示期望频率和观测频率关系的值,它通过下列公式取均值得到:
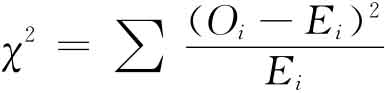
公式中,Oi为观测频率,Ei为期望频率。
这个式子说明每一期望频率之差先平方再除以期望频率,商的和就是那些频率的卡方。
知道了卡方值之后,就可以进行拟合优度检验,以确定这个值是否代表频率的显著差异。要做到这一点,就要知道两个值:第一个是研究人员预先定好的或然率尺度,第二个是自由度尺度(df=degrees of freedom),是某一特定检验中自变量的个数,它的值是可变的。假如某一项检验有三个未知量(x,y和z),x+y+z=10,就有两种自由度:如果预定好某一变量的值,三个变量值中的其余两个可取任何不影响总和的值。就是说,如x=z,y=4,那么z肯定为3。在拟合优度的检验中,用k-1表示自由度,其中k是组数。
卡方拟合优度检验能在比较广泛的领域中测量变化量,如分析研究受众对超时广告的感觉,影视节目安排的变动,评估传播效果等,甚至用来研究“把关人”。
当然,卡方拟合优度检验也不是万能的,只在某些研究领域。因为卡方拟合优度检验是一种参数统计方法,变量必须是名目的和次序的来测量,组也必须独立,且每组的每一测量值必须与所有其他测量无关。同时,卡方公布对小样本则会得到有效结果。为了解决这个问题,建议在研究中每组至少测五个值,并且使单元的应该期望频率为5的不少于20%,而期望频率为0的单元不能出现。
二、列联表分析
列联表分析法基本上就是拟合优度检验的扩展,不同点在于列联表分析法可以同时检验两个或更多变量。列联表分析法中,自由度尺度表示确定统计有效性,表示方法:(R—1)(C—1),R是行数,C是列数。
三、两个样本之差的非参数分析
1.R检验
R检验(word-wolfwitz Runs Test)是通过从对两个总体中随机抽出的两个独立样本的某种趋势(平均数)和离散(离差)趋势的检验,来分析这两个总体的分布是否有差异。R检验可分为小样本R检验和大样本R检验。
小样本R检验。当n1≤20和n2≤20时的检验就是小样本检验。它的检验步骤分为:确定研究条件,如总体分布,抽样类型,量度层次,提出假设,计算抽样分布,确定水平和否定域,统计,获得结果。
大样本R检验。n1>20和n2>20时的检验就是大样本检验,它的步骤同小样本检验的步骤相同。
2.U检验
U检验(Man Witney U Test)作为一种非参数分析方法,其假设条件与R检验完全相同,即两总体皆为正态连续分布的相同总体,量度层次为定序尺度。但是,U检验比R检验更容易做到,且信度高。特别是当两个总体的差异性主要表现在集中趋势程度上,并且离散不太显著的情况下,U检验比R检验更具效力。
U检验也分为小样本检验和大样本检验,其步骤与R检验基本相同。
3.配对样本的非参数检验
主要是柯-斯检验(Kolmogorov-Smirmov Test),它常被一些研究人员用来代替卡方拟合优度检验,甚至被认为是比卡方检验更好的方法,特别是它不规定每一单元期望频率的最小值。如果两个配对的独立随机n1和n2都是分别从两个相同的总体中抽出的,那么,可以认为这两个样本的累计频率分布基本相似。柯-斯检验的统计量,就是这两个样本累计频率分布中的那个最大的差值DK,如果差值最大,则说明两总体分布相差很大,如果DK差值小,并且小于DK在否定域的值,DK就说明两总体分布无差异。
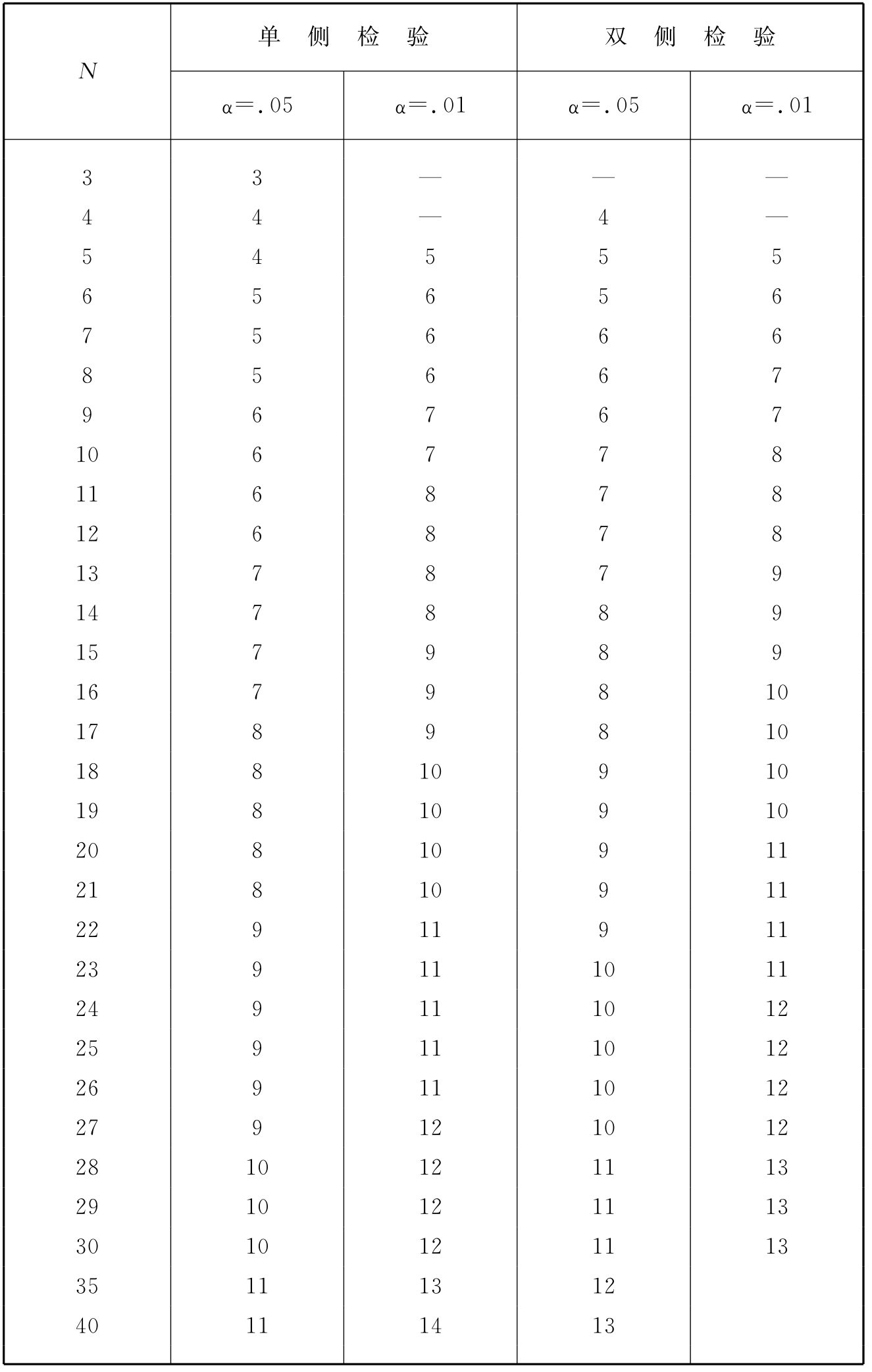
柯-斯检验的步骤类似R检验,一定显著水平的D可查表12-1和表12-2。
表12-1 柯-斯单样本检验D的临界值
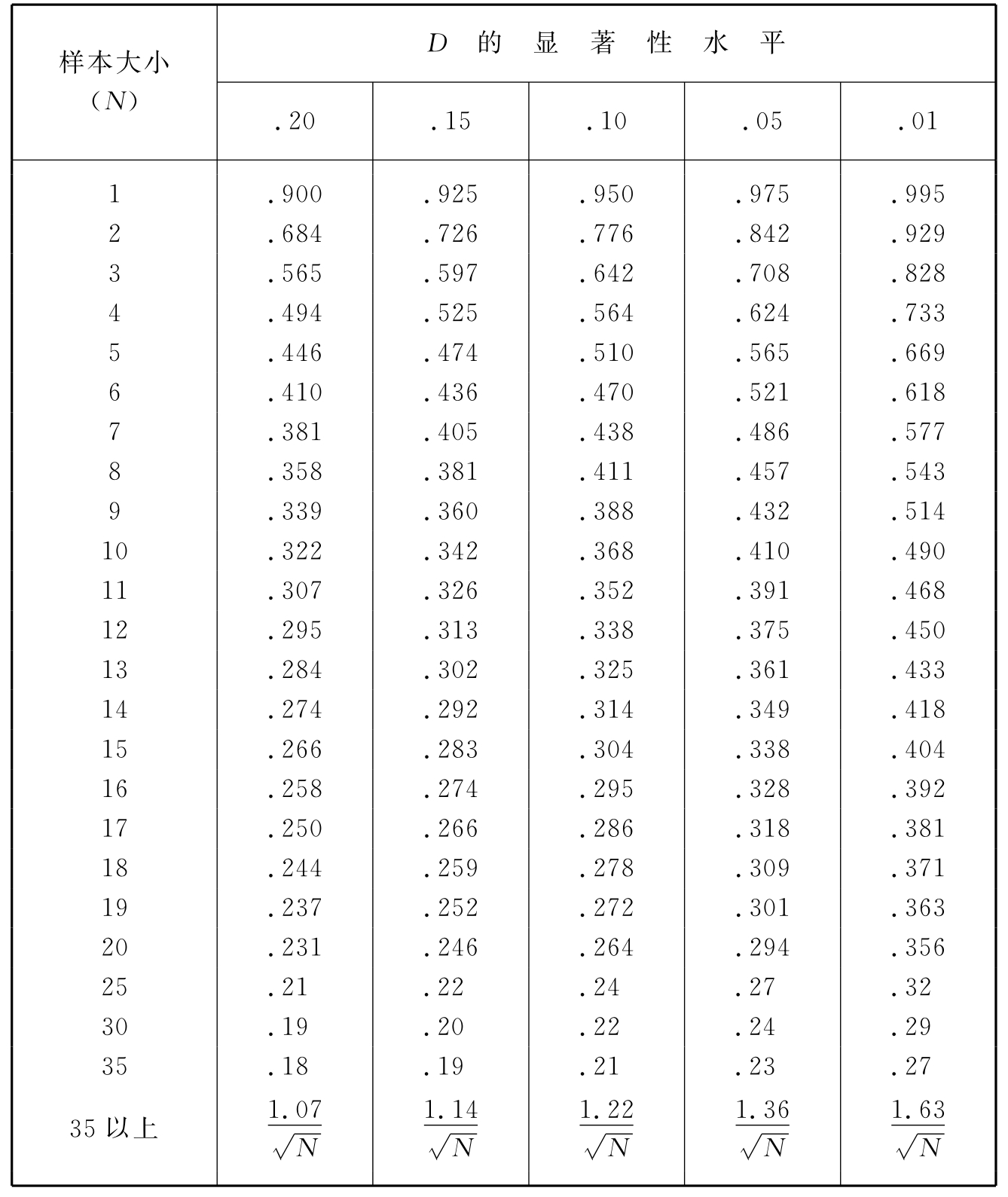
表12-2 柯-斯两样本检验KD的临界值(小样本)
四、参数统计
参数统计方法是处理复杂数据的方法,这些方法都是假设数据呈正态分布。在大众传播学研究中最常用的参数统计方法是t检验。
1.t检验
在一些大众传播研究中,常将实验对象分为两组进行实验,一组是经过某种形式的处理,另一组作为控制。实验后进行比较,以确定两组之间是否存在显著差异。t检验是比较每一组的平均值,以了解实验对检验结果有无影响。
t检验也有许多不同的方法,选择何种检验方法可根据检验的是独立组成相关组,已知总体均值或未知总体的均值进行变换。
t检验假设从中抽取样本的母体变量是正态分布,还假设数据具有变异数同性,就是说数据偏离平均值程度相同。t检验的基本公式比较简单,公式的分子是样本平均与假定的总平均值之差,再除以平均值标准误差的估值(Sm):
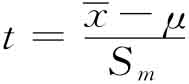
式中,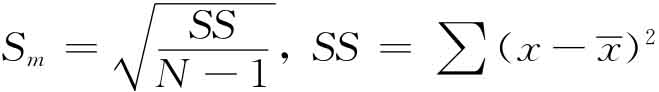
t检验是比较常用的一种统计方法,是检验独立组成或平均值的形式,这种方法用于研究两组独立组的差异。用于检验独立组的t检验公式为:
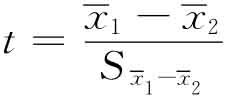
其中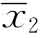 是第二组的平均值
是第二组的平均值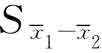 是两组的标准误差。标准误差是t检验公式的重要部分,计算公式是:
是两组的标准误差。标准误差是t检验公式的重要部分,计算公式是:
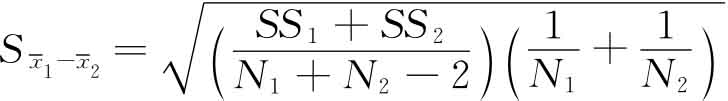
式中,SS1是第一组的平方和,SS2是第二组的平方和,N1是第一组的样本范围,N2是第二组的样本范围。
2.变异数分析
变异数分析(analysis of variance)是t检验法的扩展,因为t检验法仅适用于一个变量比较,而变异数分析法可用来同时研究几个自变量,即因素(factors)。变异数分析法按研究中涉及的因素数目命名;研究一个自变量,叫单向变异数分析;研究两个自变量叫双变异数分析,依此类推。也可以用自变量的尺度对变异数命名。2×2变异数分析表示两个自变量,每个自变量有两级。
变异数分析法在大众传播研究方面被广泛适用,但是因为变异数分析最常用于检验两个或更多组之间的平均值显著差异,并且与变异数差异分析无关,同时变异数分析将系列数据全部变化分解为各自不同的变化源,就是说,它用一个或更多自变量来解释一系列数值变异数的来源,因此人们对变异数分析常有误解。
变异数分析两种变异数——系统变异数和误差变异数。系统变异数可归因于一个已知的因素,这个因素造成它所影响的数值预先增大或减小。数值的误差变异数归因于一个未知因素,它是研究中最难确定、最难控制的因素,所有研究者的主要目标是尽可能消除或者尽可能的控制误差变异。
变异数模式假设:
(1)每一个样本都是常态分布。
(2)每一组变异数相等。
(3)实验对象由母体中随机抽出。
(4)数值为统计独立,即它们与其他变量或数值无相伴关系。
变异数分析法首先选定两个或更多随机样本,这些样本可以从相同的或不同的母体中抽取,每组要进行不同的实验处理,然后进行某种形式的检验,检验得到的数值用来计算变异数比率,即Fee率。
在统计过程中,我们会遇到平方和法,在平方和法中,原始数值或偏差数值平方求和,这样就不必处理负数,只要将所有数据平方就不会影响数据平均值,而平方只是将数据变为一系列更易于分析的数据。
变异数分析法在检验中,要计算组与组之间、组内和总体的平方和。组间和组内平方和要除以相应的自由尺度,得到均方值;组间均方值(msb)和组内均方值(msw)。Fee率的计算公式为
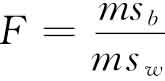
式中,msbdf=K-1,mswdf=N-K,K=组数,N=总样本
数值计算所得Fee率要与F分布表中相应自由度尺度所造成或然率尺度的Fee率比较,如果计算值等于或大于表中查到的值,可以认为变异数分析统计有效。Fee率表与t检验表和x平方表相似,只是Fee率表使用两种不同的自由度尺度,一个对应于Fee率分子,一个对应于分母。
3.双向变异分析
双向变异数分析是研究者在实验中同时检验第二个自变量所用到的。在双向变异分析中,研究者收集数据,像单向变异数分析法时一样排成表,不同的是对应每一实验对象的数值填入表中每一单元,如表12-3所示。
表12-3 双向变异数表
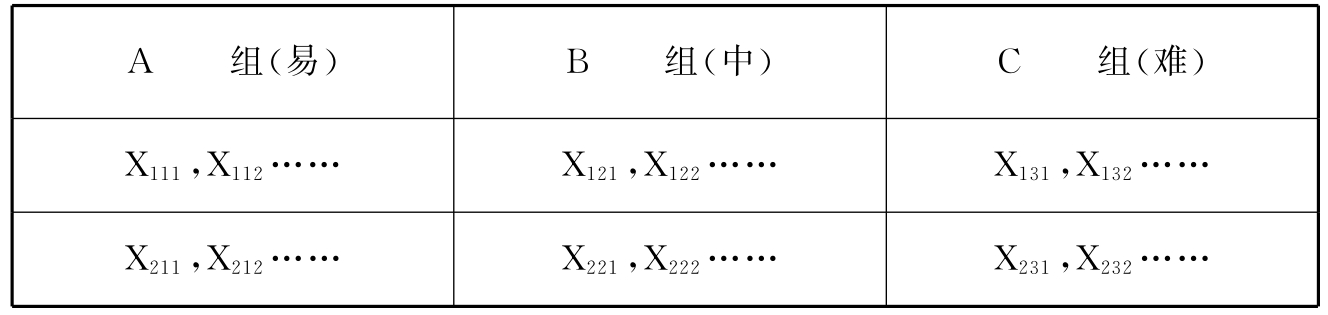
X表示相关测试数值,下角标有这个数值的实验对象(假设的实验对象)。
由于对每一个自变量的研究是同时进行的,所以双向变异数分析节省时间,节省材料,还可以计算两种自变量对因变量的影响:平均效应和互动效应,而单向变异数分析只能计算平均效应。平均效应是自变量对因变量的影响。互动效应是两个或两个以上自变量,对一个因变量的共同作用。
单向变异数分析只计算一个Fee率,双向变异数分析则要计算四个Fee率,每一个都要与F分布表对照以判定是否统计有效(列间、行间、互动、单元内)。列间(平均效应)代表对应于双向变异数分析列中的自变量的检验,行间是另一个平均效应检验,它表明双向变异数分析行间自变量水平的有效性,互动是对研究中的两个自变量之间互动的检验,单元内检验研究的每一单元间的显著差异,确定单独每个组变量之间互动的检验,单元内检验研究的每一单元间的显著差异,确定单独每个组在分析中的作用。双向变异分析不计算总的Fee率,故不用均方值和F列分析量。
4.一般相关统计
研究人员在研究中发现,某些因素常常同另一种情景相联系。例如,某电影院放映《聊斋》时的观众越多,在某大城市,拜佛的人就越多,这两个变量之间就存在一种关系。两个变量,一个变量随另一个变量改变的程度,就是相关测度(measures of correlation),也叫结合测度(measures of association)。如果对同一对象进行两种不同测试,通常用变量x表示一种测度,用变量y表示另一种测度。如上面的例子,可用变量x表示看《聊斋》的测度,用变量y表示烧香拜佛的测度。如图12-1所示。
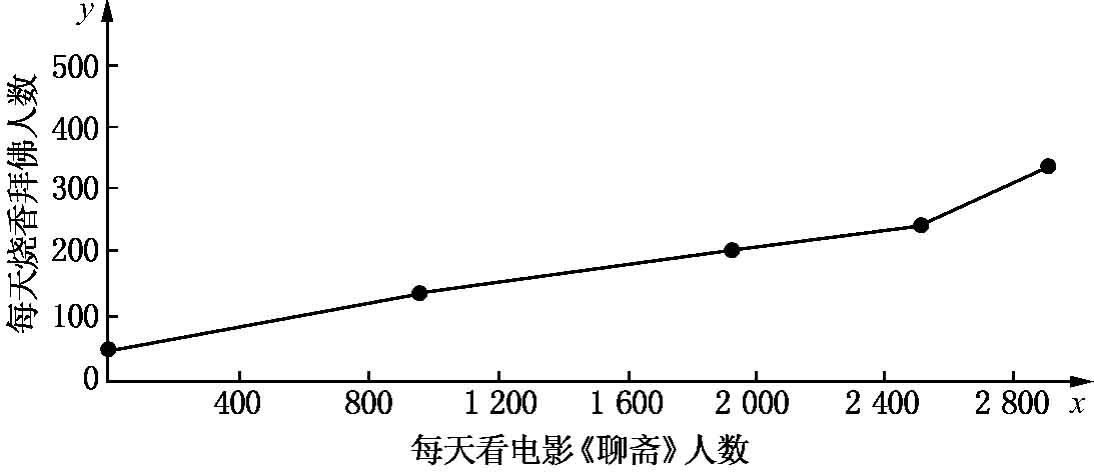
图12-1
图12-1中,变量x是每天看电影《聊斋》的人数,变量y是每天烧香拜佛的人数,变量x同变量y是一起增加的,他们之间有一种正关系。如果变量x同变量y是相反的趋势,如,看电影《聊斋》的人越多,去拜佛烧香的人越少,这就是负相关或负关系,到某一点,变为正关系。这种关系也叫曲线关系。如果一个变量取值较大但没有引起另一个变量的大值或小值,说明这两个变数不相关。
研究人员可用多种办法来研究或检测两个变量之间的关系,如皮尔逊(Pearson)的积差相关(product-moment correlation),用r表示。r在-1.00到+1.00之间变化,相关系数为-1.00时,表示完全不相关或理想相关。皮尔逊r可取的最小值是0.00,表示两个变量之间没有关系,这时,可以得出两个证明,一是它的数值可估算出是何种关系,二是它的符号表明了方向。相关系数是一个纯数字,是取绝对值,如-0.5和+0.5是同等相关程度,而-0.6比+0.6更相关。
如何计算r值呢?有一个公式,即:
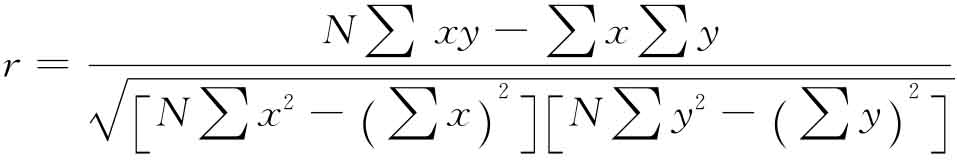
式中,x和y表示原始数值;∑是求和符号;∑xy表示x和y的积求和,即将每一变量x与它对应的变量y相乘,将结果相加。
相关r是很抽象的概念,它与原始数值的大小无关,因为r没有单位概念,只有“弱”、“中”、“强”的概念。例如0.00是无关,0.01—0.3是弱相关,0.4—0.7是中度相关,0.71—0.90是强相关,0.91—1.00之间是高度相关。相关并不表示简单的因果关系。例如,烧香拜佛可能受电影《聊斋》的影响,但看《聊斋》的人并不一定都去烧香拜佛,相关只是因果性的一个因素,它还可能与文化程度有关。
五、部分相关
部分相关是研究人员假定一个混乱的或欺骗性的变量,会影响自变量和因变量关系时使用的方法,控制混乱变数。研究人员可用部分相关统计法测定控制变量的影响,使用这种方法能使相关值相对原先研究增加。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










