



第五节 数据转化与调整
数据转化与调整就是在统计分析之前或统计分析中对数据进行加工处理,如根据统计分析的要求对数据进行分组、合并、加权、筛选等。SPSS软件中Data和Transform等菜单提供了对数据进行转化与调整的分析模块,下面对数据转化与整理过程中常用的几个命令进行简单介绍。
一、记录排序:Sort Cases过程
通过Sort Cases过程将记录按ID变量排序,有利于对数据的查找和修改。通过将某个变量按升序或降序排列,可以非常容易地发现输入错误的数据,因为它们往往是最大值或最小值,而缺失值在排序中会排在最小值的前面,因此,在数据清理时可以通过排序的方法很快发现那些有问题的或缺失的数据。
操作过程:选Data菜单的Sort Cases命令项,弹出Sort Cases对话框(见图7-6),在变量名列框中选1个需要按其数值大小排序的变量(用户也可选多个变量,系统将按变量选择的先后逐级依次排序),点击 按钮使之进入Sort by框,然后在Sort Order框中确定是按升序(Ascending,从小到大)或降序(Descending,从大到小)进行排序,点击OK按钮即可,就可以看到排序的变量按要求进行了升序或降序的排列。
按钮使之进入Sort by框,然后在Sort Order框中确定是按升序(Ascending,从小到大)或降序(Descending,从大到小)进行排序,点击OK按钮即可,就可以看到排序的变量按要求进行了升序或降序的排列。
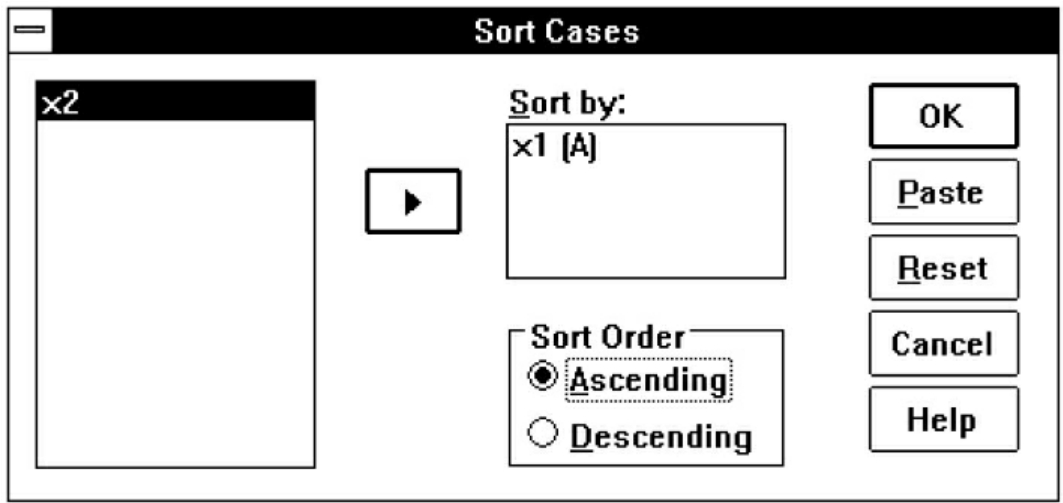
图7-6 Sort Cases对话框
二、行列转置:Transpose
这个过程用于对数据进行行列转置,即原来的一条记录转成一个变量,而Transpose过程的对话框中,左侧为候选变量框,右侧上方为Variable框,用于选入需要转置的变量,一般应选入除名称变量外的所有其他变量,如果有变量未选入,则转置时会被自动放弃;右侧下方为Name Variable框,用于指定原数据文件中记录转置后变量名的字符变量,但不是必需的,此时系统会将新变量自动按var001、var002……的顺序命名。变量则转成一个记录。可以在原数据文件中制定一个变量用于给转置后的变量命名。原变量名则自动保存在系统产生的名为case_lbl的变量中。这样如果使用得当,两次Transpose过程后数据集就会恢复原样。但是要注意,如果是字符型变量,转置后就消失了。图7-7和图7-8分别是转置前和转置后数据的情况。

图7-7 转置前

图7-8 转置后
三、数据格式转变:Restructure
如果需要根据分析要求改变数据的排列格式时,如在重复测量模型中将同一个个体的多次测量并排在一行上,或者将在一排上的几次测量结果分开,就需要Restructure过程。选择Restructure后,系统会弹出数据重排向导,在向导中提供了三种数据重排功能:将宽型数据重排成长型格式;将长型数据重排成宽型格式;数据转置,选中该项便结束向导,直接调用Transpose过程。图7-9即是Restructure过程对话框。
四、文件合并:Merge Files
社会调查中的问卷往往较多,要输入电脑的数据较多,绝大多数情况下,不可能由一个人单独完成,数据录入往往需要多个人的共同合作,但是分析的数据,不是一个个单独的数据,而是一个总的数据。那么多个人录入的数据怎么合并成一个数据呢?Merge Files提供了两种合并的方式:合并个案(Add Cases)和合并变量(Add Variables)。
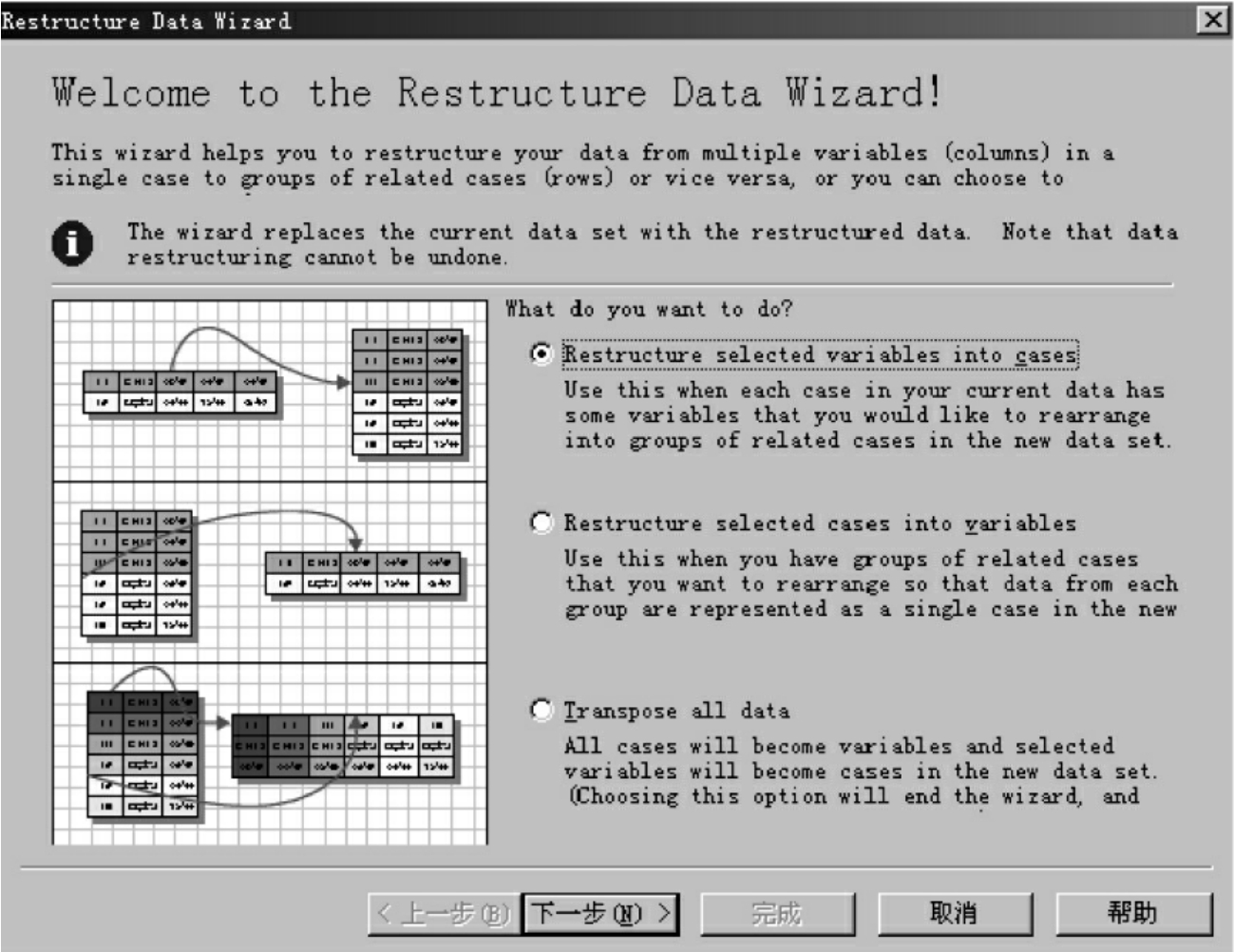
图7-9 Restructure过程对话框
(1)合并个案(Add Cases),也称纵向合并,是将外部数据文件中的记录增加到当前数据文件,在变量类型一致的情况下,操作比较简单。需要注意的是,如果要合并的两个数据是相同的变量,最好变量名相同,相同变量名的数据可以直接合并,不相同的会在当前数据文件变量后以新的变量形式出现。
操作过程:利用数据连接功能可以将两个或两个以上的具有相同变量格式的数据文件连在一起。打开其中一个需要合并的数据,如本例有两个数据文件:data1.sav和data3.sav(见图7-10)。
点击Data菜单的Merge Files命令项,选Add Cases项,弹出Add Cases: Read File对话框,找到需要合并的文件打开,进入图7-11的对话框。这个对话框中分别列出了两个要合并文件中的变量名,“*”表示当前工作文件的变量,“+”表示要合并文件的变量,从图7-11中可以看出,新生成的数据包括name、x1和x2三个变量,点击OK按钮进行合并。合并后的数据见图7-12。
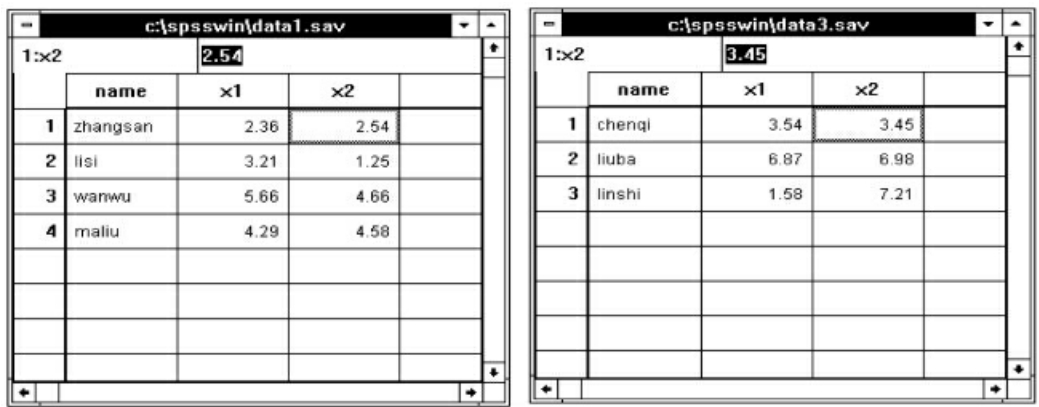
图7-10 待合并的数据
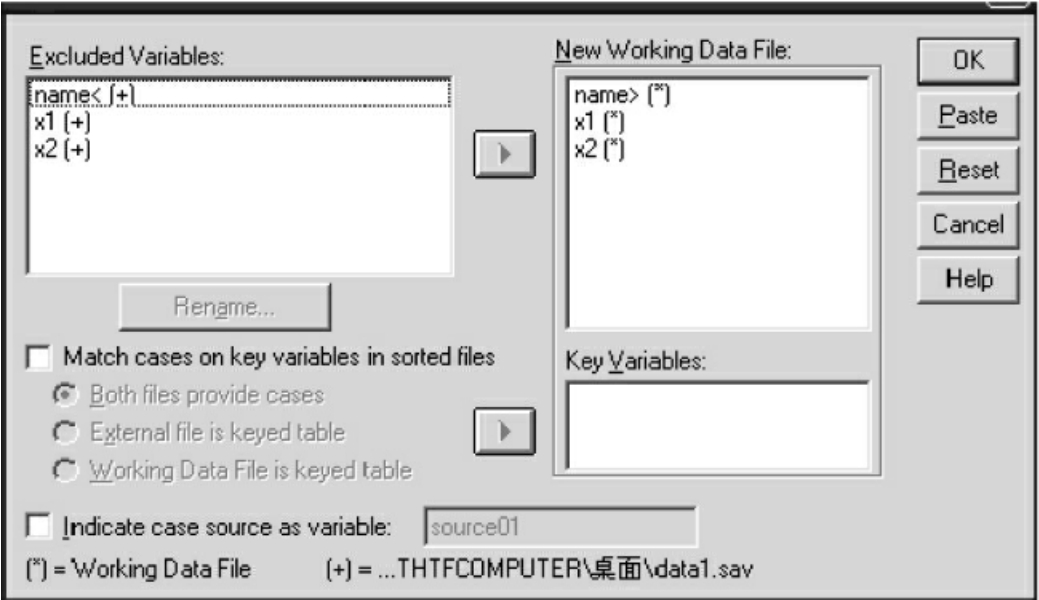
图7-11 合并个案对话框
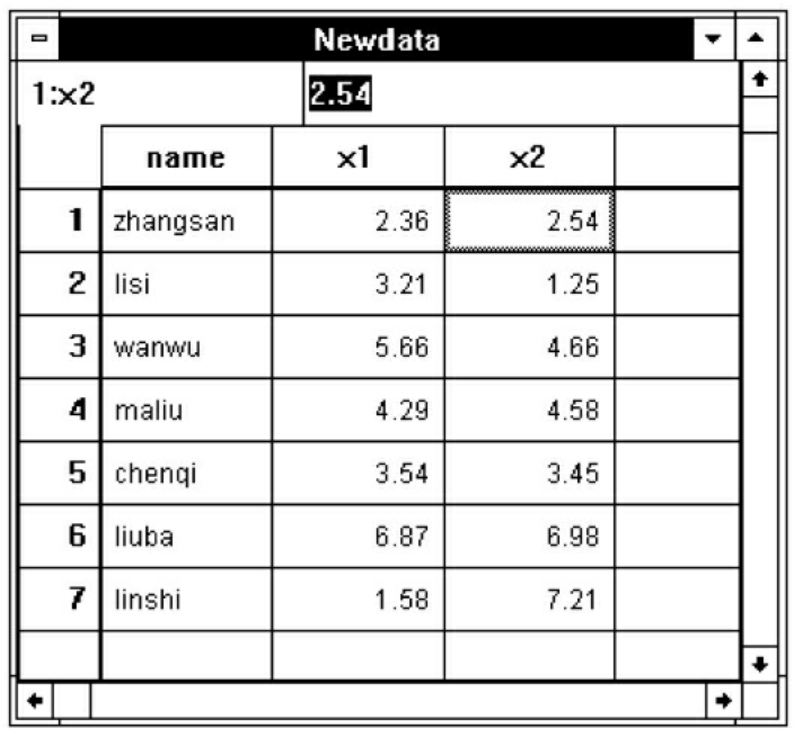
图7-12 合并后的数据图
(2)合并变量(Add Variables):默认是按照记录顺序对应起来合并,由于在许多情况下是需要按照某个ID变量取值相同的原则进行对应和合并,此时就存在是否正确对应的问题,需要加以注意。因此在合并变量时,要求要合并的数据文件中要有一个相同的变量名,一般来说是问卷的编号,以防合并的数据张冠李戴。
操作过程:利用数据连接功能还可以将两个或两个以上的具有相同观察单位的数据文件连在一起,如本例有两个数据文件:data1.sav和data2.sav(见图7-13)。
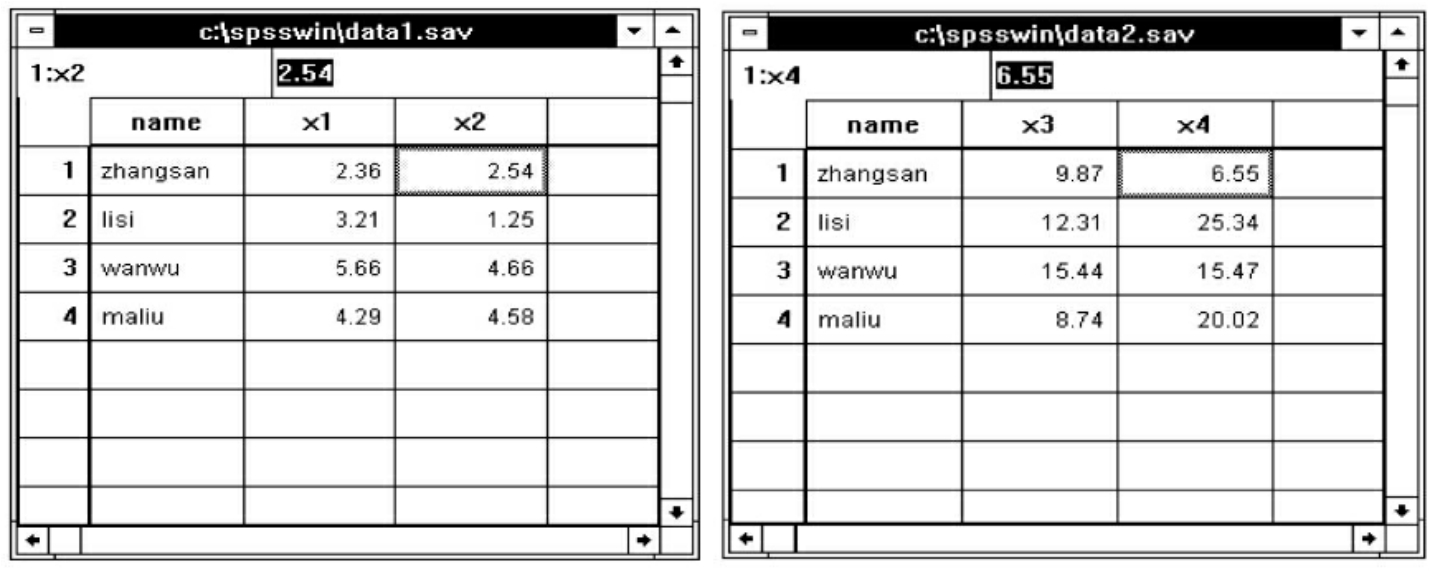
图7-13 待合并的数据
点击Data菜单的Merge Files命令项,选Add Variables项,弹出Add Variables:Read File,点击要合并的文件,出现如图7-14的对话框。这个对话框中分别列出了两个要合并文件中的变量名,“*”表示当前工作文件的变量,从图7-14中可以看出,新生成的数据文件包括name、x1、x2、x3、x4五个变量,点击OK按钮进行合并。合并后的数据见图7-15。
五、数据汇总:Aggregate过程
当需要将原数据文件分类汇总为一个新的汇总数据文件时,可以采用Aggregate命令。如果只是希望进行汇总描述,则有相应的统计分析功能可以完成,不需要使用本过程。
操作过程:首先,要指定分类变量(Break Variable)和汇总变量(Aggregate Variable);然后,SPSS自动根据分类变量的取值将记录数据分成若干类,并对每类记录分别计算汇总变量的描述统计变量;最后,将分类汇总的计算结果保存到一个SPSS数据文件中。
如要对图7-16中的数据按变量group的大小,把变量x1作平均值汇总,把变量x2作求和汇总。
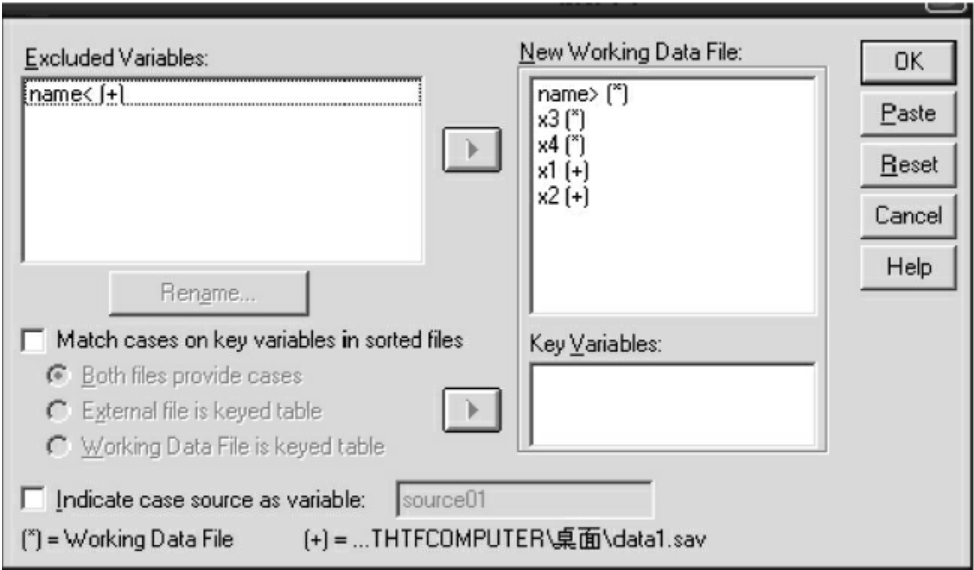
图7-14 合并变量对话框
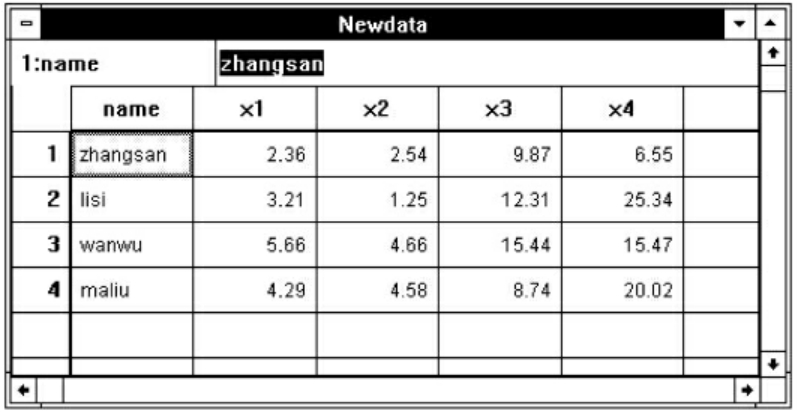
图7-15 合并后的数据
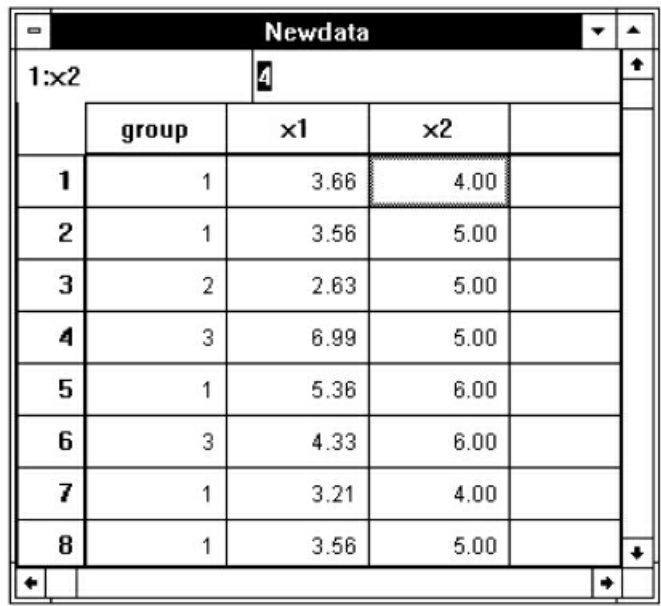
图7-16 Aggregate过程之一
可以先选Data菜单的Aggregate命令项,弹出Aggregate Data对话框,在变量名列框中选group变量,点击 按钮使之进入Break Variable框,选x1变量进入Aggregate Variable框。因x1欲作平均值汇总,故点击Function按钮,弹出Aggregate Data:Aggregate Function对话框,选Mean of values项后,点击Continue按钮返回(见图7-17);选x2变量进入Aggregate Variable框,因x2变量欲作求和汇总,故点击Function按钮,选择Sum of values项,点击Continue按钮返回(见图7-18)。再点击OK按钮即可得到图7-19的结果。
按钮使之进入Break Variable框,选x1变量进入Aggregate Variable框。因x1欲作平均值汇总,故点击Function按钮,弹出Aggregate Data:Aggregate Function对话框,选Mean of values项后,点击Continue按钮返回(见图7-17);选x2变量进入Aggregate Variable框,因x2变量欲作求和汇总,故点击Function按钮,选择Sum of values项,点击Continue按钮返回(见图7-18)。再点击OK按钮即可得到图7-19的结果。
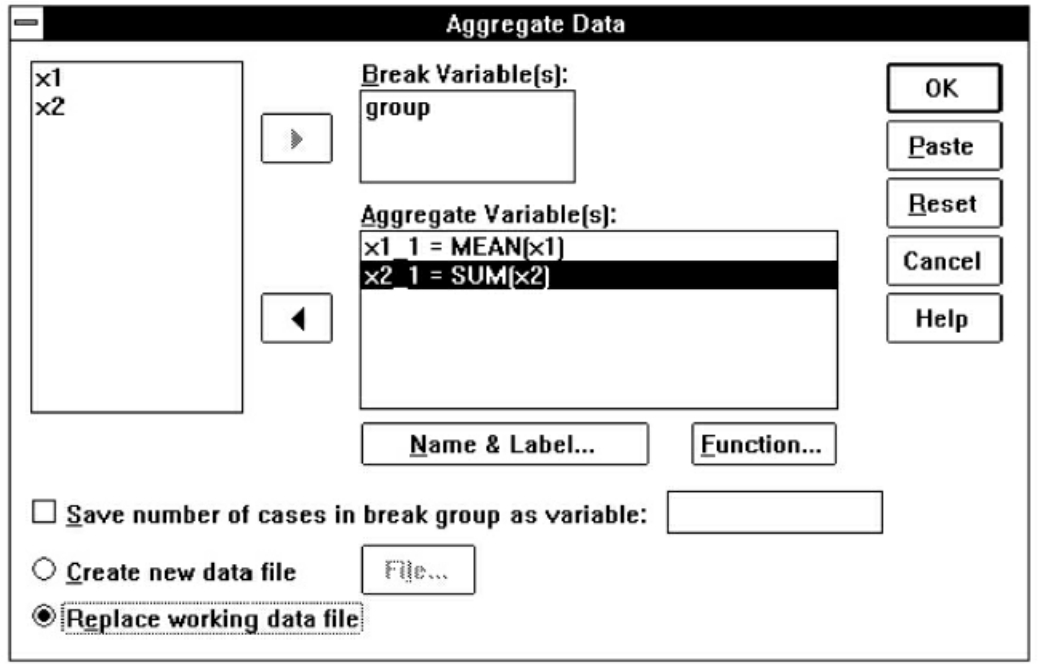
图7-17 Aggregate过程之二
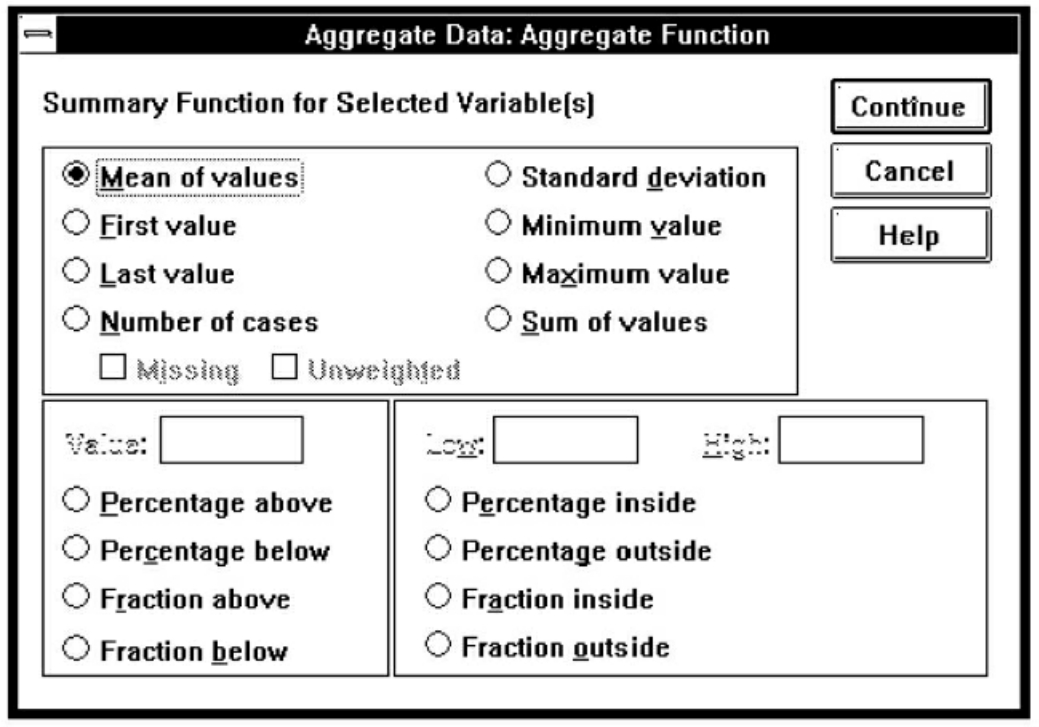
图7-18 Aggregate过程之三
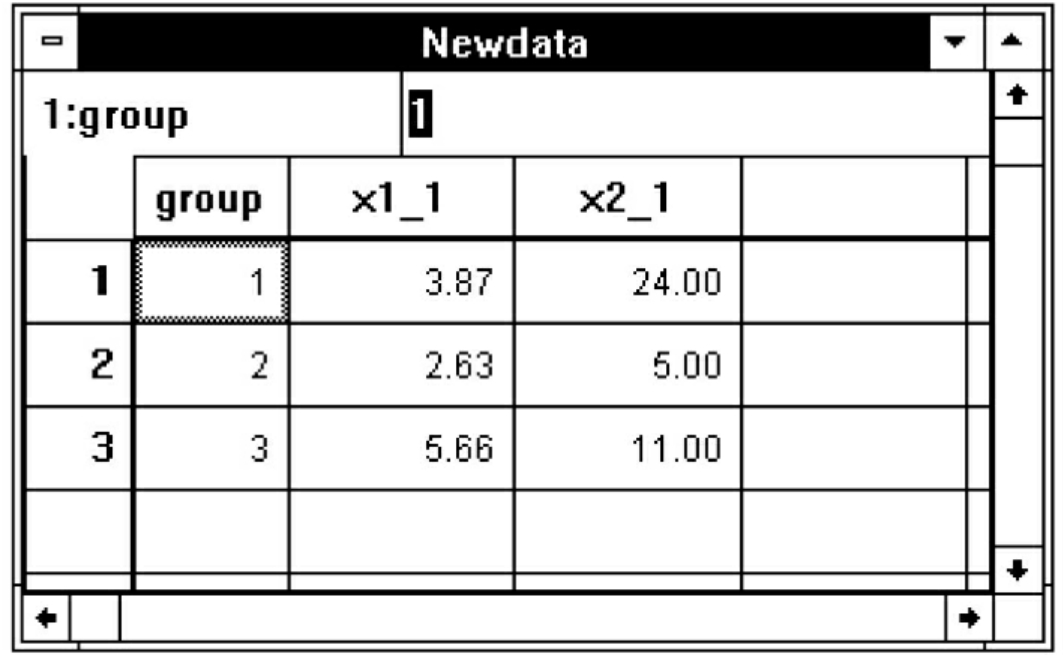
图7-19 Aggregate过程之四
六、记录拆分:Split File过程
在进行统计分析时,不仅需要对数据进行合并,有时根据分析的需要,特别是对具有不同特征的数据进行分析时,就需要将数据文件分组进行处理。分析的过程中默认的是不对数据进行拆分,统计的是所有样本数据。在拆分分析中,有三种分析的形式:
(1)Analyze all cases:不拆分文件。
(2)Compare groups:按所选变量拆分文件,各组分析结果紧挨在一起便于比较。
(3)Organize output by groups:按所选变量拆分文件、各组分析结果单独放置。
操作过程:选Data菜单的Split File命令项,弹出Split File对话框,见图7-20,选Repeat analysis for each group表示此后都按指定的分组方式作相同项目的分析,用户可从变量名列框中选1个或多个变量点击 按钮使之进入Groups Based on对话框,以此变量作为分组依据。统计分析的结果将根据分组变量分组进行分析。若在数据分割之后要取消这种分组,可选Analyze all cases项,则系统恢复如初。
按钮使之进入Groups Based on对话框,以此变量作为分组依据。统计分析的结果将根据分组变量分组进行分析。若在数据分割之后要取消这种分组,可选Analyze all cases项,则系统恢复如初。
七、记录筛选:Select Cases过程
在数据分析的过程中,有时需要对符合要求的一部分数据进行统计分析,这时就需要从众多的数据中选择出符合要求的数据,所用的是Select Cases过程。
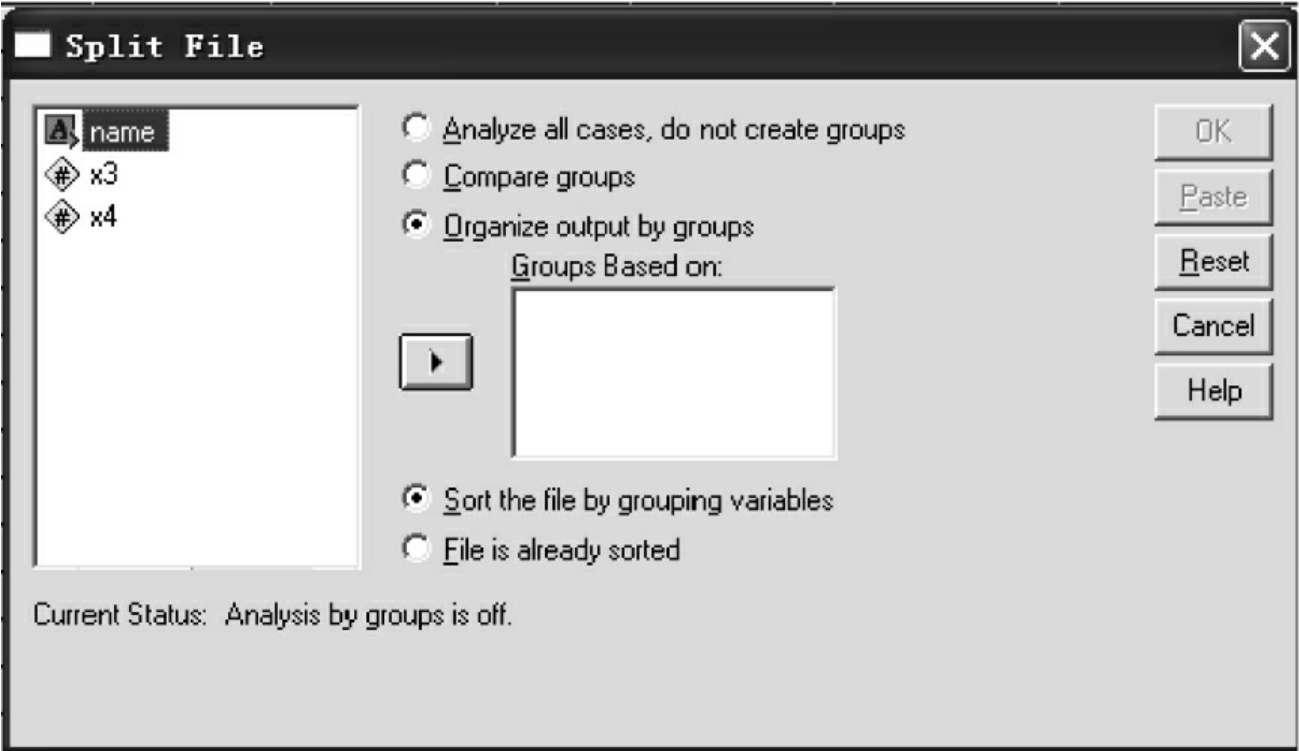
图7-20 Split File窗口
操作过程:选Data菜单的Select Cases命令项,弹出Select Cases对话框,见图7-21。
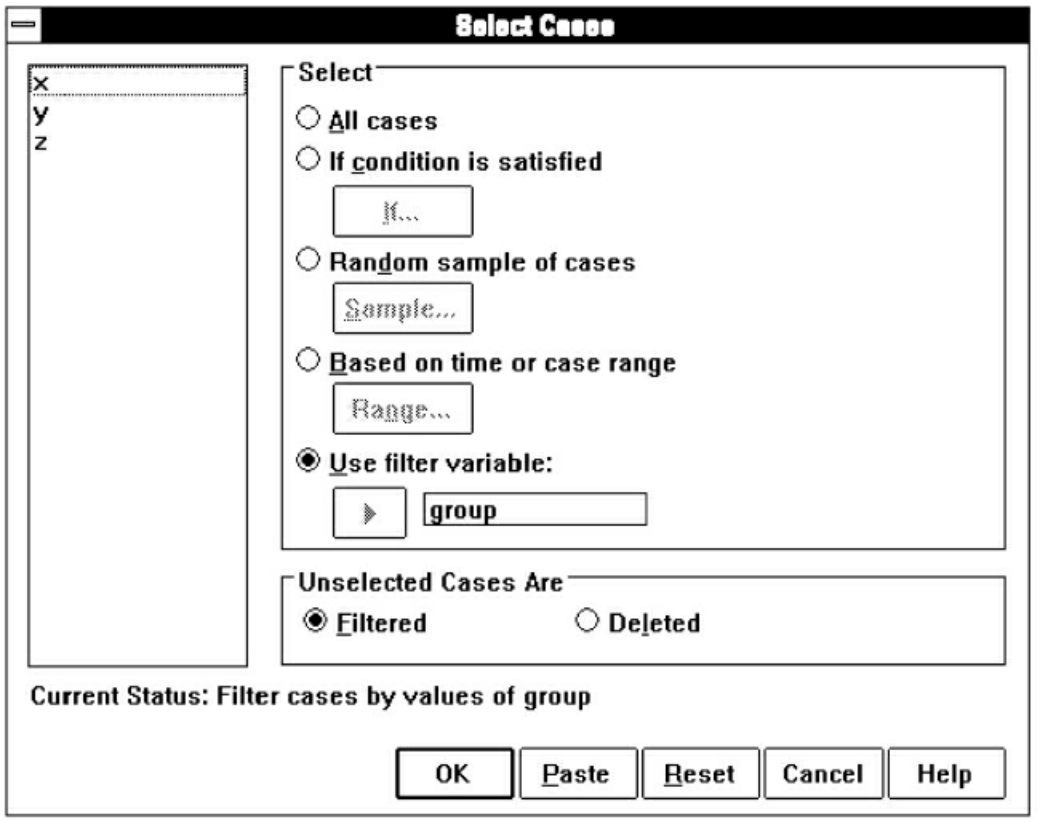
图7-21 Select Cases对话框
其中,(1)All cases:表示所有的个案数都被选择,这是系统默认选项。
(2)If condition is satisfied:表示按指定条件选择,点击If按钮,弹出Select Cases:If对话框,见图7-22,先选择变量,然后定义条件。
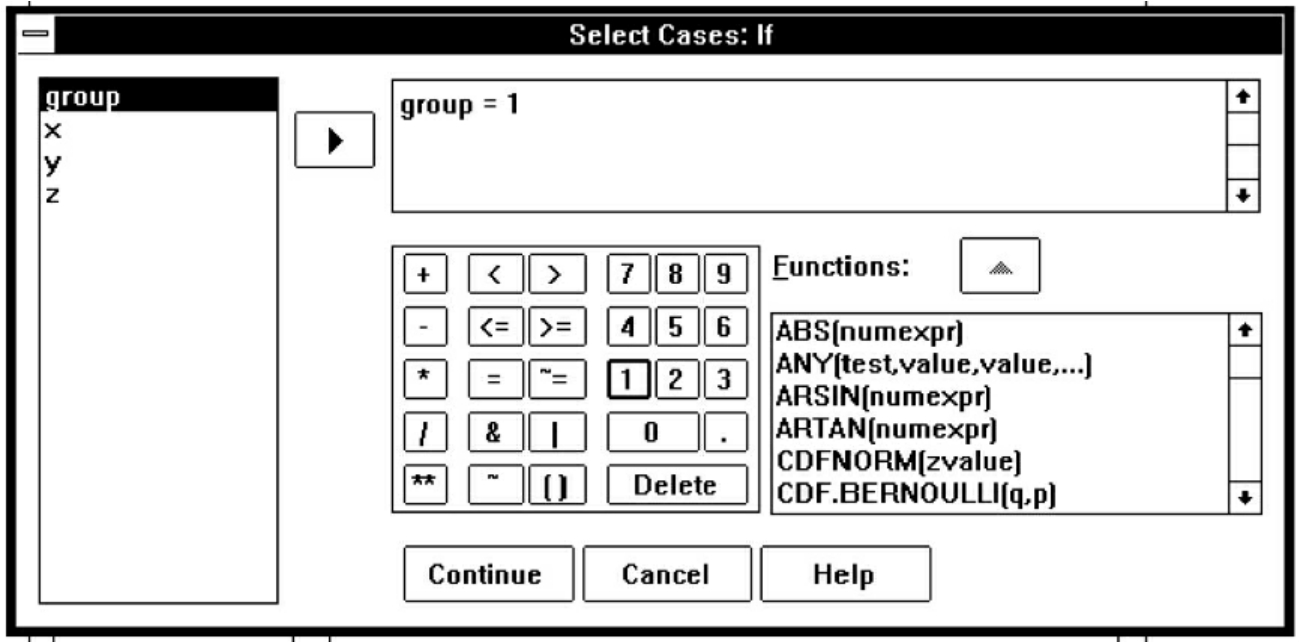
图7-22 Select Cases:If窗口
(3)Random sample of cases:表示对观察单位进行随机抽样,点击Sample按钮,弹出Select Cases:Random Sample对话框,有两种选择分式:一种是大概抽样(Approximately)即键入抽样比例后由系统按比例随机抽取,另一种是精确抽样(Exactly)即要求从第几个观察值起抽取多少个。
(4)Based on time or case range:表示顺序抽样,点击Range按钮,弹出Select Cases:Range对话框,用户定义从第几个观察值抽到第几个观察值。
(5)Use filter variable:表示用指定的变量作过滤,用户先选择1个变量,系统自动在数据管理器中将该变量值为0的观察单位标上删除标记,系统对有删除标记的观察单位不作分析。若用户在Select Cases对话框的Unselected Cases Are框中选Deleted项,则系统将删除所有被标上删除标记的观察单位。
(6)调用Select Cases命令完成定义后,SPSS将在主窗口的最下面状态行中显示Filter On字样;若调用该命令后的数据库被用户存盘,则当这个数据文件再次打开使用时,仍会显示Filter On字样,意味着数据选择命令依然有效。
八、记录加权:Weight Cases过程
当在数据文件中如果存在一个表明相同变量出现频数的变量时,应该定义该变量为权重变量。也只有先进行加权设定,统计软件才能正确识别和处理数据。
操作过程:选Data菜单的Weight Cases命令项,可对指定的数值变量进行加权。在弹出的Weight Cases对话框中(见图7-23):
(1)Do not weight cases:表示不做加权,也可用于对做过加权的变量取消加权。
(2)Weight cases by:根据选择的变量进行加权,图7-23中表示选择1个变量做加权。
在加权操作中,系统只对数值变量进行有效加权,即大于0的数按变量的实际值加权,0、负数和缺失值加权为0。

图7-23 Weight Cases对话框
九、Data菜单中的其他命令
除了上述常用的Data菜单中的命令之外,Data菜单中还有以下常用的简单命令,在数据处理可选择适用的命令。
(1)Define Dates:用于自动生成时间变量,主要用于时间序列模型。
(2)Insert Variable:在当前列自动插入新变量。
(3)Insert Cases:在当前行自动插入新记录。
(4)Goto Cases:到达指定记录号的记录,在奇异值的查找中,也可以采用这一命令。点击要查找的数据所在的变量,将需要查找的数据结果输入对话框(见图7-24),系统会自动地找到要查找的结果,将其进行修改。该命令在记录数极多时(1000条以上)非常有用。
十、生成新变量:Compute
除了Data菜单中的对数据进行转换和整理的功能外,Transform菜单下的Compute命令(生成新变量)和Record(变量值的重新编码)也是常用的数据整理的命令。
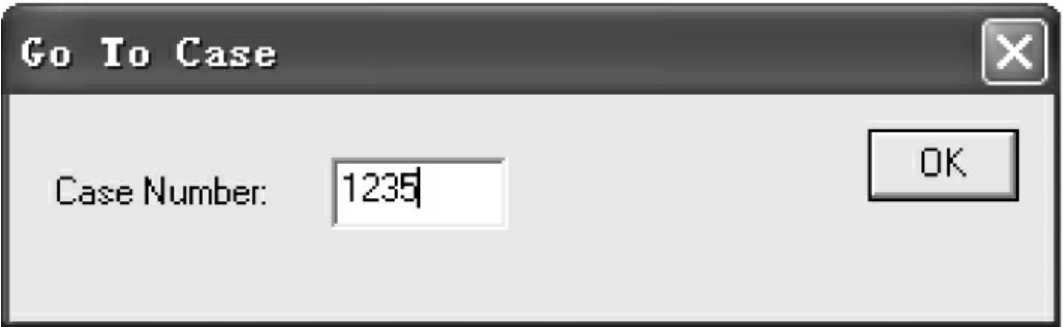
图7-24 查找对话框
Compute是根据现在的变量生成一个新的变量。具体的操作过程如下:选Transform菜单的Compute命令项,弹出Compute Variables对话框,见图7-25。将要生成的变量名写在Target Variables窗口,根据计算的条件将其放入Numeric Expression窗口,点击OK按钮,即在数据的最后生成一个新的变量。
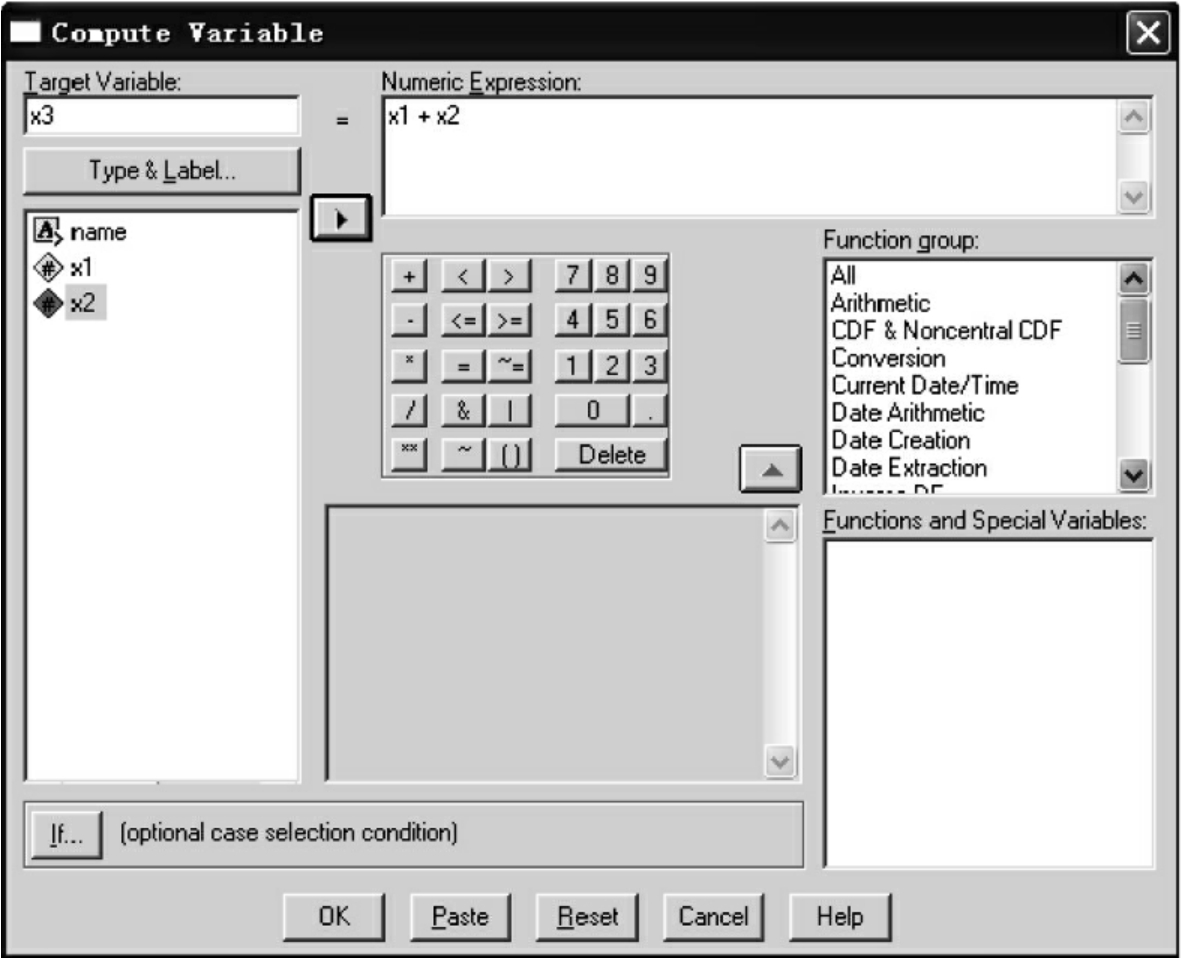
图7-25 Compute对话框
十一、对变量值重新编码:Record
在统计分析时,除了对变量进行转化外,有时也需要对变量的取值进行重新转化,也就是重新编码,如将原来的收入数据分成几组,形成顺序变量,这时变量的取值也从原来的具体收入数值变成了每一组的代码,如“1、2、3、4”等。Record命令提供了对变量进行重新编码的过程。
具体的操作过程如下:选Transform菜单的Record命令项,包括两种变量值重新编码的形式:
(1)Into same variables:覆盖掉原来的变量。
(2)Into different variables:重新生成新的变量。
点击Into same variables和Into different variables,分别生成如图7-26和图7-27的对话框。
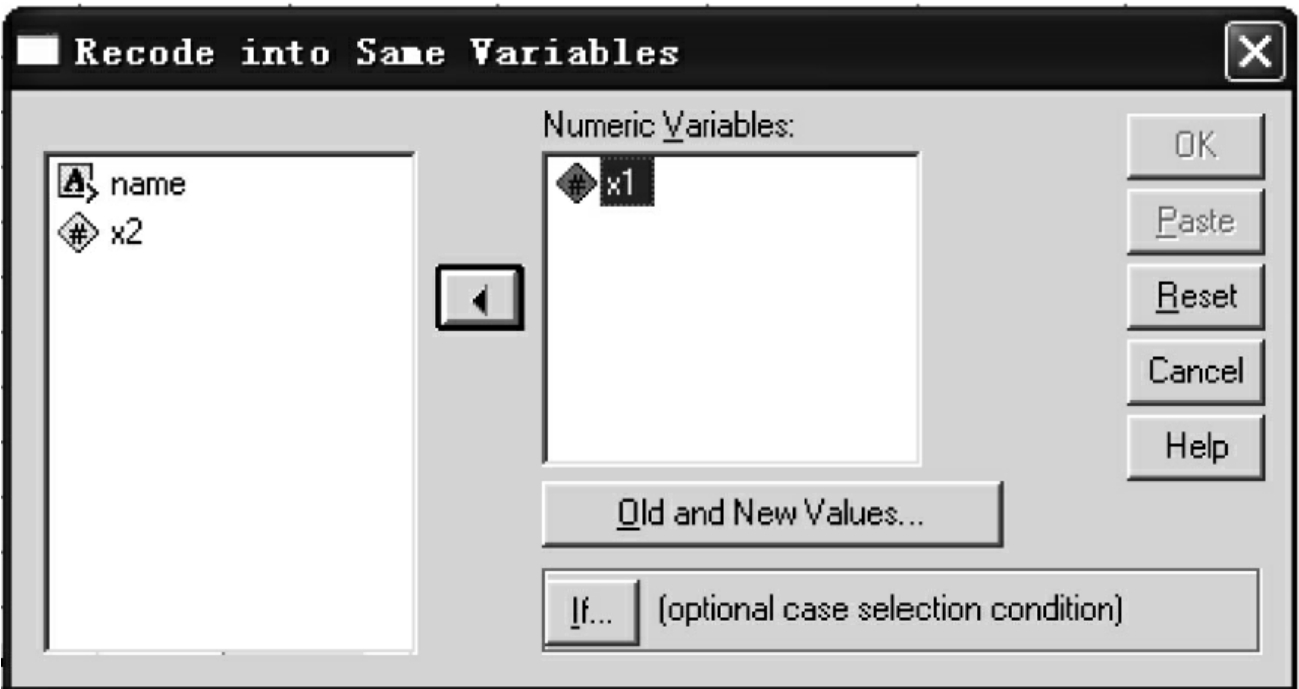
图7-26 Into same variables对话框
点击Old and New Values对变量取值进行重新设置,见图7-28。左侧Old Value表示的是变量原来的取值,New Value指的是变量要重新设置的代码。系统默认是对所有的数值都进行变量取值的转化,如果只想对其中一部分数据进行转化,可以点击图7-26和图7-27中的If按钮进行设置,设置方式同Select Cases中的If condition is satisfied选项。
本章小结
当运用各种方法收集到一批数据资料后,接下来就是对这些资料进行量化处理,以便于统计分析。
资料的审核是资料处理的第一步工作,它指研究者对调查所回收的原始资料(主要是问卷)进行初步的审查和核实,校正错填、误填,剔除乱填、空白和严重缺答的废卷,使资料具有较好的准确性、完整性和真实性。
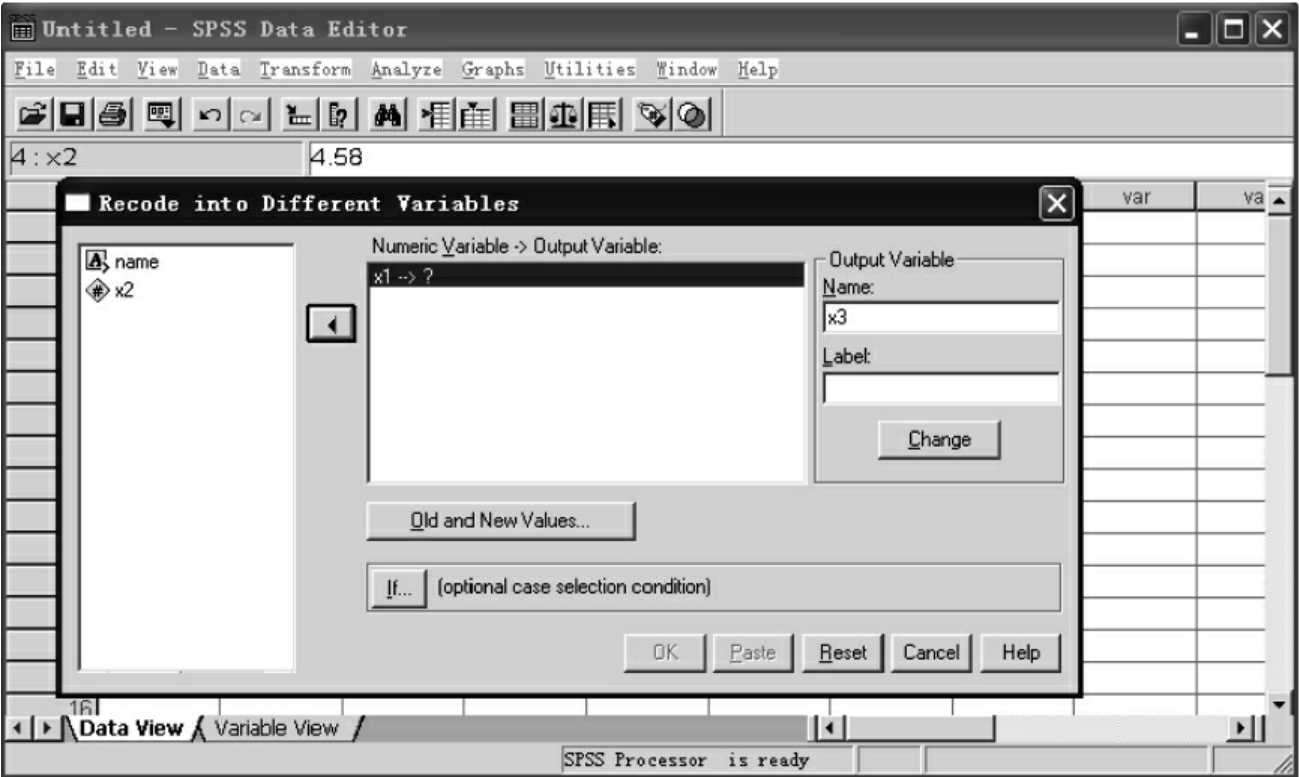
图7-27 Into different variables对话框
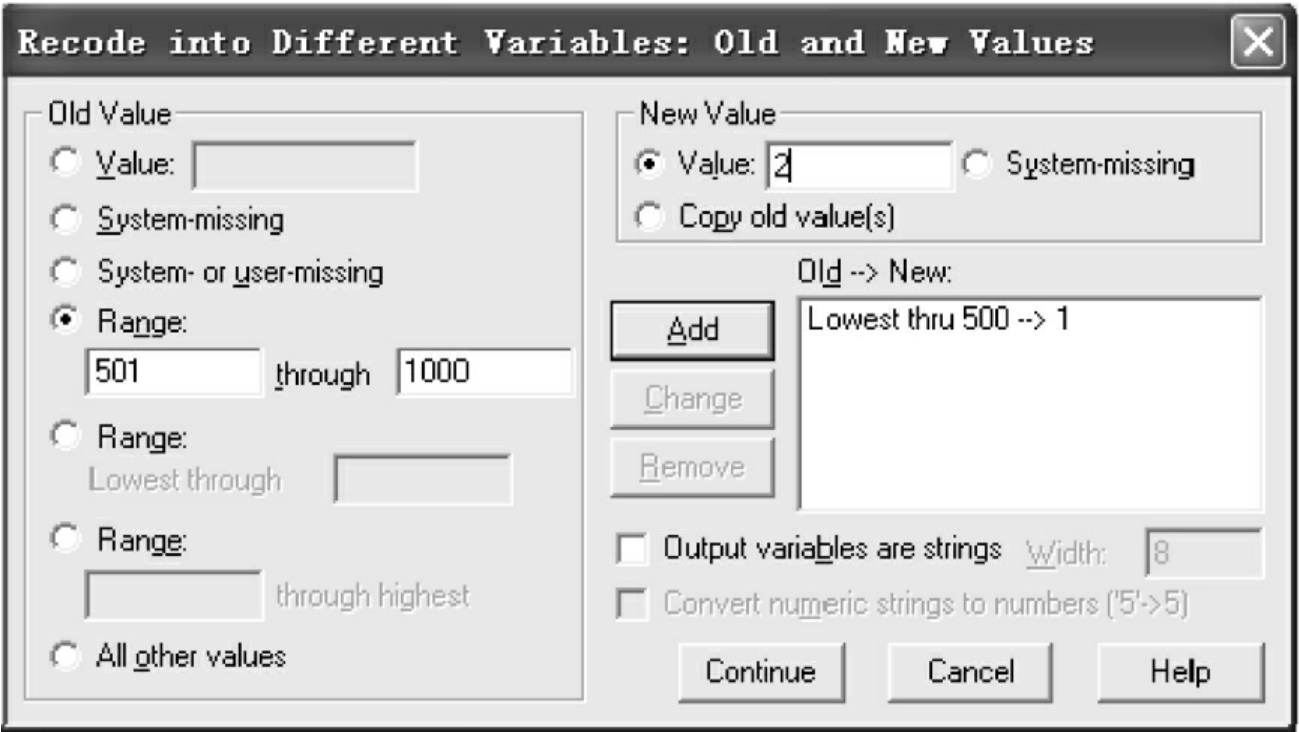
图7-28 变量值转化对话框
资料审核之后就需要对数据进行编码,编码就是给每个问题及答案一个数字作为它的代码,将问卷中的文字转化成数字的过程。编码也是数据整理汇总阶段重要而基本的环节。
当然,当问卷审核完毕,编码完成之后,需要由相应的专业统计软件来进行统计,社会学研究中常用的是SPSS软件。SPSS for Windows是一个组合式软件包,它集数据整理、分析功能于一身。SPSS软件的基本功能包括数据管理、统计分析、图表分析、输出管理,等等。打开SPSS软件后,需要对已编码的数据进行录入。数据录入的方式有两种:一种是直接从问卷上将编好码的数据录入计算机;另一种是先将问卷上编好码的数据转录到登录表上,然后再从登录表上将数据输入计算机。不管怎样,在录入数据前都需要建立数据库。
在进行正式的统计工作之前还有一步重要的工作,就是数据的清理。数据清理工作其目的是不让有错误的数据进入运算过程。数据清理工作一般在计算机的帮助下完成。数据的清理主要是数据有效范围清理和逻辑一致性清理,但有些数据无法通过数据有效范围清理和逻辑一致性清理出来,因此还需要对数据的质量进行抽查,对数据进行评价。
数据转化与调整就是在统计分析之前或统计分析中对数据进行加工处理,如根据统计分析的要求对数据进行分组、合并、加权、筛选等。SPSS软件中Data和Transform等菜单提供了对数据进行转化与调整的分析模块,通过转化和调整使数据更有利于统计分析。
关键术语
量化处理 数据审核 数据编码 SPSS统计软件 数据录入 数据清理 数据评价 数据转化 数据调整
思考题
1.数据审核的方式有哪些?各有什么特点?
2.数据编码的必要性有哪些?怎么进行数据编码?
3.数据录入的方式有哪两种?结合实际谈谈哪种方式更好?
4.数据转化和调整的方式有哪些?利用手中的数据熟练应用这些数据转化与调整的方式。
【注释】
[1]乐章.现行制度安排下农民的社会养老保险参与意向.中国人口科学,2004(5).
[2]风笑天.社会学研究方法.北京:中国人民大学出版社,2005:273.
[3]袁方.社会研究方法教程.北京:北京大学出版社,1997:434.
[4]郝大海.社会调查研究方法.北京:中国人民大学出版社,2005:207.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










