



5.3 RST转换模型
基于粗糙集的兼容转换模型(简称“RST”模型),是一种基于统计的相似度度量方法,其前提条件是必须建立并行文献数据库。根据粗糙集基本理论,一个文献数据库可看作一个知识库,其属性就是索引词,对象就是文献。如果一个索引词用来标引一篇文献,其属性值被定义为1,否则为0。因此,每个属性(等价关系)将数据库的所有文献分为两类:类x为所有属性为1的文献,类y为所有属性值为0的文献。在这种情况下,r(Q)可以简化为公式50,r(X)简化为公式51和公式52,其中Px和Qx分别为词汇P和Q在语料库中的出现频率。
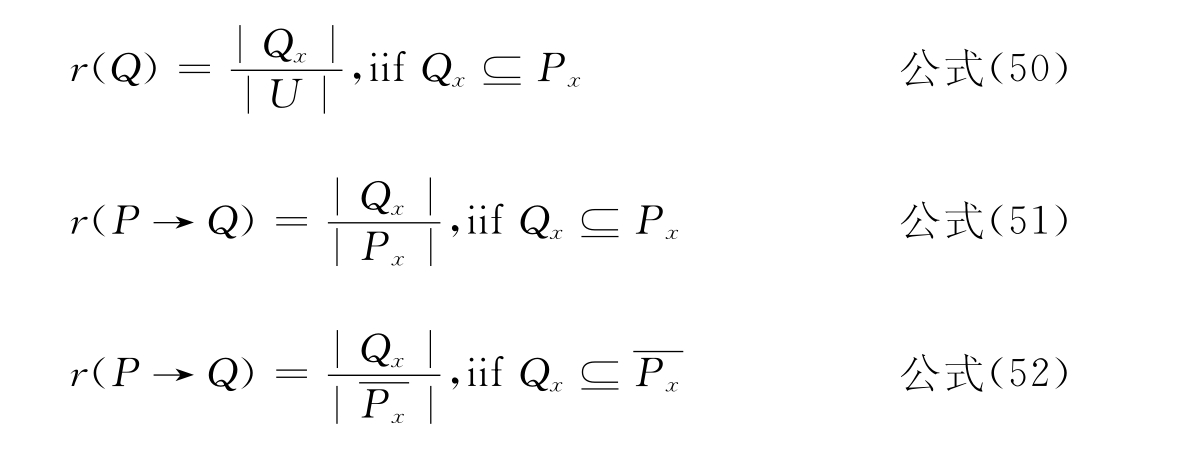
|Px|通常远远大于|Qx|,公式7近似等于零。P和Q的语义关系可以定义为:
●当Px=Qx,r(P→Q)定义“等同关系”(exact equiva-lence);
●当,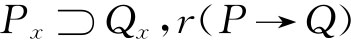 定义“狭义关系”(narrower equiva-lence);
定义“狭义关系”(narrower equiva-lence);
●当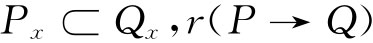 定义“广义关系”(broader equiva-lence);
定义“广义关系”(broader equiva-lence);
毫无疑问,当P和Q为同一数据库的标引词时,上述定义是有效的。当P和Q分别来自两个并行文献数据库时,r(Q)和r(X)则不一定有效。通常情况下,两个并行文献数据库并不是两个等价数据库。
标引深度(exhaustivity)和标引专指度(specificity)是反映一个检索语言特征的重要指标。标引长度定义为一篇文献的标引词数量。标引长度在一定程度上反映了数据库文献的标引深度和标引专指度。如果两个并行文献数据库的标引长度完全相同,我们则称这两个数据库等价,反之则不等价。
如果A和B为两个分别用A′和B′进行标引的并行文献数据库。当进行A和B两个文献数据库的概念集成时,也就是建立语言A′向语言B′的概念兼容转换关系(transfer relations),系数α定为:

假设,C1为标引词P在文献数据库A中的出现频率,C2为标引词Q在文献数据库B中的出现频率,C3为标引词P和Q在两个数据库中共同出现的频率。
根据α的值,RST模型定义分类下面三种情况:
(1)α=1
●当C1≥C2,且C3=C2时
![]()
●当C1<C2,且C3=C1时
![]()
●当C1>C3,且C1>C2>C3时
![]()
(2)α>1
●当C1×α≥C2,且C3×α≥C2时
![]()
●当C1×α<C2,且C3=C1时
![]()
●当(C3×α<C2,且C1×α≥C2),或者(C1×α<C2,且C3≠C1)时
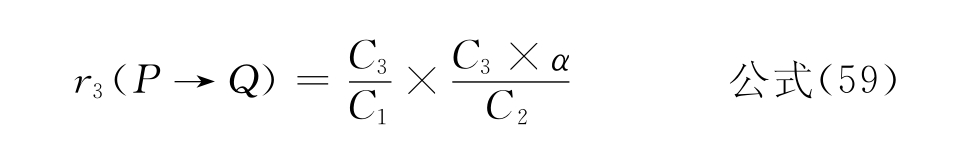
(3)α<1
●当C3=C2,且C1×α≥C2时
![]()
●当C1×α<C2,且C3≥C1
![]()
●当(C3≠C2,且C1×α≥C2)或者(C1×α<C2,且C3<C1×α)
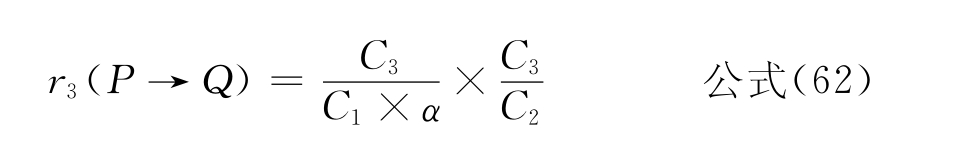
因此,标引词P和Q的语义关系分别定义如下:
●r1(P→Q)定义“等同关系”或者“狭义关系”;
●r2(P→Q)定义“广义等同关系”;
●r3(P→Q)定义“部分等同关系”。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










